
Cloud-Based Rendering vs Cloud Computing Rendering: Una Guida alle Differenze 2026
Panoramica
Introduzione
I risultati di ricerca per "cloud rendering" mescolano due cose genuinamente diverse. Una è il cloud-based rendering — servizi di rendering appositamente costruiti dove si carica un file di progetto e si ricevono i frame in output. L'altra è il cloud computing rendering — macchine virtuali di uso generale fornite da cloud provider che si configurano autonomamente per il rendering. Condividono gli stessi termini e gran parte dello stesso hardware, ma il flusso di lavoro, il modello di prezzo e i requisiti di competenza divergono nettamente non appena si inizia a usarli in produzione.
Abbiamo aiutato molti clienti a migrare in entrambe le direzioni nel corso degli anni — studi che passano da configurazioni DIY su AWS alla nostra pipeline gestita, e qualche team interno che ha fatto il percorso contrario per costruire qualcosa di personalizzato su Azure o Google Cloud. I compromessi sono abbastanza consistenti da averci spinto a scrivere questa guida per illustrarli chiaramente.
Questo articolo tratta la distinzione architetturale tra cloud-based rendering e cloud computing rendering, le categorie di vendor che si incontrano, dove ciascun modello si adatta al flusso di lavoro e al budget di team diversi, il calcolo dei costi che determina quale approccio fa risparmiare davvero, e le insidie più comuni nella migrazione da un modello all'altro.
Cloud-Based Rendering vs Cloud Computing Rendering — La Distinzione Fondamentale
I due termini vengono usati come sinonimi in post di blog, pagine di vendor e assistenti AI. Non lo sono.
Il cloud-based rendering descrive un'astrazione di servizio. Si interagisce attraverso un'interfaccia specifica per il rendering — un uploader desktop, una dashboard web, un'API che riceve il file di scena e restituisce i frame. L'infrastruttura sottostante è invisibile. Software, plugin, licenze, gestione della coda, selezione delle macchine, trasferimento dei file e gestione dei nodi sono tutti di responsabilità del vendor. Il risultato di cui ci si preoccupa sono i frame renderizzati; i passaggi intermedi sono gestiti dal sistema.
Il cloud computing rendering descrive l'accesso all'infrastruttura. Si noleggiano macchine virtuali (o istanze bare metal) da un cloud di uso generale — AWS EC2, Azure Virtual Machines, Google Compute Engine, o provider IaaS GPU specializzati — e le si gestisce autonomamente. Si installa Cinema 4D o Maya, si configura Redshift o V-Ray, si impostano i percorsi dei file, si esegue il proprio render manager, si monitora il job e si spegne tutto quando è terminato. Il cloud provider fornisce CPU/GPU/RAM/disco e una rete. Tutto ciò che è sopra il sistema operativo è a carico dell'utente.
Entrambi producono lo stesso risultato su disco. Il percorso per arrivarci è ciò che differisce.
| Aspetto | Cloud-based rendering | Cloud computing rendering |
|---|---|---|
| Unità primaria acquistata | Frame renderizzati o ore di rendering | Ore di macchina virtuale |
| Installazione software | A cura del vendor | A cura dell'utente |
| Licenze render engine | Incluse o gestite dal vendor | Portare la propria licenza |
| Trasferimento file | Uploader integrato / transito S3 | Configurazione a cura dell'utente |
| Scalabilità | Automatica sui nodi disponibili | Manuale o tramite script |
| Competenze richieste | Artista del rendering | Artista del rendering + cloud-ops engineer |
| Tempo al primo frame | Minuti dopo il caricamento | 30–90 minuti (build immagine, licenza, sincronizzazione file) |
| Fatturazione in inattività | Nessuna — si paga solo per il rendering attivo | Sì — la VM accumula ore finché non viene terminata |
La distinzione è importante perché la maggior parte delle decisioni sul "cloud rendering" sono in realtà decisioni su quale livello di astrazione si vuole gestire.
Distinzione Architetturale: Render Farm Gestita vs IaaS GPU Cloud
I servizi di cloud-based rendering e le piattaforme di cloud computing rendering non confezionano semplicemente il compute in modo diverso — sono costruiti per modelli operativi diversi.
Architettura della render farm cloud gestita (cloud-based):
Un operatore di render farm gestisce una flotta omogenea dietro una coda di job. Ogni nodo ha lo stesso software DCC pre-installato, le stesse licenze per i render engine, la stessa condivisione di rete e lo stesso agente di monitoraggio. Quando si invia un progetto, uno scheduler lo divide in task a livello di frame e li distribuisce a qualsiasi nodo disponibile nel pool. Non si scelgono le macchine; è il pool a scegliere.
Sulla nostra render farm, quel pool include oltre 20.000 core CPU nella flotta CPU, più macchine GPU dedicate con NVIDIA RTX 5090 (32 GB di VRAM ciascuna). I file di progetto transitano tramite AWS S3 tra la propria macchina e i nodi di rendering — S3 qui è solo un livello di trasporto, non il compute. Il compute è locale a una regione di rendering (la nostra si trova ad Hà Nội), il che mantiene bassa la latenza tra frame e semplifica la gestione delle licenze. In quanto partner ufficiale Maxon e render partner di Chaos Group, gestiamo le licenze dei render engine lato farm.
Super Renders Farm opera secondo questo modello gestito — una render farm GPU e CPU in cui la coda, la selezione dei nodi e le licenze restano sul lato operatore anziché sul proprio.
Architettura IaaS GPU cloud (cloud computing rendering):
Un provider IaaS GPU fornisce un'istanza Linux o Windows vuota con una GPU collegata. AWS, Azure e Google offrono tutti istanze GPU; provider specializzati come CoreWeave, RunPod, Lambda e Vast.ai competono su prezzo e velocità di provisioning. Nessuno di loro sa cosa sia Redshift. Non gli interessa se si sta renderizzando, addestrando un modello o transcodificando video.
Ci si assume la responsabilità di: costruire o trovare un'immagine macchina con il proprio DCC + render engine installato, collegare un license server o spostare licenze node-locked, montare lo storage (block storage, object storage o NFS), copiare la propria scena e gli asset in quello storage, eseguire il render manager (Deadline, Royal Render, uno script personalizzato o semplicemente redshiftCmdLine), monitorare i fallimenti e smantellare tutto prima che le ore di inattività inizino ad accumularsi.
La differenza di astrazione è reale. Una render farm cloud-based nasconde l'80% delle scelte infrastrutturali. Un IaaS GPU cloud le espone tutte.
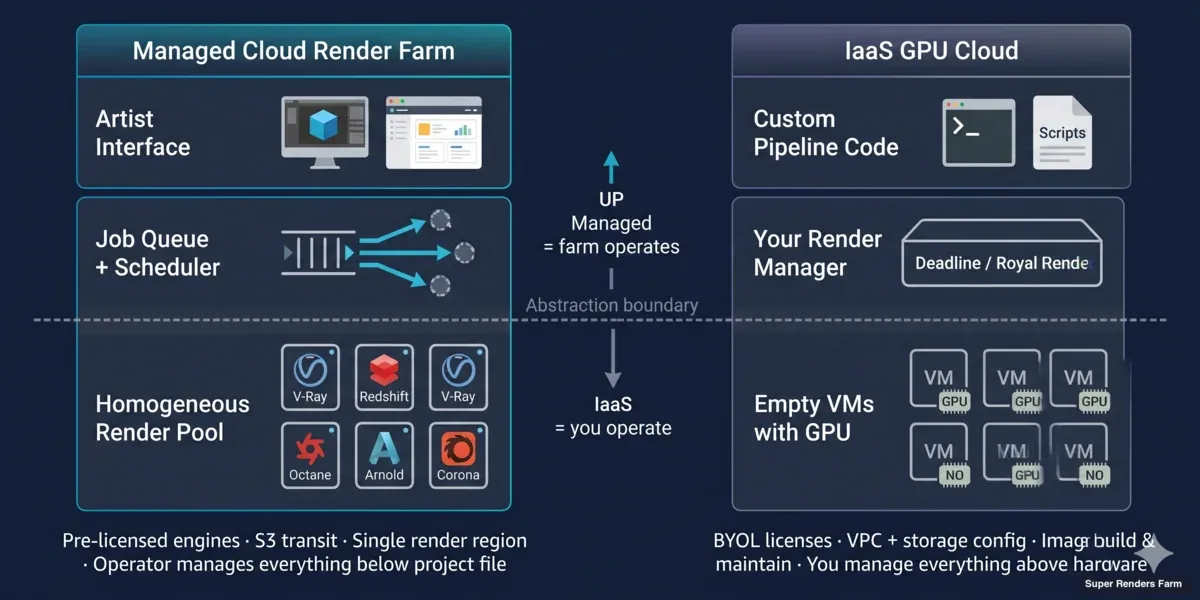
Layered architecture diagram comparing managed cloud render farm operations versus IaaS GPU cloud rendering operational responsibilities
Quando il Cloud-Based Rendering è la Scelta Giusta
Il modello a servizio gestito si adatta ai team il cui valore risiede nel risultato creativo e il cui tempo è meglio speso nel DCC, non nel DevOps.
Super Renders Farm è una delle opzioni di render farm gestita in questa categoria; gli stessi compromessi descritti di seguito valgono per qualsiasi vendor che adotti l'astrazione cloud-based.
Freelancer indipendenti e studi di motion design / archviz da 1 a 3 persone. Configurare una pipeline IaaS GPU multi-nodo diventa conveniente forse a partire da 100+ ore di rendering al mese, se il team ha le competenze cloud in-house. Al di sotto di quella soglia, il carico operativo — manutenzione delle immagini, uptime del license server, sorprese in fattura — erode i risparmi.
Studi con pipeline orientate alle scadenze. Quando un cliente anticipa una consegna di due giorni, una render farm gestita scala il job in corso regolando la priorità. Con IaaS, bisognerebbe eseguire il provisioning di istanze aggiuntive, copiare gli asset, configurarle e integrarle nel proprio render manager — magari in tempo, magari no.
Team che usano render engine commerciali senza licenze a volume. Redshift, V-Ray, Corona, Octane e Arnold hanno termini di licenza per nodi di rendering che diventano costosi nella gestione autonoma. Il nostro modello include quelle licenze nel costo per frame o per GHz-ora; con IaaS si porta la propria licenza e si consumano i node-lock.
Produzioni dove una notte andata male compromette la scadenza. Una render farm gestita ha personale di supporto che ha già visto la maggior parte dei modi in cui le cose vanno storte e può intervenire su un job durante il rendering. Con IaaS, risolvere un rendering bloccato alle 2 di notte è un problema da affrontare da soli.
Il compromesso è la flessibilità. Una render farm gestita esegue i render engine e le versioni dei plugin che ha testato. Se il progetto dipende da un plugin nuovo che non è ancora stato aggiunto, si deve aspettare che il supporto lo verifichi. Con IaaS si installa quello che si vuole.
Quando il Cloud Computing Rendering è la Scelta Giusta
Il modello IaaS si adatta ai team la cui pipeline è essa stessa il prodotto, o le cui esigenze di rendering si trovano ben al di fuori di ciò che il catalogo di una render farm gestita copre.
Team con pipeline di rendering personalizzate o proprietarie. Se si è costruito un renderer interno, si è modificato un motore open source, o si gestisce una pipeline distribuita non standard con dipendenze personalizzate, nessuna render farm gestita potrà assorbirla dall'oggi al domani. Noleggiare compute grezzo e orchestrare via script è l'unica opzione.
Ibridi ML-rendering. I team che lavorano con Gaussian splatting, neural radiance field, pipeline AI di denoising, o che addestrano i propri modelli parallelamente al rendering traggono vantaggio dal possedere l'intero stack. La stessa istanza GPU che renderizza un frame può eseguire un job di inferenza tra un rendering e l'altro. Le render farm gestite non espongono quella flessibilità.
Studi con cloud-ops interni e artisti a proprio agio con Linux. Quando il team interno gestisce già AWS, Azure o Google Cloud per altri carichi di lavoro, aggiungere una pipeline di rendering riutilizza competenze, fatturazione e perimetri di sicurezza già esistenti.
Carichi di lavoro che non si adattano al modello di fatturazione di una render farm. Alcune pipeline richiedono sessioni interattive prolungate (ad esempio, un tech artist che itera su una scena pesante con anteprima live), che non si mappano bene sulla fatturazione per frame. Noleggiare un'istanza per la giornata è più conveniente che forzare il modello.
Il compromesso è il costo operativo. Si gestisce ora una piccola pratica di render management in aggiunta alla pratica creativa. Questo è un costo reale.
Confronto dei Costi: Cloud-Based vs Cloud Computing Rendering
Entrambi i modelli pubblicizzano tariffe orarie basse, ma il costo totale si concretizza in modo molto diverso una volta incluso tutto ciò che deve funzionare affinché un rendering arrivi a termine.
Cloud-based rendering (per frame o per GHz-ora):
Si paga il tempo di rendering attivo. I costi delle licenze, le macchine in inattività, gli aggiornamenti software, il supporto e lo storage durante il job sono inclusi nella tariffa. Una tipica animazione di motion design da 720 frame a 1 minuto per frame su hardware GPU costa approssimativamente $15–$30 sulla nostra render farm alla priorità standard. Un'animazione archviz da 1.500 frame a 3 minuti per frame su CPU costa approssimativamente $80–$150. Non ci sono sorprese — si vede una stima prima che il job parta e un riepilogo finale al termine.
Cloud computing rendering (per VM-ora + tutto il resto):
La tariffa principale è quella dell'istanza GPU. Le istanze AWS p5 (H100), Azure NDv5 e Google A3 costano approssimativamente $5–$30 all'ora a seconda della configurazione. I cloud GPU specializzati pubblicizzano costi inferiori — CoreWeave, RunPod e Vast.ai si attestano intorno a $0,40–$2,50 all'ora per GPU di fascia consumer.
La tariffa dell'istanza è solo il punto di partenza. Si aggiunge: il trasferimento dati in uscita ($0,05–$0,09/GB su AWS — un progetto da 50 GB recuperato come 100 GB di sequenza EXR è un costo reale), lo storage a oggetti ($0,023/GB-mese in attesa), il tempo di provisioning (30–90 minuti di ore a pagamento prima che il primo frame venga renderizzato), i costi delle licenze (nodi Redshift ~$45/mese per seat, nodi V-Ray intorno a $42/mese ciascuno — fatturati indipendentemente dall'utilizzo), e il server delle licenze se si usa BYOL. Se il costo interno del team per le ore di engineering è $80–$150 all'ora, ogni ora di debug cloud-ops si aggiunge al totale.
Per un confronto equo, guidiamo i team attraverso il confronto costi render farm vs in-house e i modelli di prezzo per render farm prima di decidere. Le tariffe di base mentono. La tariffa oraria che sembra del 60% più bassa su IaaS si avvicina spesso al 10–15% di differenza una volta incluse licenze, trasferimento, inattività e tempo operativo — e questo è prima di qualsiasi evento di rischio legato alle scadenze.

Stacked bar infographic comparing total cost composition between cloud-based render farm pricing and IaaS GPU cloud rendering with hidden costs flagged
Categorie di Vendor: Render Farm Cloud Gestite vs IaaS GPU Cloud vs Ibridi
Il panorama dei vendor si divide chiaramente lungo la linea dell'astrazione, con un piccolo gruppo intermedio:
Render farm cloud puramente gestite. I vendor in questa categoria gestiscono i propri pool di rendering omogenei, prelicenziano i render engine e espongono un'interfaccia specifica per il rendering. L'operatore gestisce ogni livello sotto il file di progetto. Il prezzo è per frame, per ora di rendering o per GHz-ora — mai per VM-ora. Flusso di lavoro tipico: installa l'app desktop → carica il progetto → rendering → download.
IaaS GPU cloud puri. AWS, Azure, Google Compute Engine, oltre a provider specializzati (CoreWeave, RunPod, Lambda, Paperspace, Vast.ai). Vendono macchine virtuali con GPU collegate. Alcuni pubblicano immagini DCC tramite marketplace, ma il modello operativo resta "noleggia la macchina, esegui il tuo software."
Piattaforme ibride. Un piccolo livello intermedio offre orchestrazione gestita su IaaS — ad esempio, servizi che eseguono il provisioning di istanze AWS, installano il render engine tramite una procedura guidata e distribuiscono i job tra di esse. Questi riducono parte del lavoro di configurazione ma non eliminano la gestione delle licenze né la dipendenza dalle fluttuazioni di prezzo del cloud provider di terze parti. Sono utili quando un team interno dispone di account e crediti cloud ma non ha esperienza nella pipeline di rendering.
La categoria di vendor giusta dipende interamente dall'astrazione che si vuole effettivamente gestire. I team a volte scelgono il livello sbagliato — ad esempio, scegliendo IaaS per "risparmiare" senza considerare il tempo di cloud-ops nel budget, oppure scegliendo una render farm gestita e tentando poi di installare plugin personalizzati attraverso di essa. La maggior parte dei problemi di pipeline che vediamo deriva dalla scelta di un vendor il cui modello non corrisponde alla realtà operativa del team.
Percorso di Migrazione: Passare tra Cloud-Based e Cloud Computing Rendering
I team migrano in entrambe le direzioni. I modelli che vediamo più spesso:
Rendering DIY su AWS → render farm cloud gestita.
Causa più comune: uno studio piccolo ha configurato una pipeline Spot Instance + Deadline un anno fa, l'ingegnere che l'ha costruita se n'è andato, e ora il team non riesce a completare una notte di rendering senza un'interruzione. La migrazione è di solito rapida — qualche ora per installare l'app desktop, validare la preparazione della scena ed eseguire un rendering di test. La parte più delicata è dismettere con cura la vecchia pipeline (cancellare le istanze riservate, archiviare eventuali Spot AMI create dal team, esportare i rendering precedenti da S3 prima che le bucket policy cambino).
Render farm cloud gestita → pipeline IaaS personalizzata.
Causa più comune: lo studio è cresciuto, ha assunto un render-pipeline engineer, e ha scoperto che il proprio flusso di lavoro ha superato ciò che il catalogo di qualsiasi operatore di render farm copre — passaggi AOV personalizzati, script post-rendering proprietari, o integrazione con un asset DB interno. La migrazione è impegnativa: bisogna costruire e mantenere immagini DCC, configurare un license server, scegliere un render manager, progettare il layout dello storage, scrivere il monitoraggio. Si calcoli in settimane, non giorni, e si consideri che i primi tre mesi costeranno più della precedente fattura della render farm, prima che l'ottimizzazione recuperi il terreno.
Ibrido (carico di lavoro diviso).
Alcuni studi usano entrambi: render farm gestita per il lavoro quotidiano con i clienti dove l'affidabilità è essenziale, IaaS per pipeline sperimentali o proprietarie dove la flessibilità è prioritaria. La doppia fattura è scomoda, ma la corrispondenza operativa è buona.
Errori Comuni nella Configurazione del Cloud Computing Rendering
La maggior parte dei progetti di cloud computing rendering fallisce negli stessi pochi punti. Se si sceglie la strada IaaS, i risparmi sono reali solo se si evitano questi problemi.
Sottostimare i costi di trasferimento. Le tariffe per i dati in uscita ($0,05–$0,09/GB su AWS, simili su Azure/GCP) si accumulano rapidamente con le sequenze EXR. Un'animazione 4K può produrre centinaia di GB. Abbiamo visto team pianificare un budget di rendering di $400 e ricevere una fattura di $1.200 perché non avevano calcolato l'egress.
Dimenticare le ore di inattività. Un'istanza GPU lasciata in esecuzione per un weekend perché l'operatore ha dimenticato di terminarla costa quanto il rendering stesso. Le Spot Instance attenuano questo rischio ma introducono il rischio di interruzione a metà rendering se il prezzo spot si muove.
Sottovalutare il tempo di build delle immagini. Costruire un'immagine funzionante di DCC + render engine + plugin richiede 1–3 giorni di tempo di engineering la prima volta, più manutenzione continua ad ogni ciclo di release. I team calcolano la fattura cloud ma non le ore di manutenzione delle immagini.
Fragilità del license server. Le licenze floating tunnelizzate attraverso una VPC verso istanze effimere si guastano in modi che sembrano bug di rendering. Allocare licenze dedicate fisse risolve il problema ma aumenta i costi.
Errori nella scelta dello storage. Montare object storage direttamente in un rendering causa picchi di latenza I/O. Il block storage è più veloce ma ha limiti di dimensione e localizzazione. La maggior parte delle pipeline IaaS esperte usa un approccio ibrido (object per l'archivio, block per il set di lavoro attivo del job), che aggiunge un'ulteriore superficie di configurazione.
Divergenza dei percorsi file. Una scena Cinema 4D o Maya creata su una workstation Windows spesso fa riferimento a percorsi assoluti o lettere di unità locali che non esistono su un'istanza di rendering Linux. La rimappatura dei percorsi è la causa più comune di errori "texture mancante".
Questi problemi non compaiono sulle render farm gestite perché l'operatore li gestisce centralmente. Sono il costo operativo che accompagna il modello IaaS.
Framework Decisionale: Quale Modello Scegliere
Una breve checklist per indirizzare la maggior parte dei team verso il livello corretto:
Scegliere il cloud-based rendering (render farm gestita) se:
- Si eseguono meno di ~100 ore di rendering al mese
- Il team è composto da 1 a 5 persone focalizzate sul risultato creativo
- Si usano render engine commerciali standard (V-Ray, Corona, Arnold, Redshift, Octane, Cycles)
- Non si dispone di un cloud-ops engineer dedicato
- L'affidabilità rispetto alle scadenze è più importante della flessibilità di fatturazione
Scegliere il cloud computing rendering (IaaS GPU) se:
- Si dispone di una pipeline di rendering personalizzata o non standard
- Il team include qualcuno con esperienza cloud-ops attiva
- È necessaria una stretta integrazione con altri carichi di lavoro cloud (ML, asset DB interni, servizi personalizzati)
- Il carico di lavoro include sessioni interattive prolungate, non solo batch di frame
- Si può includere nel budget il tempo di engineering per operare la pipeline
Considerare un approccio ibrido se:
- Il lavoro quotidiano con i clienti è su render engine standard e con scadenze critiche (gestito)
- Il lavoro R&D o sperimentale è personalizzato (IaaS)
- I due non si sovrappongono mai sullo stesso progetto
Per la maggior parte degli studi con cui lavoriamo, il modello a render farm gestita vince sul costo totale perché il costo operativo di IaaS è sistematicamente sottostimato.
È questo il ragionamento alla base di un servizio gestito come Super Renders Farm: la tariffa per frame e per GHz-ora assorbe l'onere di licenze, inattività e supporto che un budget IaaS deve sostenere separatamente. Per il ~10–15% dei team che dispone effettivamente della capacità di engineering e di un carico di lavoro non standard, IaaS è la risposta giusta. Il restante 10% si trova nella corsia ibrida.
Se si sta dimensionando il lato budget di questa decisione, il calcolatore dei costi fornisce una stima per progetto in base alle nostre tariffe di render farm gestita. Confrontare quella stima con un budget IaaS onesto — inclusi licenze, trasferimento, inattività e tempo operativo — è l'unico modo equo per decidere. Per un contesto più ampio su come funziona il rendering distribuito in entrambi i modelli, la guida al cloud rendering copre l'architettura di base, e il confronto tra rendering cloud gestito e DIY approfondisce i compromessi operativi che vediamo più spesso.
FAQ
Q: Qual è la differenza tra cloud-based rendering e cloud computing rendering? A: Il cloud-based rendering è un'astrazione di servizio — si carica un progetto su una piattaforma specifica per il rendering e si ricevono i frame renderizzati, con il vendor che gestisce software, licenze e infrastruttura. Il cloud computing rendering è accesso all'infrastruttura — si noleggiano macchine virtuali da un cloud provider di uso generale e si configurano autonomamente. Lo stesso risultato su disco; percorsi molto diversi per arrivarci.
Q: Il cloud computing rendering è sempre più economico di una render farm cloud gestita? A: In pratica, no. La tariffa VM-ora su AWS, Azure o cloud GPU specializzati sembra spesso inferiore, ma il costo totale deve includere le licenze per i render engine, le tariffe di trasferimento dati in uscita, lo storage, il tempo di provisioning prima del primo frame, la manutenzione delle immagini e le ore di engineering per gestire la pipeline. Una volta inclusi, il divario si riduce tipicamente al 10–15% per i carichi di lavoro standard. IaaS vince sui costi solo quando i team dispongono di capacità cloud-ops esistente e possono assorbire il carico operativo.
Q: Posso usare AWS o Azure per il rendering invece di una render farm? A: Sì, e molti team lo fanno — ma richiede un set di competenze diverso. Bisogna installare il proprio DCC e render engine, gestire le licenze, configurare storage e networking, costruire immagini macchina riutilizzabili e gestire un render manager. Conviene per team con pipeline personalizzate, ibridi ML-rendering o esperienza cloud-ops interna. Per i flussi di lavoro standard su render engine commerciali, una render farm cloud gestita comporta di solito meno lavoro e un costo totale simile.
Q: Cos'è una render farm cloud gestita e in cosa differisce da un IaaS GPU cloud? A: Una render farm cloud gestita gestisce una flotta omogenea di nodi di rendering pre-configurati dietro una coda di job. Si carica un progetto, il sistema pianifica i frame sui nodi disponibili e si ricevono i risultati. Un IaaS GPU cloud vende macchine virtuali vuote con GPU collegate — nessun software DCC, nessun render engine, nessuno scheduler, nessuna licenza inclusa. Il modello render farm scambia flessibilità per semplicità operativa; il modello IaaS scambia semplicità per flessibilità.
Super Renders Farm è un esempio del lato render farm gestita di questa separazione — si invia un progetto e si ricevono i frame, con i render engine, le licenze e la pianificazione gestiti lato farm.
Q: Quando dovrei migrare dal rendering cloud DIY su AWS a una render farm gestita? A: Le cause più comuni che vediamo: l'ingegnere che ha costruito la pipeline originale se n'è andato e il team non riesce a tenerla in funzione, la fattura cloud è cresciuta oltre il costo del lavoro equivalente su render farm gestita, i job critici per le scadenze hanno iniziato a fallire nelle ore notturne, o il team si è reso conto di spendere più tempo in cloud-ops che nel lavoro creativo. La migrazione in sé è di solito rapida — installazione dell'app desktop, preparazione della scena e un rendering di test — ma si pianifichi il tempo per dismettere con cura la vecchia infrastruttura AWS in modo da non continuare a pagarla.
Q: Devo portare la mia licenza del render engine su una render farm cloud? A: Per la maggior parte delle render farm cloud gestite che operano sotto partnership ufficiali, no — le licenze per V-Ray, Corona, Arnold, Redshift, Octane e Cycles sono incluse nella tariffa. Sui cloud IaaS GPU si porta quasi sempre la propria licenza, o node-locked a istanze specifiche (più economico ma poco flessibile) o floating tramite un license server (flessibile ma operativamente fragile). La gestione delle licenze è uno dei costi nascosti più rilevanti del cloud rendering autogestito.
Q: Su quale hardware operano tipicamente i servizi di cloud-based rendering? A: Le render farm cloud moderne dispongono di un mix di hardware CPU e GPU dimensionato per il rendering in produzione. La nostra render farm in particolare opera con oltre 20.000 core CPU per render engine come V-Ray, Corona e Arnold, più macchine GPU dedicate con NVIDIA RTX 5090 (32 GB VRAM) per Redshift, Octane e V-Ray GPU.
Super Renders Farm dimensiona quella flotta per il rendering in produzione anziché per il calcolo di uso generale, ed è questa la differenza pratica rispetto a un'istanza GPU IaaS che deve essere configurata per ogni job. I cloud IaaS GPU offrono una gamma più ampia — dalle RTX 4090 consumer alle H100 data-center — con punti di prezzo molto diversi. Per il rendering commerciale, le GPU di fascia RTX sono di solito il punto di equilibrio ottimale tra prezzo e prestazioni, indipendentemente dal modello.
Q: Posso eseguire il rendering interattivo o con anteprima live su una render farm cloud? A: Le render farm cloud gestite sono ottimizzate per carichi di lavoro batch — si invia un progetto, si renderizzano i frame, si consegnano i risultati. Il rendering interattivo con feedback IPR live è territorio della workstation, non della render farm. Se si ha bisogno di sessioni interattive prolungate nel cloud, un'istanza IaaS GPU con accesso desktop remoto è la forma giusta — ma questo è cloud computing rendering, non cloud-based rendering. I due modelli risolvono genuinamente problemi diversi.
About Alice Harper
Blender and V-Ray specialist. Passionate about optimizing render workflows, sharing tips, and educating the 3D community to achieve photorealistic results faster.



