
クラウドレンダーファームでのOctane:GPUレンダリング、OctaneBench料金、DCC対応(2026年版)
概要
はじめに
OctaneRenderには明確な評判があります:物理的に正確で、スペクトル的に精密、そして適切なハードウェア上では高速です。また、一つの厳格なルールがあり、これがOctaneに関するすべての判断を形作っています — OctaneはGPU上でのみ動作し、他の選択肢はありません。このたった一つの制約が、優れたマシンでは快適でありながら、レンダーファーム (render farm — クラウド上の分散レンダリング環境) でのスケールアップには本質的な課題をもたらす理由です。
当社のGPUレンダーファームでは、V-Ray、Corona、ArnoldなどのCPUエンジンと並行してOctaneジョブを実行しています。GPU側 — Octane、Redshift、V-Ray GPU — は着実に成長し、数千のジョブを通じて、このエンジンが輝く場面と問題が生じる場面を深く理解しました。
本ガイドでは、クラウドでOctaneRenderを大規模に運用する実際の状況を解説します:GPU専用レンダリングがファームの動作にどのような影響を与えるか、OctaneBench時間課金の仕組みと、なぜそれが単純なカード時間単位よりも誠実な課金方式なのか、どの3Dアプリケーションとの組み合わせが最適か、そして大容量シーンのアップロード前にVRAMをどう考えるか。マーケティング的な表現は抜きにして、実際の動作を解説します。
OctaneRenderの特徴:GPU専用、アンバイアスド、スペクトル計算
OctaneRenderはOTOYのアンバイアスド・スペクトル対応パストレーサーです。「アンバイアスド」とは、近似計算ではなく実際の光輸送をシミュレートすることで物理的に正確な結果に収束することを意味します。「スペクトル」とは、単純なRGBではなく完全な光スペクトル全体で色を計算することを意味し、これがOctaneレンダリングの仕上がりが非常にクリーンに見える理由の一つです。ファームとの関係で重要なのは、このエンジンが要求するハードウェアです。
OctaneはCUDAとNVIDIA OptiXレイトレーシングAPIを通じてNVIDIA GPU上でのみ動作します。CPUレンダリングモードは存在しません — フォールバックとしても、ハイブリッドオプションとしても、オーバーフローパスとしても。シーンがGPU上で実行できなければ、Octaneでは一切レンダリングできません。これはCPUまたはハイブリッドパスを提供するV-RayやRedshiftとは異なります。AMD GPUとApple Siliconもサポートされていません:OctaneはCUDAを必要とし、CUDAはNVIDIA専用です。当社のGPUフリートはVRAM 32 GBのNVIDIA RTX 5090カードで構成されており — Octaneをはじめ他のGPUエンジンが必要とする仕様そのものです。
RTX世代のカード(Ampere、Ada、そして現在のBlackwell)では、OctaneはOptiXを使用してハードウェアアクセラレーションによるレイトレーシングを実行します — ソフトウェアエミュレーションではなく、RTコアでの本物のBVHトラバーサルです。また、スペクトルAIデノイザーが同じGPU上で蓄積サンプルへのポストプロセスとして実行されます。このデノイザーは特定のシードとサンプル数に対して決定論的であり、これは見た目以上に重要です:アニメーションを多くのノードに分散する場合、47フレームが46フレームと微妙に異なる見た目にならないよう、デノイザーの一貫性が求められます。
最も混乱を招く点の一つはアウト・オブ・コア・メモリです。Octaneは、VRAMを超えるテクスチャをPCIeバスを通じてシステムメモリからページングできるため、テクスチャセットが大きいシーンでもレンダリング可能です — ただしパフォーマンスコストがあり、PCIe帯域幅はカードのオンボードGDDR7帯域幅のほんの一部です。アウト・オブ・コアがカバーしないのはジオメトリです:三角形データとBVHアクセラレーション構造はVRAMに収まる必要があります。ジオメトリだけでカードのメモリを超えるシーンはレンダリングできません。したがって「アウト・オブ・コアは無制限のシーンサイズを意味する」と考えてはなりません — テクスチャに柔軟性を与えつつ、ジオメトリには固定の上限があることを意味します。
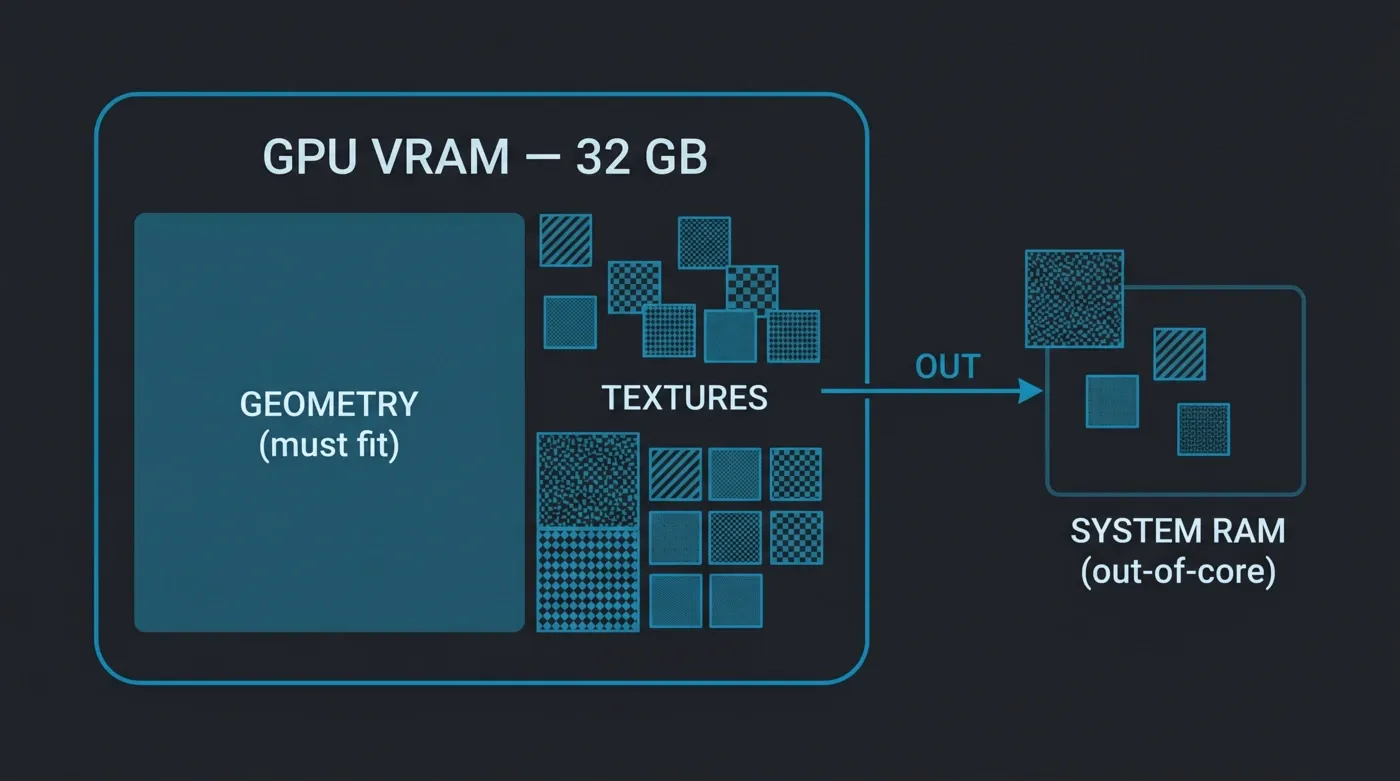
Octaneアウト・オブ・コア・メモリ:ジオメトリは32 GB GPU VRAM内に収まる必要があり、テクスチャはシステムRAMにスピルオーバーできます
クラウドレンダーファームでのOctane実行:本当に難しい部分
CPUレンダリングをファームに分散することは比較的容易な問題です — フレームを分割し、シーンを送信し、結果を収集するだけです。OctaneによるGPUレンダリングは、CPUファームが考慮する必要のない制約を導入します。
各GPUは独立した島です。 アニメーションを分散する場合、標準的なモデルはフレーム分散です:各GPUが異なるフレームを独立してレンダリングします。これはほぼ線形にスケールします — カードが2倍になれば、1時間あたりのフレーム数もほぼ2倍になります。Octaneには複数のGPUが1フレームに協力するネットワークレンダリングモードもありますが、それは異なる、より高いオーバーヘッドのワークフローです。ファームモデルは1カード1フレームです。実際の結果として:隣のカードからVRAMを借りることはできないため、すべてのノードがシーン全体を32 GBに収める必要があります。
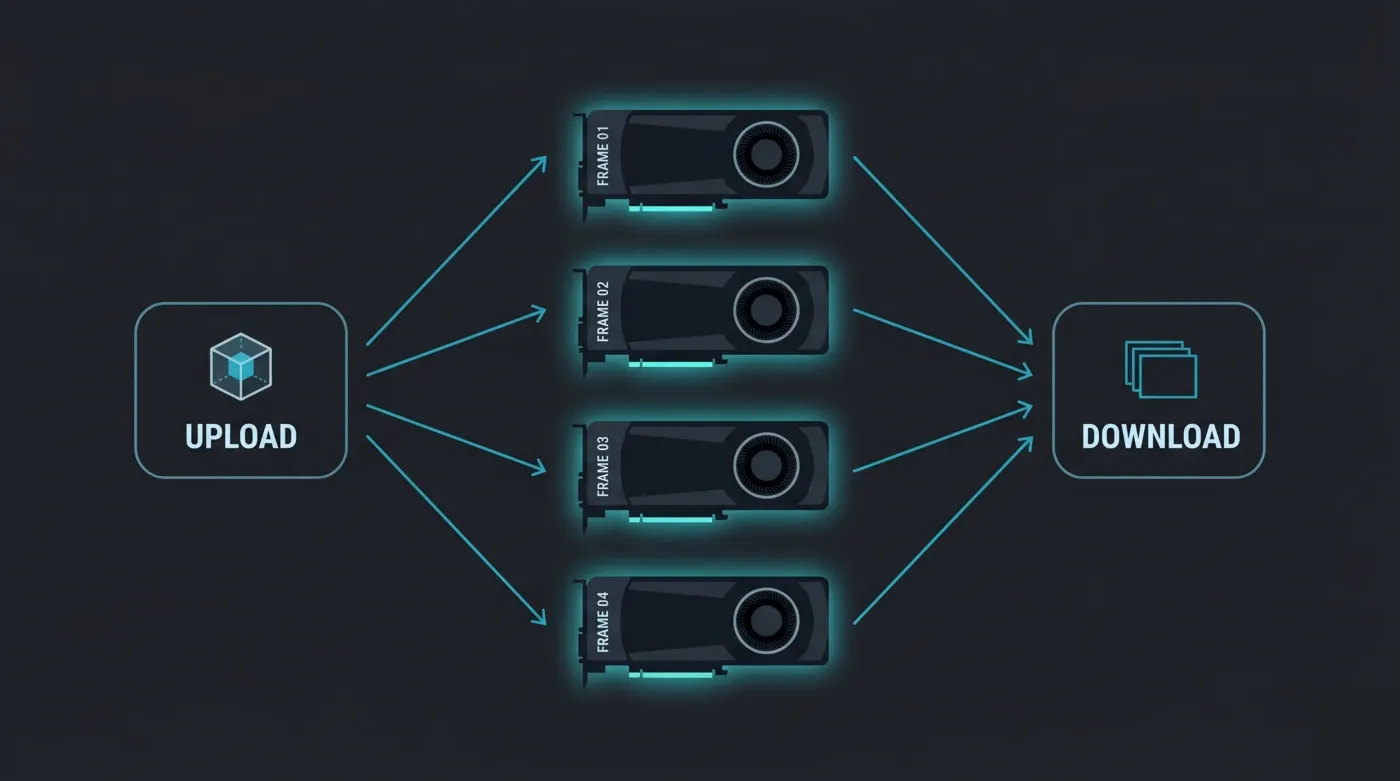
Octaneレンダーファームのフレーム分散:各RTX 5090 GPUノードが異なるアニメーションフレームを独立してレンダリングし、完成したフレームがダウンロード用に収集されます
ドライバとバージョンの一致は地味で重要です。 OctaneはCUDAドライババージョンについて厳格であり、DCC内のOctaneプラグインはファーム上のOctaneコアビルドと一致している必要があります。フリート全体でドライバが一致しない場合、クラッシュや、さらに悪い場合はノード間のサイレントなレンダリング差異が発生する可能性があります。セルフマネージドIaaSインスタンスでは、ドライバのピン留めとプラグインバージョンの調整は自分で行う必要があります。フルマネージドファームでは、フリートはサポートされているOctaneビルドにバージョンロックされており、エンジンライセンス(Octane含む)はレートに含まれています — インストールや有効化は不要です。
アセットはフレームが配置されるすべての場所に存在する必要があります。 すべてのテクスチャ、HDRI、参照ファイルは、どのノードがフレームを処理しても、シーンが期待する正確なパスからアクセスできる必要があります。マネージドパイプラインはアップロードしたプロジェクトからアセットを解決して配布します。DIY型GPUファームでは、共有ストレージとパスリマッピングを自分で設定する必要があります。
セルフマネージドGPUセットアップとフルマネージドファームの役割分担を以下に示します:
| タスク | セルフマネージド / IaaS GPUファーム | フルマネージドファーム |
|---|---|---|
| CUDAドライバ管理 | インスタンスごとにパッチとピン留め | フリートマネージド、サポート済みOctaneビルドにロック |
| Octaneエンジンのインストール | 全ノードにインストール | プリインストール、プラグインにバージョン一致 |
| レンダーエンジンライセンス | ノードごとに調達・有効化 | OBhレートに含む |
| アセットパス解決 | 共有ストレージ / パスリマッピングを設定 | アップロードしたプロジェクトから解決 |
| リモートデスクトップ設定(RDP) | ノード設定に通常必要 | 不要 — レンダリングは完全ヘッドレス |
| フレーム分散 | 自分でオーケストレート | 送信ルーティングが処理 |
最後の行は重要です。Octaneファームレンダリングは完全にヘッドレスであるため、リモートデスクトップの手順が不要です — DCCから送信するだけでファームがレンダリングし、GPU IaaSレンタルが依然として課す設定の手間をまるごと省けます。
OctaneBenchとOBh料金モデル
これは、多くのアーティストが明確に説明されたことがないOctane経済学の部分なので、じっくり解説する価値があります。
OctaneBenchはOTOYの標準化されたGPUベンチマークです。固定された参照シーンをレンダリングし、GPUがベースラインカードと比較して1秒あたりにどれだけのOctane処理を実行できるかを表す単一の無単位スコアを出力します。スコアが高いほどスループットが高くなります。OTOYが公開しており、誰でも実行できるため、Octane専用のGPU比較において信頼性の高いベンダー中立な方法となっています。
このベンチマークは、ここでのGPU処理の課金基準でもあります。当社はGPUレンダリングを1 OctaneBench時間(OBh)あたり$0.003で課金しています。1 OctaneBench時間とは、1単位のOctaneBenchスループットを提供するGPUの1時間分の計算処理です。OctaneBenchスコアが高いカードは1ウォールクロック時間あたり多くのOBhを提供し、遅いカードは少なくなります。課金はジョブが実際に消費したOctaneBench時間に対して行われます。
なぜこれが重要なのでしょうか?フラットなカード時間単位の料金を考えてみましょう。2つのファームがどちらも「1 GPU時間あたり$X」と宣伝していても、一方が現行世代のカードをレンタルし、他方が2世代前のカードをレンタルしている場合、まったく異なる作業量に対して同じ時間料金を支払うことになります — 高速なカードはわずかな時間で終了し、遅いカードははるかに多くの時間を課金します。OctaneBench時間課金はこれを正規化します:占有時間ではなく、提供されたレンダリングスループットに対して支払います。高速なカードが早く完了すれば、その作業に必要なOBhを消費して停止するだけです。
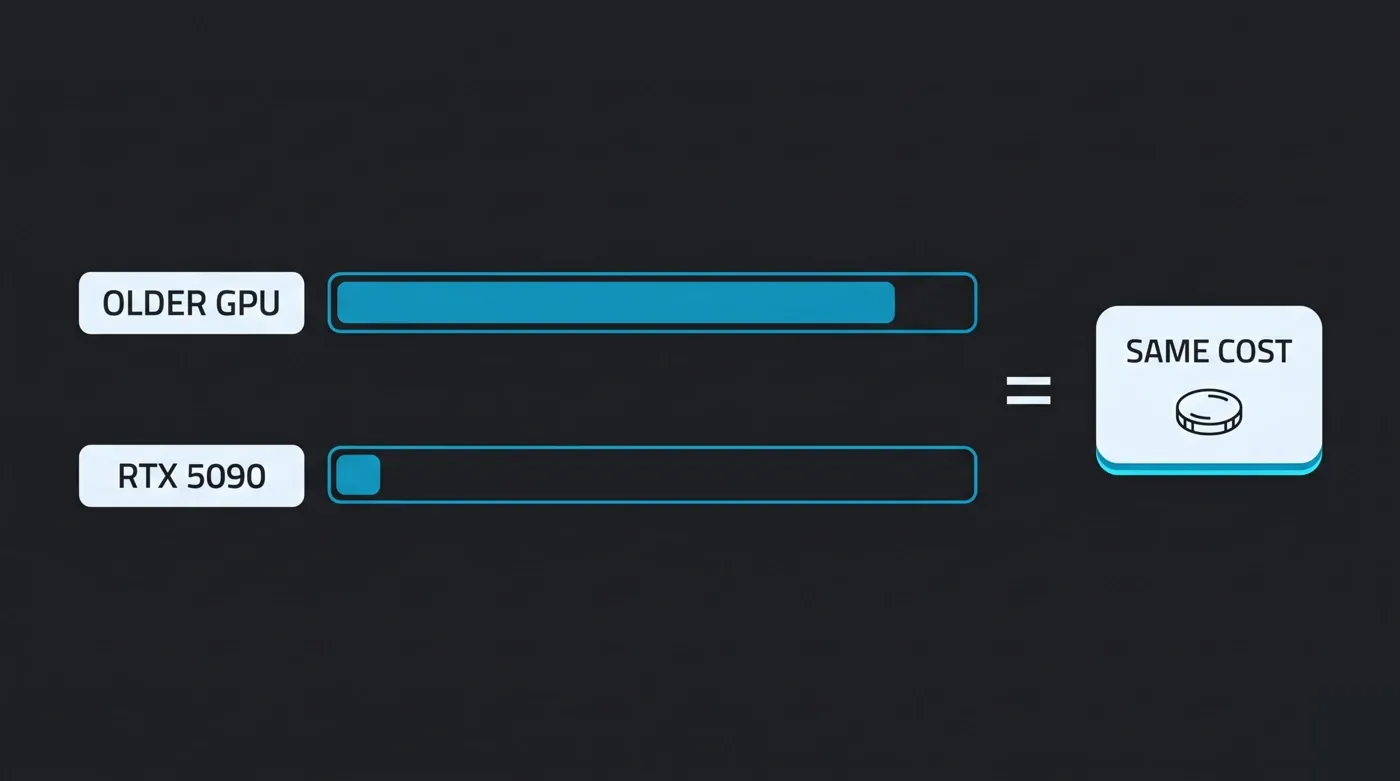
OctaneBench時間課金はレンダリングコストをスループットに正規化します:高速なGPUは短時間で完了するため、同じ作業はカード世代に関わらず同じコストになります
参考として、RTX 5090はウォールクロック時間1時間あたり約1,730 OctaneBench時間のスループットを提供します — Blackwellアーキテクチャの公開ベンチマークと一致する数値ですが、正確なスコアはシーンの複雑さやシステム設定によって異なります。固定部分はレート自体です:$0.003/OBh。ジョブの試算は以下の通りです:
| 項目 | 値 |
|---|---|
| 課金レート(確定) | $0.003 / OBh |
| RTX 5090スループット(参考) | 約1,730 OBh / カード時間 |
| 実効カード時間コスト | 約$5.20 / カード時間 |
| 例:90フレームアニメーション、約1カード時間/フレーム(参考) | 約90カード時間 |
| 例:合計 | 約90 × $5.20 ≈ $468 |
表内のフレームあたりレンダリング時間とOctaneBenchスコアは参考値として扱ってください — どちらも完全にシーンに依存します。固定部分はレートです。新規アカウントには**$25分の無料レンダークレジット**が付与され、クレジットは失効しないため、本番ジョブをコミットする前に実際のテストシーンで自分の数値を確認できます。完全なモデルはレンダーファーム料金ガイドで説明しており、フレームごとのジョブ見積もりの詳細な内訳はコスト・パー・フレームガイドにあります。
プロバイダーを比較する際に混乱を招くため、明確に述べておく価値があります:OctaneBench時間は、実際にOctaneRenderを実行していないファームでも課金単位として使用されることがあります — 提供するGPUエンジンの正規化指標としてベンチマークを借用しているのです。Octaneのサポートが特に重要な場合は、そのファームがエンジン自体を実行しているか(ベンチマークだけでなく)を確認してください。また、カード時間単位の見積もりは、どのカードをレンタルするかがわかるまで意味をなしません。GPU世代こそが実際のコストを決める数字です。
DCC別Octane対応:Cinema 4D、Maya、3ds Max、Houdini
Octaneはプラグインを通じて制作ワークフローに組み込まれており、プラグインの成熟度はアプリケーションによって異なります。Octaneが最も強力な場所を知ることで、パイプラインに適したエンジンかどうかを判断できます。
Cinema 4DはOctaneの本拠地です。C4D向けOctaneRenderプラグインはOTOYが提供する中で最も成熟し最も広く使われているインテグレーションであり、ネイティブのC4Dマテリアル、MoGraphとエフェクター、マルチパス出力のためのテイクシステム、ネイティブのモーションブラーを深くサポートしています。Cinema 4Dでモーションデザインやプロダクトビジュアライゼーションを行うアーティストにとって、Octaneは自然な選択です — 「Octane in production」と言う時に多くの人が意味するのはこのことです。また、OctaneとRedshiftのどちらを選ぶかという判断が最も頻繁に生じる場面でもあります。両者のトレードオフはCinema 4D Redshiftガイドで取り上げています。
Mayaには、Arnold やRedshiftに移行せずにGPUパストレーシングを求めるVFXおよびモーションパイプラインで使用される堅実なOctaneRenderプラグインがあります。マテリアルネットワーク、カメラとライティングの統合、Alembicキャッシュがすべてサポートされています。C4Dとの組み合わせほどコミュニティでの存在感はありませんが、商業的に重要な位置を占めています。
3ds MaxでもOctaneは良好に動作します。特にArchvizとプロダクトビジュアライゼーションの分野で使われています。3ds MaxのArchviz市場ではV-RayやCoronaなどのCPUエンジンが依然として主流であるため、Octaneはデフォルトではなく意識的な選択となっています — ただしプラグインは高機能でマテリアル変換も良好です。
Houdiniにはプロシージャルジオメトリを適切に処理するOctaneRenderプラグインがあり、VFXワークで使用されています。HoudiniのGPU領域ではSideFXのKarma XPUとRedshiftの方が大きなシェアを占めているため、Octane for Houdiniは実在しますが小さなニッチです — Octaneがすでにスタジオスタンダードであればよいオプションです。
Blenderアーティストへの注意。 Blenderのプロダクション標準パストレーサーはCyclesであり、ファームでのBlenderジョブにはCyclesを使用しています。当社のRTX 5090ノードでは、CyclesはOptiXハードウェアレイトレーシングを使用するため、別途Octaneサブスクリプションなしに、OctaneジョブとGPUパストレーシングを同じハードウェア層で実行できます — アンバイアスドで物理ベースの出力です。(EEVEE、Blenderのリアルタイムエンジン、はまったく別の話です:アクティブなディスプレイコンテキストが必要で、ヘッドレスレンダーノードでは動作しないため、EEVEEシーンはアップロード前にCyclesに切り替えてください。)Octaneが特定のエンジンとして必要な場合、Cinema 4D、Maya、3ds Max、HoudiniがOctaneの本来の場所です。Blenderをお使いの場合、GPU上のCyclesで同等のGPU結果が得られます。
GPU要件とOctaneが適切なエンジンである場合
OctaneはGPUに依存しているため、いくつかのハードウェアの現実を念頭に置いておく価値があります。
最も重要な数字はVRAMです。 RTX 5090の32 GBがOctaneのジオメトリ上限を設定します。フル家具ライブラリとディスプレイスメントを持つArchvizインテリアや、密度の高いキャラクタージオメトリとボリュームを含むVFXショットは、24 GBカードの容量を超えることがよくあります — 24 GB GPUでロードに失敗するシーンが32 GB GPUでは成功することがあります。これはマーケティング文句ではなく、具体的で検証可能な違いです。アウト・オブ・コアはテクスチャのヘッドルームを追加しますが、ジオメトリは収まるように計画してください。RTX 5090がGPUレンダリングに対してどのような位置づけにあるかについては、RTX 5090パフォーマンス記事で詳しく説明しています。
CUDAとNVIDIA、常に。 Octaneはコンピュートケーパビリティ5.0以上のCUDA対応NVIDIA GPUを必要とします(現行のカードはすべて余裕でクリアします)。AMDカードやApple Siliconでのレンダリングについてオンラインで読んだアドバイスは、Octaneワークフローには当てはまりません — このエンジンはそれらを使用できません。そのため、NVIDIA専用ハードウェアで構築されたファームはOctaneに最適なマッチであり、注意事項はありません。
Octaneが適切な選択である場合と、そうでない場合を整理します:
| 状況 | 適したエンジン | 理由 |
|---|---|---|
| C4Dのモーションデザイン、Archviz、GPUでのプロダクトビジュアライゼーション | OctaneRender | 最も成熟したインテグレーション、大きなコミュニティ、クリーンなスペクトル出力 |
| すでにMaxonエコシステムにいる | Redshift | バイアスドエンジン、高速収束、Maxonサブスクリプションに含む |
| Maya / VFX、GPU優先 | OctaneまたはRedshift | どちらも実用的。VFXではRedshiftが一般的、モーションワークではOctaneが強い |
| 3ds Max Archviz | V-RayまたはCorona(CPU) | このセグメントの市場標準 |
| Blender、GPUパストレーシング | Cycles(OptiX) | GPU上のBlenderネイティブなプロダクション標準 |
| Houdini VFX / プロシージャル | Karma XPUまたはRedshift | HoudiniのGPU市場でより大きなシェア。Octaneはセカンダリオプション |
| 32 GB近くのジオメトリ重いシーン | 32 GBノードのOctane | VRAMヘッドルームの主張がここで最も強い |
| CPUのみの予算またはパイプライン | V-Ray、Corona、Arnold(CPU) | OctaneはCPUでは一切動作しない |
GPU レンダリングは、Octaneを含め、当社のファームのすべてではないことを明確に述べておく価値があります — 実行するジョブの大半はCPUベースであり、V-RayとCoronaのArchvizワークが大部分を占めています。Octaneは成長中のGPUセグメントに位置しており、中心的なものではありません。パイプラインがCPUファーストであれば、上記のOctane固有の制約はすべて当てはまらず、CPUエンジンの方が適しているでしょう。本ガイドのポイントは、Octaneがその役割を果たす場所 — そうでない場所 — について正直に述べることです。
FAQ
Q: Super Renders FarmはOctaneRenderをサポートしていますか? A: はい。OctaneはNVIDIA RTX 5090 GPUノード(各32 GB VRAM)で動作し、OctaneRenderライセンスはレンダーレートに含まれています — インストールや有効化は不要で、レンダリングは完全ヘッドレスのためリモートデスクトップも不要です。
Q: OctaneBench時間(OBh)とは何ですか?料金の仕組みはどうなっていますか? A: OctaneBench時間とは、OTOYの標準化されたGPUベンチマークであるOctaneBenchの1単位のスループットを提供するGPUの1時間分の計算処理です。当社はGPUレンダリングを1 OBhあたり$0.003で課金しており、カードを占有した時間ではなく実際に提供されたレンダリングスループットに対して支払うことを意味します — 高速なGPUは早く完了し、その作業に必要なOBhを消費するだけです。
Q: ファームでOctaneレンダリングを行うにはどのようなGPUが必要ですか? A: ファームでレンダリングするためにご自身のGPUは不要です — レンダリングは当社のRTX 5090ノード上で行われます。Octane自体はCUDA対応のNVIDIA GPUが必要(AMDやApple Siliconでは動作しない)ですが、フリートはまさにそのハードウェアで構築されているため、エンジンに適合したハードウェアでシーンが動作します。
Q: OctaneはGPUのVRAMより大きなシーンをレンダリングできますか? A: 部分的には可能です。OctaneはVRAMを超えるテクスチャをアウト・オブ・コアを通じてシステムメモリからページングできますが、パフォーマンスコストがあります。ジオメトリは別の話です — 三角形データとアクセラレーション構造はVRAMに収まる必要があるため、ジオメトリだけでカードの32 GBを超えるシーンは、インスタンシング、プロキシ、テッセレーション削減で最適化されるまでレンダリングできません。
Q: ファームのOctaneではどの3Dアプリケーションが使えますか? A: OctaneのプロダクションでのホームはCinema 4D(フラッグシップインテグレーション)、Maya、3ds Max、Houdiniです。Cinema 4DはOctaneRenderプラグインの深さと広い使用実績で最も優れており、他のDCCもVFX、Archviz、モーションワークで成熟した状態で使用されています。
Q: BlenderシーンをOctaneでレンダリングできますか? A: Blenderの場合、当社ではCycles — Blenderのプロダクション標準パストレーサー — を実行しています。当社のRTX 5090ノードではCyclesがOptiXハードウェアレイトレーシングを使用するため、別途Octaneサブスクリプションなしに、OctaneジョブとGPUパストレーシングを同じハードウェア層で利用できます。Octaneが特定のエンジンとして必要な場合、Cinema 4D、Maya、3ds Max、HoudiniがOctaneの本来の場所です。Blenderアーティストは通常、Cyclesを通じて同等のGPU結果が得られます。
Q: Octaneはシーンがフィットしない場合、CPUにフォールバックしますか? A: いいえ。OctaneRenderはGPU専用です — CPUモードもハイブリッドフォールバックも存在しません。シーンがGPUで実行できない場合、フィットするよう最適化するか、V-Ray、Corona、ArnoldなどCPUレンダリングをサポートするエンジン(当社でも実行しています)を使用する必要があります。
Q: プロジェクトをファームに送る方法と、レンダー結果はどのくらい保存されますか? A: プロジェクトバンドルをアップロードします(tar、tar.gz、7zアーカイブを受け付けます。.zipは非対応です)。ファームがアセットを解決してレンダーノードに配布します。完成したレンダーは45日間保存され、Web、SFTP、またはクライアントアプリの自動ダウンロード機能でダウンロードできます。
About Alice Harper
Blender and V-Ray specialist. Passionate about optimizing render workflows, sharing tips, and educating the 3D community to achieve photorealistic results faster.



