Como implementar uma render farm GPU dedicada de 20 nós transfronteiriça (2026)
Visão geral
Introdução
Quando uma equipa criativa pede uma render farm dedicada que atravessa vários países, está quase sempre a contornar uma restrição que uma render farm SaaS não consegue resolver. Pode tratar-se de um estúdio que contratualmente não pode permitir que terceiros detenham as suas credenciais, uma equipa distribuída cujos artistas num país operam nós noutro, ou uma casa de produção cujo compromisso plurimensal torna economicamente inadequada a faturação por frame.
Na nossa experiência ao implementar clusters dedicados, o problema difícil raramente é "alugar mais GPUs". É conectar as peças certas: armazenamento na nuvem pertencente ao cliente, uma frota GPU privada dimensionada para a carga, transporte transfronteiriço cifrado que aguente jitter, e uma camada de ambiente de trabalho remoto que não colapse ao abrir um viewport 3D pesado. Quando uma peça está errada, o cluster funciona, mas os artistas notam — e o compromisso degrada-se silenciosamente.
Operamos a Super Renders Farm, uma render farm na nuvem com frota CPU e GPU substancial, e montamos também clusters GPU dedicados para equipas cujos workflows não se enquadram no nosso serviço gerido. Este artigo é um guia prático derivado dessas implementações — como arquitetamos uma render farm GPU dedicada de 20 nós que serve uma equipa criativa distribuída de artistas além-fronteiras, a partir de uma única instalação dedicada, com notas honestas sobre as escolhas feitas, as que revertemos e as lições que aplicamos por defeito. Ao avaliar infraestrutura dedicada face ao nosso aluguer de render farm gerida, este guia ajuda a decidir se o caminho dedicado vale a superfície arquitetónica adicional.
Critérios de decisão: dedicado vs. SaaS
A maioria das cargas de renderização não precisa de um cluster dedicado. Uma render farm na nuvem gerida recebe uma cena, agenda os frames e fatura ao minuto. Não há infraestrutura a gerir, firewall a manter, nem equipa operacional a alocar do lado do cliente. Para trabalho com base em projeto — uma curta-metragem, um anúncio de 30 segundos, um lote de stills — esse modelo ganha em todos os eixos relevantes.
Um cluster dedicado só justifica a sua complexidade quando um ou mais dos seguintes critérios se verificam:
- O controlo da propriedade intelectual é contratual, não preferencial. O contrato de serviço principal do cliente ou o contrato com o cliente final proíbe que terceiros detenham ficheiros de cena ou credenciais de renderização. As pipelines SaaS que medeiam o upload de cena violam esta restrição, mesmo que a capacidade de cálculo subjacente seja idêntica.
- O compromisso dura meses, não dias. Trabalho de forma fixa — uma série animada de longa duração, uma pipeline archviz pluri-trimestral, um palco de produção virtual contínuo — amortiza o custo arquitetónico inicial. A faturação por frame, por contraste, multiplica-se linearmente com a duração e deixa de ser competitiva a partir de determinado horizonte temporal.
- O workflow é suficientemente personalizado para que uma pipeline gerida não o possa alojar. Stacks personalizadas de plugins DCC, render managers internos, pipelines pesadas em simulação que pré-calculam para uma cache partilhada, ou cadeias de ferramentas proprietárias, tudo empurra para nós dedicados que o cliente pode configurar diretamente.
- Bring-your-own-cloud é um requisito rígido. Quando os assets do projeto do cliente vivem numa plataforma de cloud file-streaming sob a conta do cliente, o cluster tem de iniciar sessão como o cliente, não como o fornecedor de infraestrutura. Este é o padrão "Modelo B" descrito em detalhe mais adiante.
- As necessidades de segmentação de rede vão além da VLAN por tenant. Alguns workflows exigem que o cluster seja invisível à rede mais ampla do fornecedor — não apenas isolado logicamente, mas também por rota.
Se nenhum destes critérios se aplica, uma render farm gerida é quase certamente a escolha correta. Se dois ou mais se aplicam, a conversa desloca-se para o dedicado. A questão restante é geográfica: os artistas que conduzem o trabalho estão próximos da instalação, ou o cluster precisa de os servir através de um backbone ISP público que cruza fronteiras nacionais?
Visão geral da arquitetura
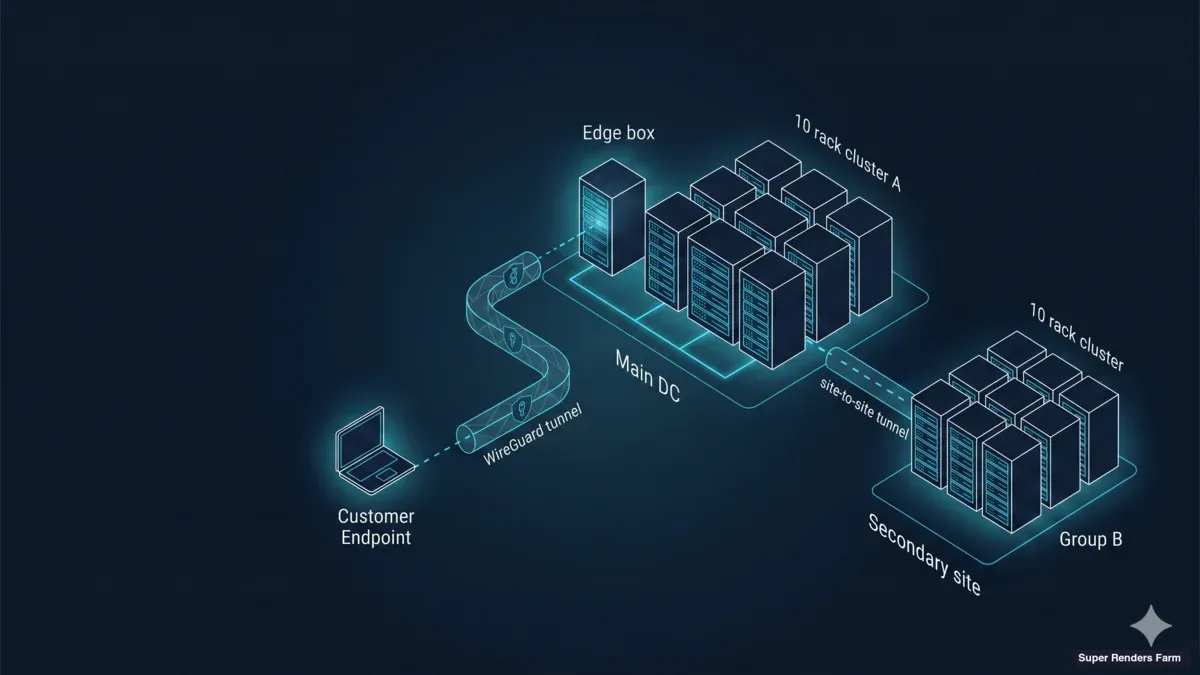
A arquitetura que implementamos para clusters dedicados transfronteiriços tem três planos: um plano de transporte, um plano de computação e um plano de aceleração de armazenamento. Cada plano tem um único modo de falha que, na nossa experiência, é responsável pela maior parte da dor operacional quando colapsa.
[ Artistas remotos — distribuídos por vários países ]
│
│ WireGuard hub-and-spoke
│ (UDP 51820, cifrado fim-a-fim,
│ transporte BBR + clamping MSS)
▼
┌─────────────────────────────────────────────────────┐
│ Super Renders Farm — instalação de cluster dedicado │
│ │
│ ┌─────────────────────────────────────────────┐ │
│ │ EDGE + CACHE BOX (único host Ubuntu) │ │
│ │ • WireGuard hub (NAT/MASQUERADE) │ │
│ │ • Cache Samba SMB3 (SSD único, ext4) │ │
│ │ • dnsmasq (zona .lan) │ │
│ │ • chrony (NTP) │ │
│ │ • ufw + BBR + clamping TCP MSS │ │
│ └────────────────────┬────────────────────────┘ │
│ │ LAN │
│ ┌────────────────────▼────────────────────────┐ │
│ │ 20 × nós de renderização RTX 5090 │ │
│ │ (Windows 11 Pro, Sunshine, cliente de │ │
│ │ cloud file-streaming, montagem de cache — │ │
│ │ imagem uniforme em toda a frota) │ │
│ └─────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
│
▼
[ Plataforma de cloud file-streaming do cliente —
o cliente inicia sessão em cada nó; a Super Renders Farm
não detém credenciais (Modelo B) ]
O plano de transporte é o WireGuard, num padrão hub-and-spoke. A estação de trabalho de cada artista liga-se ao hub na instalação do cluster através de um túnel UDP cifrado; todo o tráfego entre o artista e o cluster, independentemente do país onde o artista se encontra, atravessa a mesma topologia de túnel. O plano de computação são vinte nós Windows 11 Pro, cada um com uma NVIDIA RTX 5090 com 32 GB de VRAM, implementados como pool uniforme único numa única instalação. O plano de aceleração de armazenamento é uma única caixa de edge-e-cache na instalação que aloja uma partilha Samba SMB3 suportada por um único SSD em ext4 — juntamente com os serviços de rede de que o cluster depende (DNS, NTP, firewall).
Uma decisão de design fundamental: a caixa edge e a caixa de cache são a mesma máquina. Uma versão anterior desta arquitetura colocava o gateway edge num appliance separado e a cache numa NAS, o que criava condições de corrida durante cold pulls e duas superfícies para aplicar patches. A consolidação num único host Ubuntu 22.04 LTS eliminou ambos os problemas. A caixa torna-se um recurso crítico — mas os dados do projeto do cliente continuam a residir na plataforma de cloud file-streaming, pelo que a cache volta a aquecer a partir do upstream após qualquer falha local.
Configuração do cluster GPU de 20 nós
O dimensionamento padrão para as implementações aqui descritas são vinte nós RTX 5090, implementados como pool uniforme único numa única instalação. É este o tamanho que mapeia consistentemente bem para uma equipa criativa na faixa dos dez a vinte artistas, que é a faixa onde os clusters dedicados se justificam para workflows sensíveis à propriedade intelectual.
Cada nó tem a mesma forma de hardware: uma RTX 5090 com 32 GB de VRAM, uma CPU multi-core moderna, 64 GB ou 128 GB de RAM de sistema, e um disco NVMe local dimensionado apenas para SO e scratch. Os dados persistentes do projeto residem na cache partilhada ou na plataforma de cloud file-streaming do upstream, nunca no próprio nó.
O sistema operativo em cada nó é o Windows 11 Pro, implementado a partir de uma imagem limpa. Deliberadamente, não pré-carregamos stacks de plugins DCC na imagem do nó. O cliente conduz a instalação das suas próprias ferramentas DCC — Cinema 4D, Redshift, Houdini, After Effects, Blender e outras — para que a imagem do nó permaneça mínima e reprodutível. Quando o compromisso termina, limpamos e reimagemos a partir da mesma linha de base limpa.
Escolhemos 32 GB de VRAM por nó de forma deliberada. Os motores de renderização GPU modernos — Redshift, Octane, Arnold GPU, Cycles — carregam cada vez mais cenas com texturas volumosas que simplesmente não cabem em placas de 24 GB. A RTX 5090 com 32 GB é o ponto ideal atual para motores de renderização de produção; suporta a maioria dos trabalhos de archviz, motion design e animação sem fazer paging para a RAM do sistema, que é onde pools de GPU heterogéneos ficam silenciosamente lentos.
Os vinte nós são configurados de forma idêntica — mesma imagem, mesmo conjunto de instalação DCC, mesma montagem de cache, mesma rota WireGuard — e apresentam-se como um pool único ao render manager do cliente. O Deadline, o Royal Render, ou o scheduler do próprio cliente trata a frota como um único recurso sem qualquer lógica de routing por grupo ou reequilíbrio manual. Os frames são entregues ao nó que estiver livre; o render manager do cliente trata da distribuição de carga ao nível da fila de trabalhos.
A frota é roteável na camada 3 — o cliente instala o seu próprio render manager e submete a partir de uma estação de trabalho remota em vez de conduzir cada nó através de ambiente de trabalho remoto. Isto importa mais do que as pessoas esperam: é a diferença entre um cluster com que os artistas lutam e um cluster que os artistas esquecem.
Credenciais pertencentes ao cliente (Modelo B)
A única decisão arquitetónica que mais frequentemente torna um cluster dedicado a resposta certa para workflows sensíveis à propriedade intelectual é o que chamamos Modelo B: credenciais pertencentes ao cliente. No Modelo A — o padrão para render farms geridas, incluindo o nosso próprio serviço SaaS — o fornecedor de infraestrutura detém credenciais para a pipeline de renderização. O cliente faz upload dos ficheiros de cena; a pipeline do fornecedor medeia a renderização. Isto funciona para a vasta maioria das cargas e é o modelo por trás de quase todas as render farms comerciais na nuvem.
No Modelo B, o fornecedor de infraestrutura fornece hardware, sistema operativo, rede e camada de cache, mas nunca detém o material de autenticação do cliente para a plataforma de cloud file-streaming ou para os dados de origem do projeto. O cliente inicia sessão na plataforma cloud em cada nó, exatamente como se estivesse na sua própria estação de trabalho. Os ficheiros do projeto são transmitidos a partir da cloud do cliente. Os renders são gravados de volta para a cloud do cliente. O papel do fornecedor está limitado à camada de hardware e pipeline.
Isto importa por três razões:
- Contratual: Quando o cliente final do cliente tem um NDA ou contrato de serviço principal que restringe onde as credenciais e os ficheiros de origem podem ser detidos, o Modelo B mantém o fornecedor fora do âmbito dessas restrições. O cliente não precisa de negociar a inclusão do fornecedor de renderização numa cadeia contratual que não foi concebida para isso.
- Auditoria: Quando o cliente precisa de demonstrar a um auditor de segurança que a sua pipeline de renderização não expõe credenciais a terceiros, o Modelo B dá-lhe uma resposta clara. O fornecedor pode produzir documentação de hardware, rede e operações; o cliente produz a cadeia de credenciais.
- Encerramento do compromisso: Como o fornecedor nunca deteve credenciais, o encerramento do compromisso é mais simples. O cliente revoga as suas próprias sessões cloud; o fornecedor limpa a cache, reimageia os nós a partir da linha de base limpa e fornece um atestado escrito de que a cache e as imagens dos nós foram destruídas. Não há passo de rotação de credenciais a certificar pelo fornecedor, porque nunca foram detidas credenciais.
O Modelo B não é para todos. Coloca a equipa de operações do cliente na responsabilidade do ciclo de vida das credenciais em cada nó — vinte rotações a coordenar se os segredos rotacionarem mensalmente. As equipas que já têm essa prática operacional implementada acham o compromisso aceitável. As equipas sem ela tendem a manter-se no Modelo A de renderização gerida.
Integração de cloud file-streaming
Nas configurações aqui discutidas, os assets do projeto do cliente residem numa plataforma de cloud file-streaming — um serviço que expõe a árvore de projeto suportada pela cloud como um sistema de ficheiros virtual em cada nó. O artista monta o projeto; o nó lê os ficheiros a pedido; a plataforma trata do armazenamento de suporte, versionamento e replicação entre regiões.
A integração é feita com uma plataforma genérica de cloud file-streaming à escolha do cliente. A plataforma recebe um evento de início de sessão de cada nó utilizando a conta do cliente; o cliente da plataforma a correr no nó monta a árvore do projeto num caminho conhecido; a aplicação DCC do cliente abre ficheiros a partir desse caminho exatamente como o faria numa estação de trabalho local. A plataforma cloud não precisa de saber que o nó faz parte de um cluster de renderização.
O que muda quando isto é ligado a um cluster de 20 nós é o padrão de acesso. Um único artista numa única estação de trabalho extrai um ficheiro de projeto de cada vez, a pedido, enquanto trabalha. Vinte nós de renderização a abrir a mesma cena ao mesmo tempo para um intervalo de frames criam uma rajada sincronizada de leituras cloud para os mesmos assets. Sem uma cache, cada nó extrai cada textura, cada simulação em cache, cada ficheiro de dependência, em paralelo — o que é simultaneamente um desperdício de largura de banda internacional e lento no primeiro frame de cada intervalo.
É por isso que a cache partilhada existe. Falamos dela em detalhe na secção seguinte, mas a integração com o cloud file-streaming é a razão pela qual tem de existir. As extrações de assets da cloud são concentradas através da caixa de cache uma única vez, depois distribuídas pelos vinte nós pela LAN. A plataforma cloud nunca vê vinte extrações simultâneas da mesma textura — vê uma extração, mais leituras SMB quentes dentro da nossa rede.
O outro detalhe prático é a gravação de retorno. Quando um frame de renderização termina, o nó escreve o output para a plataforma de cloud file-streaming — de volta através da conta do cliente. A equipa do cliente no escritório remoto vê os frames a aparecer na árvore do projeto em tempo real. Não há passo de upload manual, nem transferência mediada pelo fornecedor; a plataforma cloud gere o ciclo completo.
Arquitetura da cache partilhada
A cache partilhada é uma das duas ou três escolhas arquitetónicas que, quando feitas de forma errada, corroem silenciosamente o valor de um cluster. Já a fizemos de forma errada em implementações anteriores. O padrão que se tem mantido ao longo de múltiplas construções é deliberadamente conservador.
Uma única caixa edge-e-cache corre Ubuntu 22.04 LTS, com um único SSD SATA de 8 TB formatado como ext4 e exposto ao cluster por Samba SMB3. A montagem da cache aparece em cada nó de renderização num caminho fixo (por exemplo \\cache.lan\proj). Quando um nó abre um ficheiro de projeto através do cliente de cloud file-streaming, o ficheiro é transmitido através da cache local; as leituras subsequentes do mesmo ficheiro em qualquer nó acertam diretamente no SSD pela LAN.
Há três escolhas deliberadas enterradas nesse parágrafo.
Primeiro, uma única cache, não caches por nó. Uma versão anterior desta arquitetura armazenava material de cache por nó. Com vinte nós 5090, isso significava até 200 TB de armazenamento redundante a gerir, e vinte estados de cache separados para depurar quando algo divergia. Consolidar numa única cache partilhada reduz a pegada de armazenamento por um fator de vinte e torna o estado da cache um único artefacto que a equipa de operações pode inspecionar.
Segundo, um único SSD em ext4, não RAID 10 com LUKS sobre XFS. O plano anterior previa que a cache residisse num array RAID 10 com cifra em repouso LUKS sobre XFS. Esse plano era demasiado complexo para o hardware real que implementamos — um SSD, um sistema de ficheiros, uma montagem. Removemos a camada RAID, removemos o LUKS, e usámos ext4 porque a cache não é a fonte de verdade dos dados do projeto. A cloud do cliente é a fonte de verdade. Se a unidade de cache falhar, substituímos e aquecemos de novo a partir do upstream; não precisamos de redundância na camada de cache porque temos redundância na camada cloud. (A cifra em repouso estava fora do âmbito deste contrato mas está disponível como compromisso separado quando um cliente final o exige.)
Terceiro, pré-aquecer a cache antes do primeiro dia de renderização. Esta é a lição que aprendemos da forma mais difícil. No D-Dia, cada cache miss é a leitura mais cara no cluster — atravessa a ligação internacional, extrai da cloud do cliente e escreve no SSD local antes de o motor de renderização a poder consumir. O pré-aquecimento, que é uma passagem estruturada pela árvore de assets do projeto no dia anterior ao início da produção, converte as leituras do D-Dia de extrações cloud frias em leituras SMB quentes. Planeamos agora uma janela de pré-aquecimento em cada compromisso de cluster dedicado.
Dentro da instalação, cada nó monta a cache no mesmo caminho fixo (\\cache.lan\proj) por SMB3 na LAN local. Como o tráfego intra-instalação não atravessa o túnel WireGuard, o clamping MSS não se aplica aqui e a ligação corre a velocidades Ethernet gigabit fim-a-fim. O caminho de montagem da cache é idêntico em todos os nós, o que simplifica a configuração do render manager do cliente — o mesmo caminho de ficheiro de cena resolve-se da mesma forma em todos os membros do pool.
Otimização de rede transfronteiriça
A camada de transporte é onde um cluster transfronteiriço ou parece contínuo ou parece quebrado. Os comportamentos padrão do TCP/IP, fragmentação de IP e DNS sobre VPN são subtilmente errados para túneis cifrados de longa distância que transportam SMB e ambiente de trabalho remoto. Afinar o kernel e a configuração de rede não é opcional; é a diferença entre um cluster que funciona e um que misteriosamente descarta pacotes grandes.
WireGuard, hub-and-spoke. Cada artista liga-se a partir da sua estação de trabalho através de um cliente WireGuard ao hub na instalação do cluster. Todo o tráfego entre o artista e o cluster é cifrado fim-a-fim. Deliberadamente usamos uma única tecnologia VPN em vez de misturar protocolos; combinar IPSec para um papel e uma VPN diferente para outro acrescenta superfície operacional sem melhorar a segurança.
TCP BBR. O controlo de congestão padrão do Linux (CUBIC) foi concebido para ligações de baixa latência com pouca perda de pacotes. As ligações ISP públicas de longa distância com tráfego cifrado têm um aspeto muito diferente — latência moderada, jitter ocasional e padrões de perda assimétricos. O BBR produz consistentemente maior débito utilizável nestas ligações do que o CUBIC, especialmente quando a ligação é partilhada com outro tráfego de internet do cliente. Usamos o BBR de stock do kernel (BBR v1); o BBRv3 mais recente não foi implementado nesta construção, e a versão de stock tem sido estável.
Clamping TCP MSS. Esta é a única fonte mais comum de reclamações do tipo "o cluster funciona principalmente, exceto para ficheiros grandes". Quando o tráfego atravessa um túnel que reduz o MTU efetivo, os pacotes grandes são ou fragmentados (lento) ou descartados silenciosamente (pior). Os pacotes pequenos e o ping funcionam bem, o que torna o problema difícil de diagnosticar. A correção consiste em fixar o TCP MSS no router WireGuard para que o TCP negocie um tamanho de pacote que caiba dentro do túnel. Depois de aplicar isto, os handshakes TLS, as sessões RDP e as leituras de ficheiros grandes por SMB deixam de ficar suspensas.
dnsmasq com a interface VPN listada. Um detalhe subtil: o dnsmasq deve listar explicitamente a interface WireGuard (por exemplo wg0) na sua configuração, mesmo que o cliente esteja a consultar um endereço .lan privado. Sem isso, as pesquisas DNS pelo túnel expiram, mas o ping ainda funciona porque o ping não passa pelo DNS. Isto produz algumas das sessões de diagnóstico mais confusas que realizámos, porque todos os outros testes parecem saudáveis.
chrony para NTP. A sincronização de tempo parece trivial mas importa para os render managers (o Deadline marca os trabalhos com timestamps), para a correlação de logs em todo o cluster, e para quaisquer tokens de autenticação com componente temporal. O chrony gere melhor a deriva do relógio numa ligação de alta latência do que o ntpd mais antigo; corremo-lo na caixa edge e cada nó sincroniza com ele.
O efeito combinado destas escolhas é um túnel que parece uma LAN para a maioria das cargas e degrada graciosamente quando o caminho público está incomumente congestionado. A secção seguinte aborda o aspeto da execução de trabalho 3D nesse túnel na prática.
Moonlight e Sunshine para ambiente de trabalho remoto
O ambiente de trabalho remoto é a camada que os artistas experienciam mais diretamente. Se parecer lento ou instável, não importa quão rápido seja o motor de renderização — as mãos do artista são lentas e o compromisso degrada-se.
Usamos o Moonlight (cliente) e o Sunshine (host em cada nó) para ambiente de trabalho remoto. A combinação usa o codificador de hardware NVENC da NVIDIA na RTX 5090 para codificar o frame buffer em tempo real, depois transmite-o para a estação de trabalho do artista. Como a codificação acontece na GPU que já está no nó, não há contenção com o motor de renderização, e a latência acrescentada pelo ambiente de trabalho remoto é dominada pelo round trip de rede — não pela fase de codificação.
Para trabalho em viewport 3D, isto importa de uma forma que não importa para o ambiente de trabalho remoto tradicional. Os protocolos mais antigos — RDP, VNC, o ambiente de trabalho remoto padrão da Microsoft — foram concebidos para cargas de trabalho de escritório. Gerem bem texto, diálogos e janelas de mudança lenta, mas colapsam num viewport 3D a ecrã inteiro durante uma pré-visualização de turntable. O Moonlight + Sunshine trata o frame buffer como vídeo, que é exatamente o modelo correto para trabalho 3D.
Temos um teste de controlo de qualidade que executamos antes de entregar um nó a um artista — informalmente, "Teste 8" — que exercita uma sequência definida de operações de viewport sob carga e confirma que a experiência de ambiente de trabalho remoto cumpre uma linha de base. Se um nó falhar o teste, ou depuramos a pipeline de codificação ou retiramos o nó de rotação até resolvermos o problema. Executamos este teste no início de cada compromisso e após qualquer reimagem de nó.
O Parsec é uma alternativa viável quando o Sunshine tem um problema específico do host. Já implementámos um pequeno número de nós com Parsec quando o Sunshine não pôde ser configurado de forma fiável; a experiência do artista é semelhante. Não o padronizamos porque o modelo baseado em conta e coordenado pela cloud não se enquadra tão claramente no manuseamento de credenciais do Modelo B como o Sunshine autoalojado.
Considerámos outras opções de ambiente de trabalho remoto no planeamento inicial e afastámo-las — ferramentas genéricas de ambiente de trabalho remoto sem codificação GPU, e uma alternativa de código aberto que não cumpriu o nosso controlo de qualidade num viewport 3D a ecrã inteiro. O princípio que importa: para nós de cluster GPU, a transmissão com codificação por hardware é o único modelo que se mantém à escala.
Planeamento de capacidade e reserva fixa
A configuração de 20 nós neste guia é uma fatia dedicada reservada da frota mais ampla da Super Renders Farm, criada para a duração do compromisso. Reservada significa que os nós não são partilhados com o pool de serviço gerido, não são co-agendados com outros tenants, e não estão sujeitos a faturação por frame — o cliente paga pela fatia como uma despesa operacional fixa e tem controlo exclusivo desses nós desde o início até ao encerramento.
Dimensionar a fatia em vinte nós é uma escolha deliberada. Abaixo de dez nós, um cluster não justifica a sua superfície arquitetónica face a uma render farm gerida — o caminho SaaS é mais simples e mais económico. Acima de trinta, a camada de cache precisa de ser rearquitetada (múltiplas caixas de cache, caches regionais) e o modelo operacional muda de forma. Vinte é a faixa onde uma única caixa edge-e-cache, um único hub WireGuard e uma imagem Windows uniforme se mantêm limpos — e onde uma equipa criativa de dez a vinte artistas tem nós suficientes para manter os frames a fluir durante os picos sem tempo ocioso durante o estado estável.
Como a Super Renders Farm opera uma frota substancial além desta fatia dedicada, existe capacidade para escalonamento quando o compromisso o exige. Adicionar nós reservados adicionais dentro da mesma instalação é uma alteração de configuração, não um ciclo de aquisição. Os clientes com compromissos plurimensais tipicamente fixam o tamanho da fatia no início e recalibram nas fronteiras trimestrais com base na procura real face ao plano original.
Segmentação de rede
A segmentação de rede num cluster como este não é opcional. O cliente opera na infraestrutura do fornecedor, mas nunca deve poder ver a rede mais ampla do fornecedor — nem a NAS do fornecedor, nem as interfaces de administração do router, nem quaisquer outros tenants. Da mesma forma, os sistemas internos do fornecedor nunca devem ser expostos às cargas do cliente.
A segmentação é implementada em dois níveis.
Nível 1 — firewall de edge. A caixa edge-e-cache corre o ufw (uncomplicated firewall) com uma postura de entrada default-deny. Apenas a porta UDP do WireGuard (51820) está exposta à internet pública. SSH, SMB, DNS, NTP e qualquer outro serviço a correr no edge estão vinculados a interfaces internas e inacessíveis do exterior do cluster. As regras de reencaminhamento permitem pacotes entre a interface WireGuard e a LAN do cluster, mas não entre qualquer um deles e as outras redes internas do fornecedor. A postura de reencaminhamento padrão é descartar, a menos que explicitamente permitido.
Nível 2 — firewall de host em cada nó. Cada nó de renderização tem a sua própria configuração de firewall Windows que espelha a postura do edge — aceitar entrada de IPs do cluster para os serviços de que o cluster precisa (SMB, ambiente de trabalho remoto, render manager) e descartar tudo o resto. Isto não é redundante; é defesa em profundidade. Se um nó estiver mal configurado ou comprometido, a firewall do host permanece como barreira.
O princípio por detrás de ambos os níveis é o de menor privilégio: o cliente e os nós devem ver o grupo de nós e mais nada. Não são fornecidas ao cliente rotas gerais para a rede interna do fornecedor. O túnel do cliente termina na caixa edge; a caixa edge encaminha apenas para a LAN do cluster; a LAN do cluster encaminha apenas entre membros do cluster.
Na prática, o cliente não consegue fazer ping nem scanning aos outros sistemas do fornecedor, mesmo que quisesse. Sem plano de gestão partilhado, sem caminho de monitorização partilhado que exponha outros tenants.
Lições aprendidas
Estas são cinco lições operacionais que, em cada cluster dedicado que montámos, ou nos pouparam horas de depuração ou — quando nos esquecemos de as aplicar — nos custaram horas de depuração.
1. Armadilha de routing com gateway de dupla interface. Quando a caixa edge tem duas interfaces de rede (uma pública, uma LAN), a ordem das operações importa. A rota LAN deve ser configurada antes de a rota padrão ser alterada. Se a rota padrão for mudada primeiro e depois se tentar adicionar a rota LAN, a sessão SSH usada para iniciar sessão pode cair no momento em que a rota padrão muda, e o acesso à caixa fica bloqueado. A correção é processual, não técnica: configurar sempre as rotas internas primeiro, validá-las, e só depois tocar na rota padrão.
2. WireGuard e DNS. O dnsmasq deve listar explicitamente cada interface em que deve escutar, incluindo a interface WireGuard. Se apenas a interface LAN for listada, as pesquisas DNS dos clientes VPN expiram — mas as respostas a ping ainda funcionam, porque o ping não passa pelo DNS. Este é um dos modos de falha mais enganosamente difíceis de diagnosticar que encontrámos. A correção é uma linha na configuração do dnsmasq, mas é preciso saber onde procurar.
3. O clamping TCP MSS não é opcional através de um túnel. Handshakes TLS, sessões RDP, leituras de ficheiros grandes por SMB — qualquer coisa que queira enviar pacotes grandes — cairá silenciosamente se o MSS não for fixado. O primeiro sintoma é geralmente "o Moonlight funciona dez segundos e depois bloqueia" ou "o SMB lista diretórios mas não consegue ler ficheiros maiores que 1 MB". A correção é uma regra iptables no host WireGuard. Deve ser aplicada antes de o cluster ser entregue.
4. Dimensionar bem o armazenamento, sem sobreengenharia. A versão anterior desta arquitetura especificava RAID 10 com cifra LUKS em XFS. O hardware de cache que implementámos era um único SSD. Removemos a camada RAID, removemos a camada LUKS, e usámos ext4 — porque a cache não é a fonte de verdade, a plataforma cloud é. Trocar redundância em papel na camada de cache por redundância real na camada cloud foi a decisão certa. A lição é conceber o armazenamento em função do que os dados realmente requerem, não do que parece seguro num documento de planeamento.
5. Pré-aquecer a cache. No D-Dia, cada cache miss custa à ligação internacional e à plataforma cloud um round trip. A primeira hora de produção numa cache fria parece lenta, mesmo quando todo o resto está configurado corretamente. Planeamos agora uma janela de pré-aquecimento em cada compromisso — geralmente um ou dois dias antes do início da produção. O artista não vê o pré-aquecimento; vê um cluster que já parece rápido no primeiro frame.
Estas são lições operacionais, não arquitetónicas. Residem na lista de verificação de implementação, não no documento de arquitetura. Mas separam um cluster que funciona em teoria de um que se mantém sob carga de produção real. Os padrões menores são aplicados numa base por-compromisso — os cinco acima são os que apareceram em cada implementação.
Conclusão
Uma render farm GPU dedicada e transfronteiriça de 20 nós é a arquitetura correta quando o controlo da propriedade intelectual é contratual, o compromisso é plurimensal, o workflow precisa de configuração personalizada, e a autenticação bring-your-own-cloud é inegociável. Fora dessas condições, uma render farm gerida é quase sempre a melhor resposta — a complexidade arquitetónica aqui não se justifica para trabalho com base em projeto ou para equipas sem uma função de operações dedicada.
Quando as condições se aplicam, os padrões aqui abordados — credenciais Modelo B, cache partilhada em ext4, transporte WireGuard hub-and-spoke, BBR com clamping MSS, Moonlight + Sunshine para ambiente de trabalho remoto, firewalling em dois níveis — são o que implementamos por defeito. Não são os únicos padrões válidos, mas são os que se mantiveram ao longo das implementações.
A equipa por trás da Super Renders Farm opera tanto o aluguer de render farm gerida como implementações de clusters dedicados — incluindo as configurações de cluster GPU dedicado e topologias transfronteiriças descritas ao longo deste guia.
FAQ
Q: Quanto tempo demora uma implementação típica de cluster dedicado de 20 nós? A: Dependendo do âmbito, da prontidão do hardware na instalação e da configuração de cloud file-streaming do cliente, um compromisso típico demora de algumas semanas de lead time para aprovisionamento de hardware e rede, seguidas de uma janela de pré-aquecimento de um a dois dias antes do início da produção. O cronograma é dimensionado em função do calendário de produção do cliente, não em função de um modelo fixo.
Q: E se a equipa estiver dividida por três continentes? A: A topologia hub-and-spoke do WireGuard escala para localizações de clientes adicionais sem alterar a arquitetura do cluster. Cada artista remoto executa um cliente WireGuard e liga-se ao mesmo hub na instalação do cluster. A latência de cada região é determinada pelo caminho de internet pública entre essa região e o hub; na nossa experiência, o BBR e o clamping MSS fazem a diferença entre utilizável e inutilizável nesses caminhos.
Q: É possível ver o cluster antes de assumir um compromisso plurimensal? A: Normalmente organiza-se uma janela de prova de conceito durante a conversa de definição do âmbito. A forma exata depende do projeto do cliente — por vezes é uma sessão de ambiente de trabalho remoto num único nó para testar a experiência do artista, por vezes é um teste de renderização de pequena escala para validar a cache e a integração de cloud file-streaming. Os termos específicos são uma questão comercial; basta contactar a nossa equipa de vendas para discutir o que funcionaria para o cronograma disponível.
Q: Como é tratada a segurança dos dados no encerramento do compromisso? A: Como o Modelo B mantém as credenciais do cliente fora das nossas mãos, o encerramento do compromisso foca-se na limpeza do hardware e da cache. Limpamos a cache SMB, reimagemos cada nó a partir da linha de base limpa e fornecemos um atestado escrito de que a cache e as imagens dos nós foram destruídas. O cliente revoga as suas próprias sessões de cloud file-streaming, que estão fora do nosso sistema. A linguagem contratual específica (NDA, SLA, redação da carta de atestado) é tratada pela nossa equipa de vendas.
Q: E se forem necessários mais de 20 nós? A: A configuração de 20 nós é a forma mais comum que implementamos, mas a arquitetura escala para além disso. As frotas maiores são adicionadas dentro da mesma instalação — os nós reservados adicionais alimentam o mesmo hub WireGuard, a mesma cache SMB3 e a mesma imagem Windows uniforme. O limite prático é geralmente a largura de banda da cache: uma única caixa edge-e-cache tem um teto de leitura SMB finito, e em frotas muito grandes a própria arquitetura de cache precisa de ser repensada (múltiplas caixas de cache, caches regionais). Estas escolhas de design são discutidas numa base por-compromisso.
Q: É possível trazer a licença própria para Cinema 4D, Redshift ou outras ferramentas DCC? A: O modelo de licença — bring-your-own-license vs. fornecida pelo prestador — é uma decisão comercial que depende da ferramenta DCC específica e do inventário de licenças existente do cliente. Algumas configurações funcionam de forma limpa com licenças do cliente; outras são mais simples com licenças fornecidas pelo prestador. Isto é trabalhado durante a conversa de definição do âmbito. Basta contactar a nossa equipa de vendas para especificidades.
Q: Como é tratado o armazenamento cloud de fornecedores da UE vs. dos EUA? A: A plataforma de cloud file-streaming é escolha do cliente. O nosso cluster integra-se com qualquer plataforma que possa executar um cliente de início de sessão no Windows e expor a árvore do projeto do cliente como um sistema de ficheiros montado. A localização geográfica da cloud upstream afeta a latência internacional do caminho cliente-cluster — razão pela qual recomendamos o transporte WireGuard hub-and-spoke e a configuração afinada com BBR para configurações transfronteiriças. Não alojamos a plataforma cloud em si; essa permanece sob a conta do cliente.
Q: O que acontece se o túnel WireGuard cair? A: O WireGuard restabelece automaticamente a sessão quando a rede subjacente recupera; a sessão de ambiente de trabalho remoto do cliente pode pausar brevemente durante o rehandshake. Se o túnel cair durante uma renderização em curso, a própria renderização continua a correr no nó (não depende do túnel para o trabalho em curso), mas a gravação de retorno para a cloud ficará em fila até o túnel ser restaurado. Monitorizamos o estado do túnel a partir da caixa edge e alertamos para períodos de inatividade prolongados.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



