
Come funzionano le render farm: guida tecnica per artisti 3D
Panoramica
Introduzione
Le render farm esistono perché le singole workstation raggiungono limiti insuperabili. Un'animazione da 500 frame a 20 minuti per frame richiede quasi una settimana su una sola macchina. Distribuisci quei frame su 100 macchine e lo stesso lavoro si completa in meno di due ore. La matematica è semplice — l'ingegneria che c'è dietro no.
Gestiamo una render farm con oltre 20.000 CPU cores e una flotta GPU dedicata con schede NVIDIA RTX 5090. Ogni giorno elaboriamo centinaia di lavori su V-Ray, Corona, Arnold, Redshift, Cycles e altri motori. Questa guida spiega cosa succede realmente dal momento in cui carichi un file di scena al momento in cui scarichi i frame finiti — i sistemi di accodamento, la distribuzione dei file, la gestione degli errori e le decisioni infrastrutturali che rendono il rendering distribuito affidabile su larga scala.
Se sei nuovo al concetto di render farm, la nostra guida su cos'è una render farm copre i fondamenti. Questo articolo approfondisce i meccanismi tecnici.
Cosa succede quando invii un lavoro di rendering
Il processo di invio comporta più passaggi di quanto la maggior parte degli artisti immagini. Ecco la sequenza, dalla tua workstation al primo pixel renderizzato.
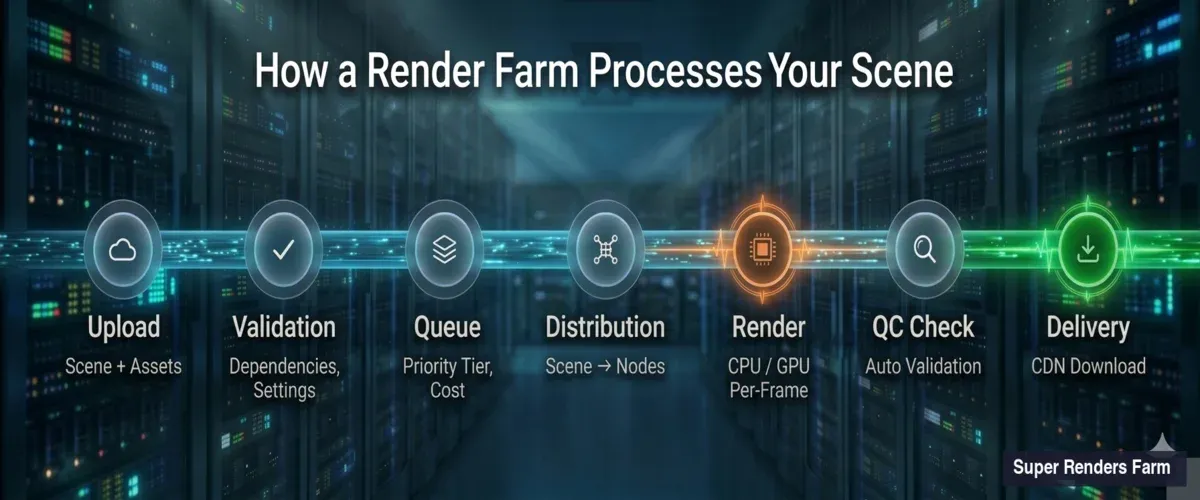
Pipeline della render farm che mostra 7 fasi: dall'upload della scena alla validazione, accodamento, distribuzione, rendering, controllo qualità, fino alla consegna finale
Upload e analisi della scena. Quando invii un file .max, .blend, .ma o di altro formato, il sistema di acquisizione della farm lo decomprime e cataloga ogni dipendenza — texture, cache, mesh proxy, mappe HDRI, asset dei plugin. Le dipendenze mancanti sono la causa più comune di rendering falliti. Il nostro sistema segnala i file mancanti prima che il tuo lavoro entri nella coda, così puoi correggere i percorsi invece di sprecare tempo di rendering su frame neri.
Validazione delle impostazioni di rendering. La farm legge le impostazioni di rendering incorporate: tipo di motore, versione, risoluzione, intervallo di frame, formato di output, parametri di campionamento. Le incrocia con le configurazioni dei nodi disponibili. Se hai specificato V-Ray 7 ma la scena è stata salvata in formato V-Ray 6, il sistema rileva questa discrepanza prima dell'inizio del rendering.
Stima dei costi. In base alla complessità della scena, risoluzione, conteggio dei campioni e dati storici di lavori simili, il sistema genera una stima di tempo e costo. Non è un'approssimazione — abbiamo elaborato abbastanza lavori da costruire modelli statistici che prevedono il tempo di rendering con un margine ragionevole per la maggior parte delle scene standard.
Code di lavoro e sistemi di priorità
Una volta validato, il tuo lavoro entra in una coda. Come la render farm gestisce questa coda determina se riceverai i frame in due ore o in dodici.
Livelli di priorità. La maggior parte delle farm offre più livelli di priorità. I lavori a priorità più alta ottengono accesso a più nodi contemporaneamente e possono avere precedenza sui lavori a priorità inferiore. Sulla nostra farm, la differenza tra priorità standard e alta è significativa — un lavoro da 200 frame potrebbe essere renderizzato su 20 nodi a priorità standard contro 80 nodi a priorità alta.
Schedulazione equa. Il gestore della coda bilancia le risorse tra tutti gli utenti attivi. Nessun singolo lavoro monopolizza l'intera farm, nemmeno ad alta priorità. Se la farm ha 400 nodi CPU disponibili e tre lavori ad alta priorità sono in esecuzione simultaneamente, lo scheduler distribuisce i nodi in modo proporzionale in base alla dimensione del lavoro, al tempo di completamento stimato e al livello dell'utente.
Prelazione e riaccodamento. Quando un lavoro ad alta priorità arriva e la farm è al massimo della capacità, lo scheduler può mettere in pausa i frame dei lavori a priorità inferiore e riassegnare quei nodi. I frame in pausa rientrano nella coda automaticamente — nessun lavoro viene perso, anche se i lavori a priorità inferiore impiegano più tempo per completarsi.
Rilevamento dei nodi inattivi. Se un nodo di rendering smette di rispondere (guasto hardware, crash del driver, timeout di rete), il gestore della coda rileva l'assenza di comunicazione in pochi secondi e riassegna i frame in corso a nodi funzionanti. Questo avviene in modo trasparente — non vedrai mai il guasto nel tuo output.
Distribuzione della scena: come i file raggiungono i nodi di rendering
Prima che un nodo possa renderizzare il frame 47 della tua animazione, ha bisogno dell'intera scena — geometria, texture, cache e configurazione. Spostare questi dati in modo efficiente è una sfida infrastrutturale fondamentale.
File system di rete. La maggior parte delle render farm di produzione utilizza storage condiviso ad alta velocità (NFS, SMB o file system distribuiti proprietari) invece di copiare i file della scena su ogni nodo singolarmente. La scena risiede in un cluster di storage centrale e i nodi di rendering vi accedono tramite la rete. Questo evita il collo di bottiglia della copia di una scena da 50 GB su 100 nodi in sequenza.
Cache e località. Le farm intelligenti memorizzano nella cache locale dei nodi di rendering gli asset a cui si accede frequentemente. Se tre lavori nel corso della giornata usano lo stesso pacchetto HDRI o la stessa libreria di materiali V-Ray, i nodi che hanno già quei file in cache saltano il trasferimento via rete. Questo riduce il tempo di avvio per frame da minuti a secondi per le texture ripetute.
Streaming delle texture. Per le scene con set di texture massivi (comune nell'archviz con librerie di materiali 4K+), alcune configurazioni di farm trasferiscono le texture su richiesta invece di precaricarle tutte. Il motore di render richiede una porzione di texture, il sistema di storage la consegna e il nodo la memorizza nella cache locale per i frame successivi. Questo scambio comporta una latenza leggermente superiore per singola porzione, ma un tempo di caricamento iniziale significativamente inferiore.
La fase di rendering: elaborazione CPU e GPU
Con la scena caricata e il frame assegnato, il rendering vero e proprio ha inizio. Come le farm allocano le risorse CPU rispetto a quelle GPU riflette reali compromessi di prestazioni e costi.

Confronto tra rendering CPU e GPU che mostra differenze in velocità, memoria, casi d'uso ideali, software supportato e specifiche hardware
Rendering CPU. I motori basati su CPU (V-Ray CPU, Corona, Arnold CPU) distribuiscono il lavoro su tutti i core disponibili di un nodo. Un tipico nodo CPU di una farm ha 44 o più core con 96–256 GB di RAM. L'ampio pool di memoria significa che i nodi CPU gestiscono scene che supererebbero la VRAM di una GPU — interni archviz complessi con mappe di displacement, simulazioni di particelle con milioni di elementi o effetti volumetrici con cache ad alta risoluzione.
Sulla nostra farm, circa il 70% dei lavori di rendering viene eseguito su nodi CPU. Questo riflette i flussi di lavoro archviz e VFX che dominano il rendering professionale — queste scene tendono ad essere pesanti in termini di memoria e utilizzano motori come V-Ray e Corona ottimizzati per le prestazioni CPU multi-core.
Rendering GPU. I motori basati su GPU (Redshift, Octane, V-Ray GPU, Cycles con OptiX) sfruttano le migliaia di core paralleli delle schede grafiche moderne. I nostri nodi GPU utilizzano schede NVIDIA RTX 5090 con 32 GB di VRAM. Il rendering GPU è tipicamente più veloce per frame per le scene che rientrano nei limiti della VRAM, ma quei limiti sono reali — una scena che richiede 40 GB di dati tra texture e geometria non può essere renderizzata su una scheda da 32 GB senza fallback out-of-core che riducono le prestazioni.
Allocazione ibrida. Alcuni lavori traggono vantaggio dalla suddivisione tra nodi CPU e GPU. Un pattern comune: i nodi GPU gestiscono i beauty pass (veloci per frame, limitati dalla VRAM), mentre i nodi CPU elaborano i pass volumetrici o di particelle che superano la capacità della VRAM. Lo scheduler della farm supporta questa suddivisione, instradando i diversi render layer verso l'hardware appropriato.
Assemblaggio dei frame e controllo qualità
Renderizzare un frame è solo metà del lavoro. La farm deve anche verificare la qualità dell'output e assemblare i frame in un pacchetto di consegna coerente.
Controlli qualità automatici. Dopo il rendering di ogni frame, la farm esegue una validazione di base: dimensione del file nell'intervallo previsto (un PNG da 1 byte significa che il rendering è fallito silenziosamente), risoluzione conforme alle specifiche, nessun frame completamente nero o completamente bianco (indicatori comuni di luci o materiali mancanti) e formato di output corretto. I frame che non superano questi controlli vengono automaticamente ri-renderizzati su un nodo diverso.
Ricomposizione dei frame per il rendering a tile. Alcuni motori e configurazioni dividono un singolo frame ad alta risoluzione in tile — renderizzando il quarto superiore sinistro su un nodo, il quarto superiore destro su un altro, e così via. Dopo il completamento di tutti i tile, la farm li ricompone nell'immagine finale a piena risoluzione. Questo approccio funziona bene per immagini fisse ad altissima risoluzione (8K+) dove un singolo nodo impiegherebbe ore per frame.
Consegna dell'output. I frame completati vengono scritti nello storage di output della farm e resi disponibili per il download. Utilizziamo cloud storage con accelerazione CDN per garantire che le velocità di download non siano limitate dalla larghezza di banda di upload della farm. Per grandi sequenze di animazione (migliaia di file EXR), offriamo opzioni di download in blocco e possiamo comprimere le sequenze per un trasferimento più rapido.
Architettura di rete di una render farm
L'infrastruttura che collega nodi di rendering, storage e sistemi di gestione è tanto importante quanto l'hardware stesso.
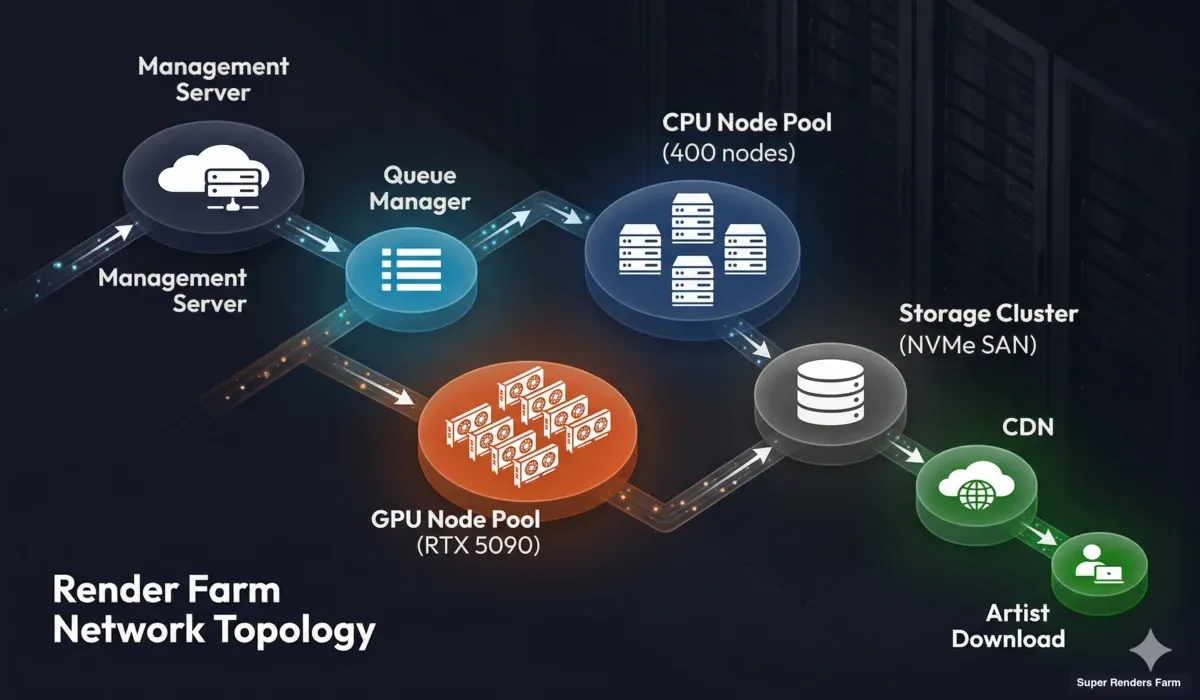
Topologia di rete della render farm che mostra server di gestione, gestore della coda, pool di nodi CPU e GPU, cluster di storage e consegna CDN agli utenti
Livello di gestione. Un server di gestione centrale orchestra tutto — acquisizione dei lavori, gestione della coda, monitoraggio dello stato dei nodi e comunicazione con gli utenti. Questo server è ridondante (con capacità di failover) perché se va offline, l'intera farm smette di accettare ed elaborare lavori.
Rete dei nodi di rendering. I nodi comunicano con il sistema di gestione e lo storage attraverso una rete interna ad alta larghezza di banda. Nelle farm moderne, questa è tipicamente Ethernet a 10 Gbps o superiore. La larghezza di banda conta di più durante la distribuzione della scena (caricamento delle texture) e l'output dei frame (scrittura di file EXR ad alta risoluzione sullo storage).
Cluster di storage. Lo storage centrale è la risorsa condivisa da cui ogni nodo di rendering legge e su cui scrive. Deve gestire letture simultanee da centinaia di nodi che richiedono porzioni di texture e scritture simultanee da nodi che producono frame renderizzati. Array di storage ad alte prestazioni (SAN basate su NVMe o file system distribuiti) sono essenziali. Un sistema di storage lento crea un collo di bottiglia che nessuna potenza CPU o GPU può superare.
Connettività Internet. La connessione della farm al mondo esterno determina la velocità con cui gli utenti possono caricare scene e scaricare risultati. Connessioni multi-gigabit ridondanti sono standard per le farm di produzione. Anche la prossimità geografica alle principali basi di utenti è importante — una farm negli Stati Uniti che serve un cliente europeo avrà una latenza maggiore rispetto a una con un punto di presenza europeo.
Monitoraggio e recupero errori
Su larga scala le cose si guastano costantemente. Una farm con centinaia di nodi si aspetta incidenti hardware quotidiani. La differenza tra una farm affidabile e una inaffidabile sta nel modo in cui i guasti vengono rilevati e gestiti.
Monitoraggio dello stato dei nodi. Ogni nodo di rendering comunica il proprio stato (temperatura CPU, utilizzo della memoria, utilizzo GPU, spazio su disco, throughput di rete) al sistema di gestione a intervalli regolari. I nodi che saltano i check-in vengono segnalati immediatamente. I nodi che mostrano pattern anomali (temperatura in aumento, throughput in calo) vengono rimossi preventivamente dal pool prima che si guastino durante un rendering.
Recupero a livello di frame. Quando un nodo si blocca durante il rendering, il frame che stava elaborando viene contrassegnato come fallito e riassegnato a un nodo funzionante. La farm tiene traccia di quali frame sono stati completati con successo, quali sono in corso e quali sono falliti. Questo tracciamento dello stato garantisce che nessun frame venga perso o duplicato, anche durante guasti a cascata dei nodi.
Gestione dei crash del motore di render. Oltre ai guasti hardware, i motori di render stessi possono andare in crash — condizioni di memoria esaurita, elementi della scena corrotti o bug del motore. La farm distingue tra crash recuperabili (ritenta su un nodo diverso con più RAM) e non recuperabili (il file della scena stesso ha un errore che farà crashare ogni nodo). Dopo un numero configurabile di tentativi, la farm segnala il guasto all'utente con informazioni diagnostiche invece di ritentare all'infinito.
Integrità dei dati. I frame renderizzati vengono sottoposti a checksum durante la scrittura. Se un problema di rete corrompe un frame durante il trasferimento allo storage, la discrepanza del checksum attiva un re-rendering automatico. Questo è particolarmente importante per i file EXR, dove un singolo byte corrotto può produrre artefatti visibili nel compositing.
Stack software della render farm
Il software che coordina tutto questo è tanto critico quanto l'hardware.
Render managers. Software di gestione del rendering appositamente sviluppati gestiscono la schedulazione dei lavori, l'allocazione dei nodi e l'amministrazione della farm. Questi sistemi sono progettati per le esigenze specifiche del rendering distribuito — tracciamento delle dipendenze a livello di frame, gestione delle versioni del motore per nodo e allocazione delle risorse multi-utente.
Strumenti di analisi della scena. Prima che un lavoro entri nella coda di rendering, gli strumenti di analisi esaminano il file della scena per identificare le dipendenze, stimare i requisiti di risorse e verificare gli errori comuni. Questi strumenti sono specifici per ogni motore — un analizzatore di scene V-Ray verifica problemi diversi rispetto a un analizzatore Blender Cycles.
Gestione delle versioni. Una farm di produzione mantiene simultaneamente più versioni di ciascun motore di render. Un utente potrebbe aver bisogno di V-Ray 6 per un progetto precedente mentre un altro richiede V-Ray 7. L'infrastruttura software della farm garantisce che ogni nodo carichi la versione corretta del motore per il lavoro assegnato, alternando tra le versioni man mano che diversi lavori si avvicendano.
Pannelli di controllo per il monitoraggio. Gli operatori della farm utilizzano pannelli di controllo in tempo reale che mostrano lo stato dei nodi, la profondità della coda, i lavori attivi, i tassi di completamento e le frequenze di errore. Questi pannelli consentono una risposta rapida ai problemi — se i tassi di errore aumentano improvvisamente su un particolare gruppo di nodi, l'operatore può indagare immediatamente invece di scoprire il problema ore dopo.
Come le farm completamente gestite si differenziano dalle piattaforme self-service
Non tutte le render farm funzionano allo stesso modo. Le due categorie principali — completamente gestite e self-service — gestiscono la pipeline in modo diverso.
Le farm completamente gestite (come Super Renders Farm) si occupano dell'intero stack tecnico. Carichi una scena, selezioni le impostazioni e la farm gestisce tutto il resto: installazione del software, gestione delle versioni, compatibilità dei plugin, recupero degli errori e consegna dell'output. Non devi accedere in remoto a nessuna macchina né gestire alcuna infrastruttura. Questo è importante perché la configurazione dei motori di render è complessa — solo V-Ray ha decine di impostazioni specifiche per versione che influenzano la compatibilità con la farm.
Le piattaforme self-service o IaaS ti noleggiano macchine virtuali con il software di rendering preinstallato. Ti connetti in remoto, configuri il software da solo, gestisci la tua coda di rendering e ti occupi del troubleshooting. Questo offre più controllo ma richiede competenze tecniche e un investimento di tempo significativamente maggiori.
Per un confronto dettagliato, la nostra guida al confronto tra rendering cloud gestito e fai-da-te analizza i pro e i contro.
La struttura dei costi dietro i prezzi delle render farm
Capire come funzionano le render farm significa anche capire cosa stai pagando.
Prezzi basati sulle risorse. La maggior parte delle farm applica tariffe basate sulle risorse di calcolo consumate — GHz-ore per il rendering CPU o OBs (unità di calcolo) per il rendering GPU. Puoi stimare i costi prima di impegnarti utilizzando strumenti come il nostro calcolatore dei costi. Questo significa che il tuo costo scala linearmente con le risorse utilizzate dal tuo lavoro. Un frame da 10 minuti su un nodo costa lo stesso che la farm abbia 10 altri lavori in esecuzione o 1.000 — paghi per ciò che consumi.
Costi infrastrutturali. Il prezzo per GHz-ora della render farm include non solo l'elettricità per far funzionare la CPU, ma anche i costi hardware ammortizzati, l'infrastruttura di storage, la larghezza di banda di rete, le licenze software (le licenze farm dei motori di render sono costose), il raffreddamento, la ridondanza e il team di ingegneri che mantiene tutto in funzione. Una parte significativa del costo copre il livello di affidabilità e comodità che ti risparmia la gestione di questa infrastruttura in prima persona.
Moltiplicatori di priorità. La priorità più alta costa di più perché garantisce accesso a più nodi simultaneamente, il che significa che gli altri lavori cedono risorse. Si tratta di un compromesso deliberato — le scadenze urgenti giustificano il sovrapprezzo.
Per un'analisi completa dei prezzi, consulta la nostra guida ai prezzi delle render farm.
Riepilogo: la pipeline della render farm
La pipeline completa, dall'invio alla consegna:
- Upload — file della scena e dipendenze trasferiti allo storage della farm
- Validazione — dipendenze verificate, impostazioni di rendering controllate, costo stimato
- Coda — il lavoro entra nella coda basata su priorità, in attesa dell'allocazione dei nodi
- Distribuzione — dati della scena resi disponibili ai nodi di rendering assegnati tramite storage di rete
- Rendering — i nodi CPU o GPU elaborano i frame assegnati in parallelo
- Controllo qualità — ogni frame validato (dimensione file, risoluzione, contenuto)
- Assemblaggio — frame organizzati, tile ricomposti se applicabile
- Consegna — frame completati disponibili per il download tramite storage con accelerazione CDN
Ogni passaggio ha modalità di guasto e ogni modalità di guasto ha un recupero automatizzato. Il risultato è un sistema che converte in modo affidabile i tuoi file di scena in frame renderizzati a velocità che nessuna singola workstation può eguagliare.
FAQ
Q: Quanto tempo impiega una render farm per elaborare un tipico lavoro di animazione? A: Dipende dalla complessità del frame e dal livello di priorità. Un'animazione archviz da 500 frame a 1080p con V-Ray si completa tipicamente in 2–6 ore su una farm rispetto a 3–7 giorni in locale. I lavori accelerati da GPU (Redshift, Cycles) sono spesso più veloci per frame ma limitati dalla VRAM per scene complesse.
Q: Cosa succede se un nodo di rendering si blocca durante il mio lavoro? A: Il gestore della coda della farm rileva il guasto in pochi secondi e riassegna il frame in corso a un nodo funzionante. Nessun frame viene perso. Se il crash è stato causato da un errore della scena (non dell'hardware), il sistema ritenta su una configurazione di nodo diversa prima di segnalarlo come problema lato utente.
Q: Devo installare il software di rendering sulla farm da solo? A: Sulle farm completamente gestite come Super Renders Farm, no. Manteniamo tutti i motori di render supportati (V-Ray, Corona, Arnold, Redshift, Cycles e altri) sulla nostra flotta di nodi, incluse più versioni per la compatibilità. Le piattaforme self-service possono richiedere la gestione dell'installazione del software in autonomia.
Q: Una render farm può gestire scene che superano la VRAM della mia GPU locale? A: Sì. I nodi di rendering CPU sulla nostra farm hanno 96–256 GB di RAM, in grado di gestire scene che sovraccaricherebbero la GPU di una workstation. Per i motori specifici per GPU, i nostri nodi RTX 5090 forniscono 32 GB di VRAM — più della maggior parte delle GPU desktop. Le scene che superano anche questo limite vengono indirizzate automaticamente ai nodi CPU.
Q: Come gestisce la farm le diverse versioni dei motori di render? A: Le farm di produzione mantengono simultaneamente più versioni di ciascun motore. Quando invii un lavoro, il sistema abbina la versione del motore della tua scena ai nodi compatibili. Se hai salvato la scena in V-Ray 6, viene renderizzata su nodi V-Ray 6 — non V-Ray 7, che potrebbe interpretare le impostazioni in modo diverso.
Q: I miei dati della scena sono al sicuro su una render farm? A: Le farm affidabili utilizzano trasferimenti crittografati (TLS/SSL per upload e download), storage con controllo degli accessi (i tuoi file sono isolati dagli altri utenti) e cancellazione automatica dei dati della scena dopo un periodo di conservazione. Sulla nostra farm, i file della scena vengono eliminati automaticamente dopo il completamento del lavoro più una finestra di conservazione configurabile.
Q: Quali formati di file dovrei usare quando invio a una render farm?
A: Utilizza il formato nativo del tuo DCC (.max per 3ds Max, .blend per Blender, .ma/.mb per Maya). Per l'output, specifica EXR per i flussi di lavoro di compositing o PNG per la consegna. Esegui sempre il rendering come sequenza di immagini, non come file video — se un frame fallisce, solo quel frame dovrà essere ri-renderizzato.
Q: Come gestiscono le render farm le dipendenze dei plugin come Forest Pack o Scatter? A: Le farm gestite mantengono i plugin comuni sulla loro flotta di nodi. Quando invii una scena che usa Forest Pack, la farm garantisce che i nodi assegnati al tuo lavoro abbiano la versione corretta di Forest Pack installata. I plugin meno comuni possono richiedere un preavviso affinché la farm possa distribuirli prima dell'esecuzione del tuo lavoro.
Letture di approfondimento
- Cos'è una render farm? — guida fondamentale ai concetti delle render farm
- Guida ai prezzi delle render farm — come funzionano i modelli di prezzo nel settore
- Cloud vs rendering locale — quando il rendering su farm ha senso rispetto al locale
- Autodesk Knowledge Network — Distributed Rendering — documentazione ufficiale sul rendering distribuito di 3ds Max (in inglese)
- Blender Manual — Render Output — configurazione dell'output di rendering di Blender (in inglese)
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



