Cómo desplegar una render farm GPU dedicada de 20 nodos en múltiples países (2026)
Resumen
Introducción
Cuando un equipo creativo solicita una render farm dedicada que abarque varios países, normalmente está trabajando con una restricción que una render farm SaaS no puede resolver. Puede tratarse de un estudio que contractualmente no puede permitir que un tercero tenga acceso a sus credenciales, un equipo distribuido donde los artistas de un país operan nodos en otro, o una productora cuyo contrato de varios meses hace que la facturación por fotograma resulte económicamente poco rentable.
En nuestra experiencia, la parte difícil raramente es "alquilar más GPU." El reto es conectar las piezas correctas: almacenamiento en la nube propiedad del cliente, una flota de GPU privada dimensionada para la carga de trabajo, transporte cifrado entre fronteras que soporte la fluctuación de red y una capa de escritorio remoto que no colapse con un viewport 3D pesado. Cuando una pieza falla, el clúster funciona, pero los artistas lo notan, y el contrato se degrada silenciosamente.
Operamos Super Renders Farm, una cloud render farm con una flota sustancial de CPU y GPU, y también ponemos en marcha clústeres GPU dedicados para equipos cuyos flujos de trabajo no se adaptan a nuestro servicio gestionado. Este artículo es una guía práctica basada en esos despliegues: cómo arquitecturamos una render farm GPU dedicada de 20 nodos para un equipo creativo distribuido de artistas en múltiples países desde una única instalación dedicada, con notas honestas sobre las decisiones que tomamos, las que deshicimos y las lecciones que ahora aplicamos por defecto. Si está evaluando infraestructura dedicada frente a nuestra render farm gestionada en alquiler, esta guía le ayudará a decidir si la ruta dedicada merece la complejidad arquitectónica.
Criterios de decisión: dedicada frente a SaaS
La mayoría de las cargas de trabajo de renderizado no necesitan un clúster dedicado. Una cloud render farm gestionada envía una escena, programa los fotogramas y factura por minuto. No hay infraestructura que poseer, ningún firewall que mantener y ningún equipo operativo que asignar en el lado del cliente. Para trabajos por proyecto —un corto, un anuncio de 30 segundos, un lote de imágenes estáticas— ese modelo gana en todos los ejes que importan.
Un clúster dedicado solo justifica su complejidad cuando se cumple una o más de las siguientes condiciones:
- El control de la propiedad intelectual es contractual, no preferencial. El acuerdo de servicios principales del cliente o el contrato del cliente final prohíbe que un tercero tenga en su poder archivos de escena o credenciales de renderizado. Las canalizaciones SaaS que median la carga de escenas incumplen esta restricción aunque el cómputo subyacente sea idéntico.
- El contrato dura meses, no días. El trabajo de forma fija —una serie animada de larga duración, una canalización de archviz durante varios trimestres, un escenario de producción virtual continuo— amortiza el coste inicial de arquitectura. La facturación por fotograma, en cambio, se multiplica linealmente con la duración y deja de ser competitiva a partir de cierto horizonte temporal.
- El flujo de trabajo es lo suficientemente personalizado como para que una canalización gestionada no pueda alojarlo. Pilas de plugins DCC personalizados, gestores de render propios, canalizaciones con mucha simulación que pre-procesan en una caché compartida o cadenas de herramientas propietarias apuntan hacia nodos dedicados que el cliente puede configurar directamente.
- Traer la propia nube es un requisito estricto. Cuando los activos del proyecto del cliente residen en una plataforma de streaming de archivos en la nube bajo la cuenta del cliente, el clúster debe iniciar sesión como el cliente, no como el proveedor de infraestructura. Este es el patrón "Modelo B" que se analiza en detalle más adelante.
- Las necesidades de segmentación de red van más allá de una VLAN por inquilino. Algunos flujos de trabajo requieren que el clúster sea invisible para la red general del proveedor, no solo aislado lógicamente, sino también aislado por rutas.
Si ninguno de estos criterios se aplica, una render farm gestionada es la elección correcta. Si se aplican dos o más, la conversación se orienta hacia la dedicada. La pregunta restante es geográfica: ¿los artistas que impulsan el trabajo están cerca de la instalación, o el clúster necesita servirlos a través de una red ISP pública que cruza fronteras nacionales?
Descripción general de la arquitectura
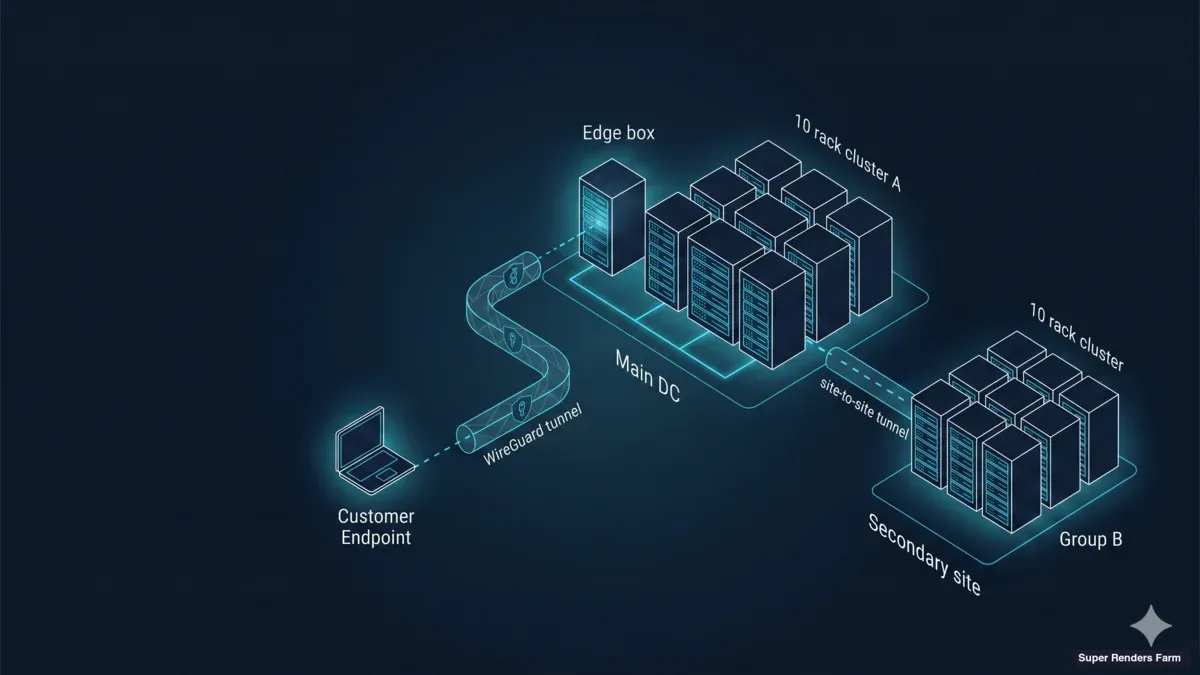
La arquitectura que desplegamos para clústeres dedicados entre países tiene tres planos: un plano de transporte, un plano de cómputo y un plano de aceleración de almacenamiento. Cada plano tiene un único modo de fallo que, en nuestra experiencia, explica la mayor parte del dolor operativo cuando falla.
[ Artistas remotos — distribuidos por países ]
│
│ WireGuard hub-and-spoke
│ (UDP 51820, cifrado end-to-end,
│ transporte BBR + MSS-clamped)
▼
┌─────────────────────────────────────────────────────┐
│ Super Renders Farm — instalación de clúster dedicado │
│ │
│ ┌─────────────────────────────────────────────┐ │
│ │ EDGE + CACHE BOX (host Ubuntu único) │ │
│ │ • Hub WireGuard (NAT/MASQUERADE) │ │
│ │ • Caché Samba SMB3 (SSD único, ext4) │ │
│ │ • dnsmasq (zona .lan) │ │
│ │ • chrony (NTP) │ │
│ │ • ufw + BBR + TCP MSS clamp │ │
│ └────────────────────┬────────────────────────┘ │
│ │ LAN │
│ ┌────────────────────▼────────────────────────┐ │
│ │ 20 × nodos de render RTX 5090 │ │
│ │ (Windows 11 Pro, Sunshine, cliente de │ │
│ │ streaming de archivos en la nube, montaje │ │
│ │ de caché — imagen uniforme en toda │ │
│ │ la flota) │ │
│ └─────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
│
▼
[ Plataforma de streaming de archivos en la nube del
cliente — el cliente inicia sesión en cada nodo;
Super Renders Farm no tiene las credenciales (Modelo B) ]
El plano de transporte es WireGuard, en un patrón hub-and-spoke. La estación de trabajo de cada artista se conecta al hub en la instalación del clúster a través de un túnel UDP cifrado; todo el tráfico entre el artista y el clúster, independientemente del país donde se encuentre el artista, atraviesa la misma topología de túnel. El plano de cómputo son veinte nodos Windows 11 Pro, cada uno con una sola NVIDIA RTX 5090 con 32 GB de VRAM, desplegados como un único grupo uniforme en una instalación. El plano de aceleración de almacenamiento es una caja de borde y caché única en la instalación que aloja un recurso compartido Samba SMB3 respaldado por un único SSD en ext4, junto con los servicios de red de los que depende el clúster (DNS, NTP, firewall).
Una decisión de diseño clave: la caja de borde y la caja de caché son la misma máquina. Una versión anterior de esta arquitectura ponía la puerta de enlace de borde en un dispositivo separado y la caché en un NAS, lo que creaba condiciones de carrera durante las extracciones en frío y dos superficies para parchear. La consolidación en un único host Ubuntu 22.04 LTS eliminó ambos problemas. La caja se convierte en un recurso crítico, pero los datos del proyecto del cliente siguen viviendo en la plataforma de streaming de archivos en la nube, por lo que la caché se recalienta desde el origen tras cualquier fallo local.
Configuración del clúster GPU de 20 nodos
El dimensionamiento predeterminado para los despliegues que describimos son veinte nodos RTX 5090, desplegados como un único grupo uniforme dentro de una instalación. Este es el tamaño que consistentemente se adapta bien a un equipo creativo en el rango de diez a veinte artistas, que es la banda donde los clústeres dedicados se amortizan para flujos de trabajo sensibles a la propiedad intelectual.
Cada nodo tiene la misma forma de hardware: una sola RTX 5090 con 32 GB de VRAM, una CPU moderna de múltiples núcleos, 64 GB o 128 GB de RAM del sistema y un disco NVMe local dimensionado solo para el sistema operativo y el almacenamiento temporal. Los datos persistentes del proyecto residen en la caché compartida o en la plataforma de streaming de archivos en la nube del origen, nunca en el propio nodo.
El sistema operativo de cada nodo es Windows 11 Pro, desplegado desde una imagen limpia. Deliberadamente no pre-cargamos pilas de plugins DCC en la imagen del nodo. El cliente impulsa la instalación de sus propias herramientas DCC —Cinema 4D, Redshift, Houdini, After Effects, Blender y otras— para que la imagen del nodo se mantenga mínima y reproducible. Cuando el contrato termina, borramos y reimaginamos desde la misma base limpia.
Elegimos deliberadamente 32 GB de VRAM por nodo. Los motores de renderizado GPU modernos —Redshift, Octane, Arnold GPU, Cycles— cargan cada vez más escenas con texturas grandes que simplemente no caben en tarjetas de 24 GB. La RTX 5090 con 32 GB es actualmente el punto óptimo para los motores de renderizado en producción; gestiona la mayor parte del trabajo de archviz, motion design y animación sin paginar a la RAM del sistema, que es donde los grupos de GPU mixtos se vuelven silenciosamente lentos.
Los veinte nodos están configurados de forma idéntica —misma imagen, mismo conjunto de instalación DCC, mismo montaje de caché, misma ruta WireGuard— y se presentan como un único grupo al gestor de render del cliente. Deadline, Royal Render o el planificador propio del cliente trata la flota como un único recurso sin ninguna lógica de enrutamiento por grupo ni reequilibrado manual. Los fotogramas se asignan al nodo que esté libre; el gestor de render del cliente gestiona la distribución de la carga en la capa de cola de trabajos.
La flota es enrutable en capa 3: el cliente instala su propio gestor de render y envía trabajos desde una estación de trabajo remota en lugar de operar cada nodo a través de escritorio remoto. Esto importa más de lo que se podría esperar: es la diferencia entre un clúster con el que los artistas luchan y uno que los artistas olvidan.
Credenciales propiedad del cliente (Modelo B)
La única decisión arquitectónica que con más frecuencia hace que un clúster dedicado sea la respuesta correcta para flujos de trabajo sensibles a la propiedad intelectual es lo que llamamos Modelo B: credenciales propiedad del cliente. En el Modelo A —el predeterminado para las render farms gestionadas, incluido nuestro propio servicio SaaS— el proveedor de infraestructura tiene las credenciales de la canalización de renderizado. El cliente carga los archivos de escena; la canalización del proveedor media el renderizado. Esto funciona para la gran mayoría de las cargas de trabajo y es el modelo detrás de casi todas las cloud render farms comerciales.
En el Modelo B, el proveedor de infraestructura suministra hardware, sistema operativo, red y la capa de caché, pero nunca tiene en su poder el material de autenticación del cliente para la plataforma de streaming de archivos en la nube ni para los datos de origen del proyecto. El cliente inicia sesión en la plataforma en la nube en cada nodo, exactamente como si estuviera sentado frente a su propia estación de trabajo. Los archivos del proyecto se transmiten desde la nube del cliente. Los renders se devuelven a la nube del cliente. El rol del proveedor está limitado a la capa de hardware y canalización.
Esto importa por tres razones:
- Contractual: Cuando el cliente final del cliente tiene un NDA o un acuerdo de servicios principales que restringe dónde se pueden tener las credenciales y los archivos de origen, el Modelo B mantiene al proveedor fuera del alcance de esas restricciones. El cliente no necesita negociar la inclusión del proveedor de renderizado en una cadena contractual que no fue diseñada para ello.
- Auditoría: Cuando el cliente necesita demostrar a un auditor de seguridad que su canalización de renderizado no expone las credenciales a un tercero, el Modelo B le da una respuesta clara. El proveedor puede producir documentación de hardware, red y operaciones; el cliente produce la cadena de credenciales.
- Cierre al final del contrato: Dado que el proveedor nunca tuvo las credenciales, el cierre al final del contrato es más sencillo. El cliente revoca sus propias sesiones en la nube; el proveedor borra la caché, reimagina los nodos y proporciona una certificación escrita de que la caché y las imágenes de los nodos han sido destruidas. No hay ningún paso de rotación de credenciales que el proveedor deba certificar porque nunca se tuvieron credenciales.
El Modelo B no es para todos. Pone al equipo de operaciones del cliente a cargo del ciclo de vida de las credenciales en cada nodo: veinte rotaciones para coordinar si los secretos rotan mensualmente. Los equipos que ya tienen esa práctica operativa encuentran el equilibrio aceptable. Los que no la tienen tienden a quedarse en el renderizado gestionado del Modelo A.
Integración del streaming de archivos en la nube
En las configuraciones que analizamos, los activos del proyecto del cliente residen en una plataforma de streaming de archivos en la nube, un servicio que expone el árbol del proyecto respaldado en la nube como un sistema de archivos virtual en cada nodo. El artista monta el proyecto; el nodo lee los archivos bajo demanda; la plataforma gestiona el almacenamiento de respaldo, el versionado y la replicación entre regiones.
Nos integramos con una plataforma de streaming de archivos en la nube genérica a elección del cliente. La plataforma detecta un evento de inicio de sesión desde cada nodo usando la cuenta del cliente; el cliente de la plataforma que se ejecuta en el nodo monta el árbol del proyecto en una ruta conocida; la aplicación DCC del cliente abre los archivos desde esa ruta exactamente como lo haría en una estación de trabajo local. La plataforma en la nube no necesita saber que el nodo forma parte de un clúster de renderizado.
Lo que cambia cuando esto se conecta a un clúster de 20 nodos es el patrón de acceso. Un único artista en una única estación de trabajo extrae un archivo de proyecto a la vez, bajo demanda, mientras trabaja. Veinte nodos de renderizado que abren la misma escena a la vez para un rango de fotogramas crean una ráfaga sincronizada de lecturas en la nube para los mismos activos. Sin una caché, cada nodo extrae cada textura, cada simulación en caché, cada archivo de dependencia, en paralelo, lo que es a la vez un desperdicio de ancho de banda internacional y lento en el primer fotograma de cada rango.
Por eso existe la caché compartida. Hablaremos de ella en detalle en la sección siguiente, pero la integración con el streaming de archivos en la nube es la razón por la que debe existir. Las extracciones de activos desde la nube se concentran a través de la caja de caché una vez, y luego se distribuyen a los veinte nodos a través de la LAN. La plataforma en la nube nunca ve veinte extracciones simultáneas de la misma textura, sino una sola extracción más lecturas SMB calientes dentro de nuestra red.
El otro detalle práctico es la escritura de vuelta. Cuando un fotograma de renderizado termina, el nodo escribe la salida en la plataforma de streaming de archivos en la nube, de vuelta a través de la cuenta del cliente. El equipo del cliente en la oficina remota ve los fotogramas aparecer en el árbol del proyecto en tiempo real. No hay ningún paso de carga manual, ni transferencia mediada por el proveedor; la plataforma en la nube gestiona el ciclo completo.
Arquitectura de la caché compartida
La caché compartida es una de las dos o tres decisiones arquitectónicas que, cuando se toman mal, corroen silenciosamente el valor de un clúster. La hemos tomado mal en despliegues anteriores. El patrón que se ha mantenido a lo largo de múltiples construcciones es deliberadamente conservador.
Una sola caja de borde y caché ejecuta Ubuntu 22.04 LTS, con un único SSD SATA de 8 TB formateado como ext4 y expuesto al clúster a través de Samba SMB3. El montaje de caché aparece en cada nodo de renderizado en una ruta fija (por ejemplo, \\cache.lan\proj). Cuando un nodo abre un archivo de proyecto a través del cliente de streaming de archivos en la nube, el archivo se transmite a través de la caché local; las lecturas posteriores del mismo archivo en cualquier nodo acceden directamente al SSD a través de la LAN.
Hay tres decisiones deliberadas en ese párrafo.
En primer lugar, una sola caché, no cachés por nodo. Una versión anterior de esta arquitectura almacenaba el material de caché por nodo. Con veinte nodos 5090, eso significaba hasta 200 TB de almacenamiento redundante que gestionar y veinte estados de caché separados que depurar cuando algo divergía. La consolidación en una sola caché compartida reduce el espacio de almacenamiento en un factor de veinte y convierte el estado de la caché en un único artefacto que el equipo de operaciones puede inspeccionar.
En segundo lugar, un único SSD en ext4, no RAID 10 con LUKS sobre XFS. El plan anterior especificaba que la caché residiría en un array RAID 10 con cifrado en reposo LUKS sobre XFS. Ese plan estaba sobredimensionado para el hardware real que desplegamos: un SSD, un sistema de archivos, un montaje. Eliminamos la capa RAID, eliminamos LUKS y usamos ext4 porque la caché no es la fuente de verdad de los datos del proyecto. La nube del cliente es la fuente de verdad. Si la unidad de caché falla, la reemplazamos y recalentamos desde el origen; no necesitamos redundancia en la capa de caché porque tenemos redundancia en la capa de nube. (El cifrado en reposo estaba fuera del alcance de este acuerdo, pero está disponible como un contrato separado cuando lo requiere un cliente final.)
En tercer lugar, pre-calentar la caché antes del primer día de renderizado. Esta es la lección que aprendimos de la manera difícil. El día D, cada fallo de caché es la lectura más costosa del clúster: atraviesa el enlace internacional, extrae desde la nube del cliente y escribe en el SSD local antes de que el motor de renderizado pueda consumirlo. El pre-calentamiento, que consiste en un recorrido estructurado por el árbol de activos del proyecto el día anterior al inicio de la producción, convierte las lecturas del día D de extracciones frías en la nube en lecturas SMB calientes. Ahora planificamos una ventana de pre-calentamiento en cada contrato de clúster dedicado.
Dentro de la instalación, cada nodo monta la caché en la misma ruta fija (\\cache.lan\proj) a través de SMB3 en la LAN local. Dado que el tráfico dentro de la instalación no atraviesa el túnel WireGuard, el clamping MSS no se aplica aquí y el enlace funciona a velocidades Gigabit Ethernet de extremo a extremo. La ruta de montaje de la caché es idéntica en todos los nodos, lo que simplifica la configuración del gestor de render del cliente: la misma ruta de archivo de escena se resuelve de la misma manera en todos los miembros del grupo.
Optimización de la red entre países
La capa de transporte es donde un clúster entre países se siente fluido o se siente roto. Los comportamientos predeterminados de TCP/IP, la fragmentación IP y DNS sobre VPN son sutilmente incorrectos para túneles cifrados de larga distancia que transportan SMB y escritorio remoto. Ajustar el kernel y la configuración de red no es opcional; es la diferencia entre un clúster que funciona y uno que misteriosamente descarta paquetes grandes.
WireGuard, hub-and-spoke. Cada artista se conecta desde su estación de trabajo a través de un cliente WireGuard al hub en la instalación del clúster. Todo el tráfico entre el artista y el clúster está cifrado end-to-end. Deliberadamente usamos una sola tecnología VPN en lugar de mezclar protocolos; combinar IPSec para un rol y una VPN diferente para otro añade superficie operativa sin mejorar la seguridad.
TCP BBR. El control de congestión predeterminado de Linux (CUBIC) fue diseñado para enlaces de baja latencia con poca pérdida de paquetes. Los enlaces públicos ISP de larga distancia que transportan tráfico cifrado se ven muy diferentes: latencia moderada, fluctuación ocasional y patrones de pérdida asimétricos. BBR produce de forma consistente un mayor rendimiento utilizable en estos enlaces que CUBIC, especialmente cuando el enlace se comparte con el otro tráfico de internet del cliente. Usamos el BBR de stock del kernel (BBR v1); el BBRv3 más reciente no se desplegó en esta construcción, y la versión de stock ha sido estable para nosotros.
Clamping TCP MSS. Esta es la fuente más común de quejas del tipo "el clúster funciona en su mayor parte, excepto con archivos grandes." Cuando el tráfico atraviesa un túnel que reduce el MTU efectivo, los paquetes grandes se fragmentan (lento) o se descartan silenciosamente (peor). Los paquetes pequeños y el ping funcionan bien, lo que hace que el problema sea difícil de diagnosticar. La solución es fijar el MSS TCP en el router WireGuard para que TCP negocie un tamaño de paquete que quepa dentro del túnel. Después de aplicar esto, los handshakes TLS, las sesiones RDP y las lecturas de archivos grandes por SMB dejan de bloquearse.
dnsmasq con la interfaz VPN listada. Un detalle sutil: dnsmasq debe listar explícitamente la interfaz WireGuard (por ejemplo, wg0) en su configuración, aunque el cliente esté consultando una dirección .lan privada. Sin ello, las búsquedas DNS a través del túnel se agotan, pero el ping sigue funcionando porque el ping no pasa por DNS. Esto produce algunas de las sesiones de diagnóstico más confusas que hemos llevado a cabo, porque todas las demás pruebas parecen correctas.
chrony para NTP. La sincronización de tiempo parece trivial, pero importa para los gestores de render (Deadline registra la hora de los trabajos), para la correlación de registros en el clúster y para cualquier token de autenticación con un componente temporal. chrony gestiona la deriva del reloj a través de un enlace de alta latencia mejor que el antiguo ntpd; lo ejecutamos en la caja de borde y hacemos que cada nodo se sincronice con él.
El efecto combinado de estas opciones es un túnel que se siente como una LAN para la mayoría de las cargas de trabajo y se degrada de forma elegante cuando la ruta pública está inusualmente congestionada. La siguiente sección trata sobre cómo funciona en la práctica ejecutar trabajo 3D a través de ese túnel.
Moonlight y Sunshine para escritorio remoto
El escritorio remoto es la capa que los artistas experimentan de forma más directa. Si la capa de escritorio remoto se siente lenta o con tartamudeo, no importa qué tan rápido sea el motor de renderizado: las manos del artista son lentas y el contrato se degrada.
Usamos Moonlight (cliente) y Sunshine (host en cada nodo) para el escritorio remoto. La combinación utiliza el codificador de hardware NVENC de NVIDIA en la RTX 5090 para codificar el búfer de fotogramas en tiempo real, y luego lo transmite a la estación de trabajo del artista. Dado que la codificación ocurre en la GPU que ya está en el nodo, no hay contención con el motor de renderizado, y la latencia añadida por el escritorio remoto está dominada por el tiempo de ida y vuelta de la red, no por la etapa de codificación.
Para el trabajo en viewport 3D, esto importa de una manera que no ocurre con el escritorio remoto tradicional. Los protocolos más antiguos —RDP, VNC, el escritorio remoto estándar de Microsoft— fueron diseñados para cargas de trabajo de oficina. Gestionan bien el texto, los diálogos y las ventanas que cambian lentamente, pero colapsan en un viewport 3D a pantalla completa durante una vista previa de turntable. Moonlight y Sunshine tratan el búfer de fotogramas como video, que es exactamente el modelo correcto para el trabajo 3D.
Tenemos una prueba de control de calidad que ejecutamos antes de entregar un nodo a un artista, informalmente denominada "Test 8", que ejercita una secuencia definida de operaciones de viewport bajo carga y confirma que la experiencia de escritorio remoto cumple una línea de base. Si un nodo no pasa la prueba, depuramos la canalización de codificación o retiramos el nodo de la rotación hasta resolver el problema. Ejecutamos esta prueba al inicio de cada contrato y después de cualquier reimagen del nodo.
Parsec es una alternativa viable cuando Sunshine tiene un problema específico del host. Hemos desplegado un pequeño número de nodos con Parsec cuando Sunshine no pudo configurarse de forma fiable; la experiencia del artista es similar. No lo estandarizamos porque el modelo basado en cuenta y coordinado en la nube no se adapta tan limpiamente al manejo de credenciales del Modelo B como Sunshine auto-hospedado.
Consideramos otras opciones de escritorio remoto en la planificación inicial y las descartamos: herramientas de escritorio remoto genéricas sin codificación GPU y una alternativa de código abierto que no superó nuestro control de calidad en un viewport 3D a pantalla completa. El principio que importa: para los nodos de clústeres GPU, el streaming con codificación de hardware es el único modelo que se mantiene a escala.
Planificación de capacidad y reserva
La configuración de 20 nodos de esta guía es una reserva dedicada de la flota más amplia de Super Renders Farm, asignada exclusivamente durante la duración del contrato. Reservada significa que los nodos no se comparten con el grupo del servicio gestionado, no se co-programan con otros inquilinos y no están sujetos a facturación por fotograma: el cliente paga por la reserva como un gasto operativo fijo y tiene control exclusivo de esos nodos desde el inicio hasta el cierre.
Dimensionar la reserva en veinte nodos es una elección deliberada. Por debajo de diez nodos, un clúster no justifica la superficie arquitectónica frente a una render farm gestionada: la ruta SaaS es más sencilla y más económica. Por encima de treinta, la capa de caché necesita re-arquitecturarse (múltiples cajas de caché, cachés regionales) y el modelo operativo cambia de forma. Veinte es la banda donde una sola caja de borde y caché, un único hub WireGuard y una imagen Windows uniforme se mantienen correctamente, y donde un equipo creativo de diez a veinte artistas tiene suficientes nodos para mantener el flujo de fotogramas durante los picos sin tiempo de inactividad en el estado estacionario.
Dado que Super Renders Farm opera una flota sustancial más allá de esta reserva dedicada, existe capacidad adicional para escalar cuando el contrato lo requiera. Añadir nodos reservados adicionales dentro de la misma instalación es un cambio de configuración, no un ciclo de aprovisionamiento. Los clientes que ejecutan contratos de varios meses típicamente fijan el tamaño de la reserva al inicio y redefinen el alcance en los límites de trimestre en función de la demanda real frente al plan original.
Segmentación de red
La segmentación de red en un clúster como este no es opcional. El cliente opera en la infraestructura del proveedor, pero el cliente nunca debe poder ver la red más amplia del proveedor: ni el NAS del proveedor, ni las interfaces de administración del router del proveedor, ni ningún otro inquilino. De igual manera, los sistemas internos del proveedor nunca deben estar expuestos a las cargas de trabajo del cliente.
Implementamos la segmentación en dos niveles.
Nivel 1 — firewall de borde. La caja de borde y caché ejecuta ufw (uncomplicated firewall) en una postura de denegación de entrada por defecto. Solo el puerto UDP de WireGuard (51820) está expuesto a internet público. SSH, SMB, DNS, NTP y cualquier otro servicio que se ejecute en el borde están vinculados a interfaces internas e inaccesibles desde fuera del clúster. Las reglas de reenvío permiten paquetes entre la interfaz WireGuard y la LAN del clúster, pero no entre ninguna de ellas y las otras redes internas del proveedor. La postura de reenvío por defecto es descartar, a menos que se permita explícitamente.
Nivel 2 — firewall de host en cada nodo. Cada nodo de renderizado tiene su propia configuración de firewall de Windows que refleja la postura del borde: aceptar tráfico entrante desde las IP del clúster para los servicios que el clúster necesita (SMB, escritorio remoto, gestor de render) y descartar todo lo demás. Esto no es redundante; es defensa en profundidad. Si un nodo está mal configurado o comprometido, el firewall del host sigue siendo una barrera.
El principio detrás de ambos niveles es el de mínimo privilegio: el cliente y los nodos deben ver el grupo de nodos y nada más. No damos al cliente rutas generales hacia la red interna del proveedor. El túnel del cliente termina en la caja de borde; la caja de borde enruta solo hacia la LAN del clúster; la LAN del clúster enruta solo entre los miembros del clúster.
En la práctica, el cliente no puede hacer ping ni escanear los otros sistemas del proveedor aunque lo quisiera. No hay plano de gestión compartido, ni ruta de monitoreo compartida que exponga a otros inquilinos.
Lecciones aprendidas
Estas son cinco lecciones operativas que, en cada clúster dedicado que hemos puesto en marcha, nos han ahorrado horas de depuración o —cuando olvidamos aplicarlas— nos han costado horas de depuración.
1. Trampa de enrutamiento con puerta de enlace con doble interfaz. Cuando la caja de borde tiene dos interfaces de red (una pública, una LAN), el orden de las operaciones importa. La ruta LAN debe configurarse antes de cambiar la ruta por defecto. Si cambia primero la ruta por defecto y luego intenta añadir la ruta LAN, la sesión SSH que usó para iniciar sesión puede caer en el momento en que cambia la ruta por defecto, bloqueando el acceso a la caja. La solución es procedimental, no técnica: siempre configure primero las rutas internas, valídelas y solo entonces modifique la ruta por defecto.
2. WireGuard y DNS. dnsmasq debe listar explícitamente cada interfaz en la que debe escuchar, incluyendo la interfaz WireGuard. Si solo lista la interfaz LAN, las búsquedas DNS de los clientes VPN se agotan, pero las respuestas de ping siguen funcionando porque el ping no pasa por DNS. Este es uno de los modos de fallo más engañosos desde el punto de vista del diagnóstico que hemos encontrado. La solución es una línea en la configuración de dnsmasq, pero hay que saber dónde buscarla.
3. El clamping TCP MSS no es opcional a través de un túnel. Los handshakes TLS, las sesiones RDP, las lecturas de archivos grandes por SMB: cualquier cosa que quiera enviar paquetes grandes se descartará silenciosamente si el MSS no está fijado. El primer síntoma suele ser "Moonlight funciona durante diez segundos y luego se congela" o "SMB lista directorios pero no puede leer archivos de más de 1 MB." La solución es una regla iptables en el host WireGuard. Aplíquela antes de entregar el clúster.
4. Dimensione correctamente el almacenamiento, no lo sobrediseñe. La versión anterior de esta arquitectura especificaba RAID 10 con cifrado LUKS sobre XFS. El hardware de caché que desplegamos era un único SSD. Eliminamos la capa RAID, eliminamos la capa LUKS y usamos ext4, porque la caché no es la fuente de verdad; la plataforma en la nube sí lo es. Intercambiar la redundancia teórica en la capa de caché por redundancia real en la capa de nube fue la decisión correcta. La lección es diseñar el almacenamiento en función de lo que los datos realmente requieren, no de lo que parece seguro en un documento de planificación.
5. Pre-caliente la caché. El día D, cada fallo de caché tiene un coste en el enlace internacional y en un viaje de ida y vuelta a la plataforma en la nube. La primera hora de producción con una caché fría se siente lenta aunque todo lo demás esté correctamente configurado. Ahora planificamos una ventana de pre-calentamiento en cada contrato, generalmente uno o dos días antes del inicio de la producción. El artista no ve el pre-calentamiento; ve un clúster que ya se siente rápido en el primer fotograma.
Estas son lecciones operativas, no arquitectónicas. Viven en la lista de verificación de despliegue, no en el documento de arquitectura. Pero distinguen un clúster que funciona en teoría de uno que aguanta bajo carga de producción real. Los patrones menores se aplican caso a caso; los cinco anteriores son los que han aparecido en cada despliegue.
Conclusión
Una render farm GPU dedicada entre países de 20 nodos es la arquitectura correcta cuando el control de la propiedad intelectual es contractual, el contrato dura varios meses, el flujo de trabajo necesita configuración personalizada y la autenticación con nube propia es innegociable. Fuera de esas condiciones, una render farm gestionada es casi siempre la mejor respuesta: la complejidad arquitectónica aquí no se justifica para trabajo por proyecto o para equipos sin una función de operaciones dedicada.
Cuando las condiciones sí se aplican, los patrones cubiertos aquí —credenciales Modelo B, caché compartida en ext4, transporte WireGuard hub-and-spoke, BBR con clamping MSS, Moonlight y Sunshine para escritorio remoto, segmentación en dos niveles— son los que desplegamos por defecto. No son los únicos patrones válidos, pero son los que se han mantenido a lo largo de los despliegues.
El equipo detrás de Super Renders Farm opera tanto alquiler de render farm gestionada como despliegues de clústeres dedicados, incluidas las configuraciones de clústeres GPU dedicados y las topologías entre países descritas a lo largo de esta guía.
FAQ
Q: ¿Cuánto tiempo dura un despliegue típico de un clúster dedicado de 20 nodos? A: Dependiendo del alcance, la disponibilidad del hardware en la instalación y la configuración de streaming de archivos en la nube del cliente, un contrato típico requiere desde varias semanas de tiempo de espera para el aprovisionamiento de hardware y red, hasta una ventana de pre-calentamiento de uno a dos días antes del inicio de la producción. Dimensionamos el cronograma según el calendario de producción del cliente, no según una plantilla fija.
Q: ¿Qué ocurre si mi equipo está distribuido en tres continentes? A: La topología WireGuard hub-and-spoke escala a ubicaciones adicionales de clientes sin cambiar la arquitectura del clúster. Cada artista remoto ejecuta un cliente WireGuard y se conecta al mismo hub en la instalación del clúster. La latencia de cada región está determinada por la ruta de internet pública entre esa región y el hub; en nuestra experiencia, BBR y el clamping MSS marcan la diferencia entre un enlace utilizable y uno inutilizable en esas rutas.
Q: ¿Puedo ver el clúster antes de comprometerme con un contrato de varios meses? A: Normalmente organizamos una ventana de prueba de concepto durante la conversación de alcance. La forma exacta depende del proyecto del cliente: a veces es una sesión de escritorio remoto en un solo nodo para probar la experiencia del artista, otras veces es una prueba de renderizado a pequeña escala para validar la caché y la integración del streaming de archivos en la nube. Los términos específicos son una discusión comercial; póngase en contacto con nuestro equipo de ventas para hablar sobre lo que funcionaría para su cronograma.
Q: ¿Cómo se gestiona la seguridad de los datos al final del contrato? A: Dado que el Modelo B mantiene las credenciales del cliente fuera de nuestras manos, el cierre al final del contrato se centra en la limpieza del hardware y la caché. Borramos la caché SMB, reimaginamos cada nodo desde la base limpia y proporcionamos una certificación escrita de que la caché y las imágenes de los nodos han sido destruidas. El cliente revoca sus propias sesiones de streaming de archivos en la nube, lo cual está fuera de nuestro sistema. El lenguaje contractual específico (NDA, SLA, redacción de la carta de certificación) es gestionado por nuestro equipo de ventas.
Q: ¿Qué pasa si necesito más de 20 nodos? A: La configuración de 20 nodos es la forma más común que desplegamos, pero la arquitectura escala más allá de eso. Las flotas más grandes se añaden dentro de la misma instalación: nodos reservados adicionales se integran al mismo hub WireGuard, la misma caché SMB3 y la misma imagen Windows uniforme. El límite práctico suele ser el ancho de banda de la caché: una sola caja de borde y caché tiene un techo de lectura SMB finito, y en flotas muy grandes la arquitectura de la caché en sí misma necesita replantearse (múltiples cajas de caché, cachés regionales). Analizamos estas opciones de diseño caso a caso.
Q: ¿Puedo traer mi propia licencia de Cinema 4D, Redshift u otras herramientas DCC? A: El modelo de licencia —traer la propia licencia frente a la proporcionada por el proveedor— es una decisión comercial que depende de la herramienta DCC específica y del inventario de licencias existente del cliente. Algunas configuraciones funcionan limpiamente con licencias del cliente; otras son más sencillas con las proporcionadas por el proveedor. Lo resolvemos durante la conversación de alcance. Póngase en contacto con nuestro equipo de ventas para obtener más información.
Q: ¿Cómo gestiona el almacenamiento en la nube de proveedores de la UE frente a los de EE. UU.? A: La plataforma de streaming de archivos en la nube es elección del cliente. Nuestro clúster se integra con cualquier plataforma que pueda ejecutar un cliente de inicio de sesión en Windows y exponer el árbol del proyecto del cliente como un sistema de archivos montado. La ubicación geográfica de la nube de origen afecta a la latencia internacional de la ruta cliente-clúster, razón por la cual recomendamos el transporte WireGuard hub-and-spoke y la configuración ajustada con BBR para configuraciones entre países. No alojamos la plataforma en la nube nosotros mismos; permanece bajo la cuenta del cliente.
Q: ¿Qué ocurre si el túnel WireGuard cae? A: WireGuard restablece automáticamente la sesión cuando la red subyacente se recupera; la sesión de escritorio remoto del cliente puede pausarse brevemente durante el rehandshake. Si el túnel cae mientras un renderizado está en curso, el renderizado en sí continúa ejecutándose en el nodo (no depende del túnel para el trabajo en curso), pero la escritura de vuelta a la nube se pondrá en cola hasta que se restaure el túnel. Monitorizamos el estado del túnel desde la caja de borde y alertamos sobre tiempos de inactividad prolongados.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



