
Render Farm Upload-Automatisierung mit Python: Ein Leitfaden für paramiko und rsync
Überblick
Der langsamste Teil eines Cloud-Renders ist oft nicht das Rendern selbst. Für ein Studio, das einen Multi-Kamera-VFX-Shot oder einen 400-GB-Houdini-Cache jede Nacht zu einer render farm hochlädt, liegt der Flaschenhals im Bewegen der Bytes — das Projekt zuverlässig hochzuladen und die fertigen Frames wieder herunterzuladen, bevor morgens jemand ins Büro kommt. Das von Hand zu erledigen und dabei um Mitternacht auf einen Fortschrittsbalken zu starren, ist nicht skalierbar. Es per Skript zu automatisieren schon.
Dieser Leitfaden behandelt die Automatisierung dieser Transferschicht in Python. Wir betreiben Super Renders Farm, eine vollständig verwaltete render farm, und „vollständig verwaltet" hat für die Automatisierung eine präzise Bedeutung: Sie greifen nicht per Remote-Zugriff auf Maschinen zu, installieren keine Software und verwalten keine Lizenzen. Daher konzentriert sich der Teil der Pipeline, den Sie per Skript steuern, auf das, was Ihnen gehört — die Dateien, die hochgehen, und die Renders, die wieder herunterkommen. Die Transferebene ist über SFTP tatsächlich skriptierbar, und Python ist ein erstklassiges Werkzeug dafür. Unsere eigene Transferdokumentation nennt Pythons paramiko-Bibliothek direkt als unterstützten Client, neben rsync über SSH und der Standard-sftp-Befehlszeile.
Wir werden ebenso präzise sein, was Sie von Python aus heute nicht automatisieren können, denn eine Pipeline, die auf einem nicht existierenden Feature aufbaut, schlägt beim ersten unbeaufsichtigten Lauf fehl. Wenn Sie die übergeordnete konzeptionelle Übersicht wünschen — was „headless" im Vergleich zu „unbeaufsichtigt" bedeutet, wie man Szenen für das Rendering über die Befehlszeile vorbereitet — ist das ein separater Begleitleitfaden. Dieser bleibt auf Code-Ebene und konzentriert sich auf die Transferschicht: paramiko, rsync, SSH-Keys, Wiederholungsversuche und ein nächtliches Sync-Muster, das Sie direkt in die Automatisierung eines Studios integrieren können.
Was Sie in Python heute automatisieren können
Es hilft, die Grenze zu ziehen, bevor man überhaupt Code schreibt. Bei einer verwalteten render farm ist ein Teil der Pipeline vollständig skriptierbar, ein anderer Teil ist bewusst auf die GUI ausgelegt, und ein Teil liegt dazwischen. Ehrlichkeit darüber, was was ist, bewahrt Ihre Automatisierung davor, still und leise zu versagen.
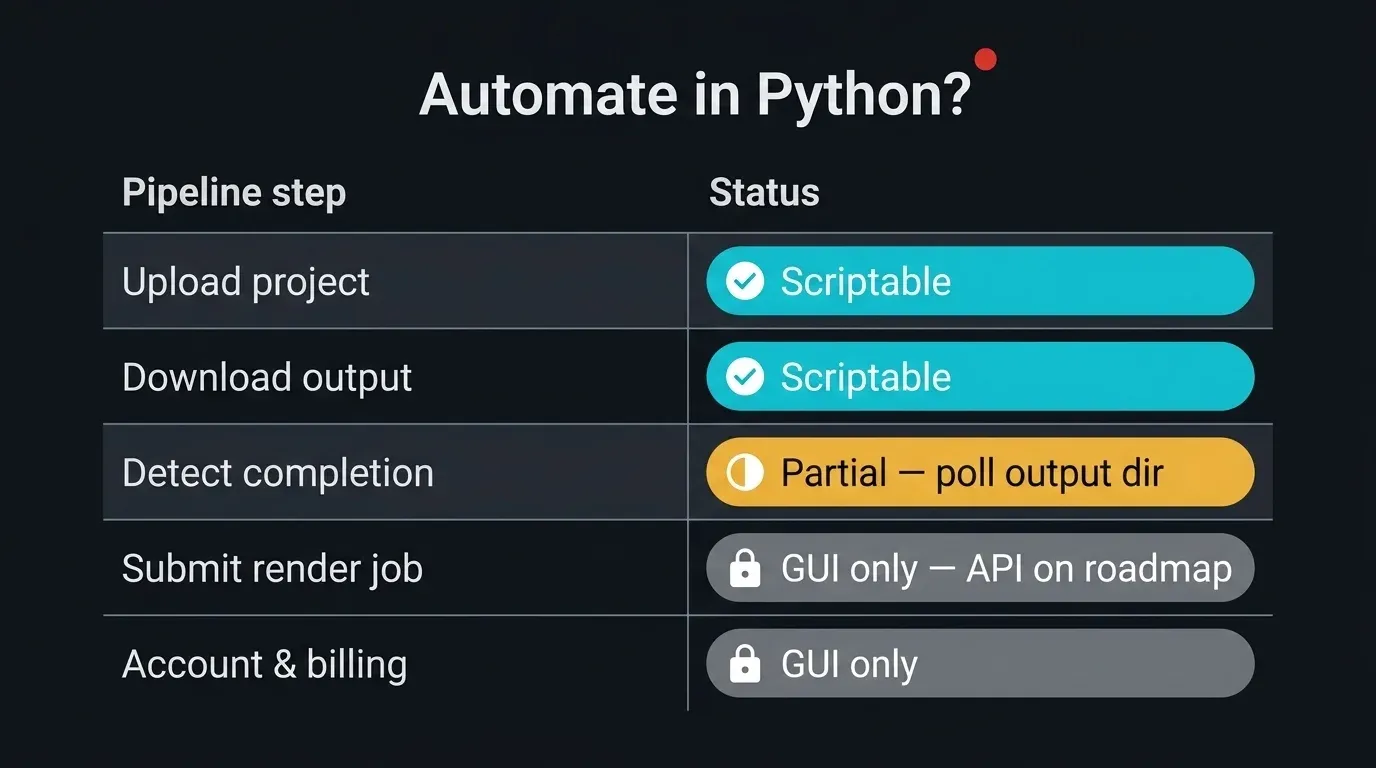
Matrixdiagramm, das zeigt, welche Schritte der render-farm-Pipeline in Python auf einer verwalteten Cloud-render-farm automatisiert werden können: Projekt hochladen (vollständig skriptierbar über paramiko, rsync, sftp), Ausgabe herunterladen (vollständig skriptierbar), Jobabschluss erkennen (partiell — SFTP-Ausgabeverzeichnis abfragen, keine Status-API), Render-Job einreichen (nur GUI — Webformular, Client-App oder DCC-Plugin), Konto und Abrechnung verwalten (nur GUI), mit grünen, gelben und grauen Statusspalten
- Ein Projekt hochladen — vollständig skriptierbar. SFTP über
paramiko,rsyncoder skriptiertesftp-Befehle funktionieren alle gegen unseren SFTP-Server. Das ist der Kern des Folgenden. - Fertige Frames herunterladen — vollständig skriptierbar. Die Ausgabe landet in einem Job-spezifischen Verzeichnis, das Sie mit denselben Werkzeugen abrufen können.
- Erkennen, dass ein Job abgeschlossen ist — partiell. Es gibt keine öffentliche Status-API zum Abfragen. Was Sie können, ist das SFTP-Ausgabeverzeichnis abzufragen und zu beobachten, wie die Frames erscheinen und sich stabilisieren. Das ist eine Heuristik, kein offizielles Signal, und wir behandeln es auch so.
- Einen Render-Job einreichen — heute nur über die GUI. Das Einreichen läuft über das Webformular, die SuperRenders Client-App oder ein DCC-spezifisches Einreich-Plugin. Eine öffentliche REST-API für das Einreichen von Jobs, das Abfragen des Status und das Abrufen der Ausgabe steht auf unserer Roadmap, aber zum jetzigen Zeitpunkt sind keine öffentlichen API-Endpunkte für die direkte Integration verfügbar. Wenn Ihre Pipeline speziell durch eine Einreich-API blockiert ist, wenden Sie sich an den Support und schildern Sie den Anwendungsfall — die Roadmap wird durch echte Pipeline-Anforderungen geprägt.
- Konto, Credits oder Abrechnung verwalten — über die GUI. Das liegt außerhalb des Rahmens der Transferautomatisierung.
Die automatisierbare Oberfläche ist also der Transfer: das Projekt hochladen, die Renders herunterladen und die Lücke dazwischen überbrücken, indem man das Ausgabeverzeichnis beobachtet. Der Einreichungsschritt bleibt eine bewusste Übergabe, und wir kennzeichnen ihn in der finalen Pipeline klar, anstatt so zu tun, als wäre er nicht vorhanden. Eine umfassendere Behandlung dessen, was verwaltetes Rendering freigibt und was nicht, bietet unser Leitfaden dazu, was eine vollständig verwaltete render farm ist. Neue Konten können mit der Erste-Schritte-Anleitung beginnen.
Voraussetzungen: SFTP-Zugang, SSH-Keys und eine Python-Umgebung
Drei Dinge müssen vorhanden sein, bevor der erste skriptierte Upload startet.
SFTP-Zugang, kontospezifisch aktiviert. SFTP wird auf Anfrage pro Konto aktiviert. Melden Sie sich an, suchen Sie in Ihren Kontoeinstellungen nach „SFTP-Zugang" und generieren Sie dort Zugangsdaten. Falls die Option nicht sichtbar ist, bitten Sie den Support, sie zu aktivieren. Zu den Zugangsdaten gehören ein Server-Hostname (er variiert je nach Region und Speicherzuweisung, also behandeln Sie ihn als Wert, den Sie aus der Konfiguration lesen — niemals fest im Code hinterlegen), ein mit Ihrem Konto verknüpfter Benutzername, ein Passwort oder SSH-Key und der Standard-SFTP-Port 22. Zwei Pfade sind relevant: /uploads/<Ihr-Projektordner>/ ist Ihr Schreibbereich, und /output/<job-id>/ ist der Ort, an dem fertige Renders erscheinen.
Ein SSH-Key, kein Passwort. Für alles Automatisierte ist die SSH-Key-Authentifizierung die richtige Wahl — sie hält Geheimnisse aus Ihren Skripten heraus und übersteht unbeaufsichtigte Ausführungen ohne interaktive Eingabeaufforderung. Generieren Sie ein modernes Schlüsselpaar und registrieren Sie die öffentliche Hälfte in Ihrem Konto:
ssh-keygen -t ed25519 -C "pipeline@yourstudio.example"
# Fügen Sie den Inhalt von ~/.ssh/id_ed25519.pub unter
# superrendersfarm.com -> Settings -> SFTP -> SSH Keys
Ein Hinweis zur Kontosicherheit: Zwei-Faktor-Authentifizierung wird auf Konten derzeit nicht unterstützt. Die stärkste Absicherung für SFTP ist daher eine Passphrase auf der Schlüsseldatei plus ein SSH-Agent, der den freigeschalteten Key für die Sitzung hält. Der Key plus die Kenntnis seiner Passphrase spielt eine ähnliche Rolle wie ein zweiter Faktor — Besitz plus Geheimnis.
Eine Python-Umgebung mit paramiko. Alles Folgende verwendet paramiko, die Standard-Pure-Python-SSH/SFTP-Implementierung, und ruft rsync für große inkrementelle Transfers auf.
python3 -m venv .venv && source .venv/bin/activate
pip install paramiko
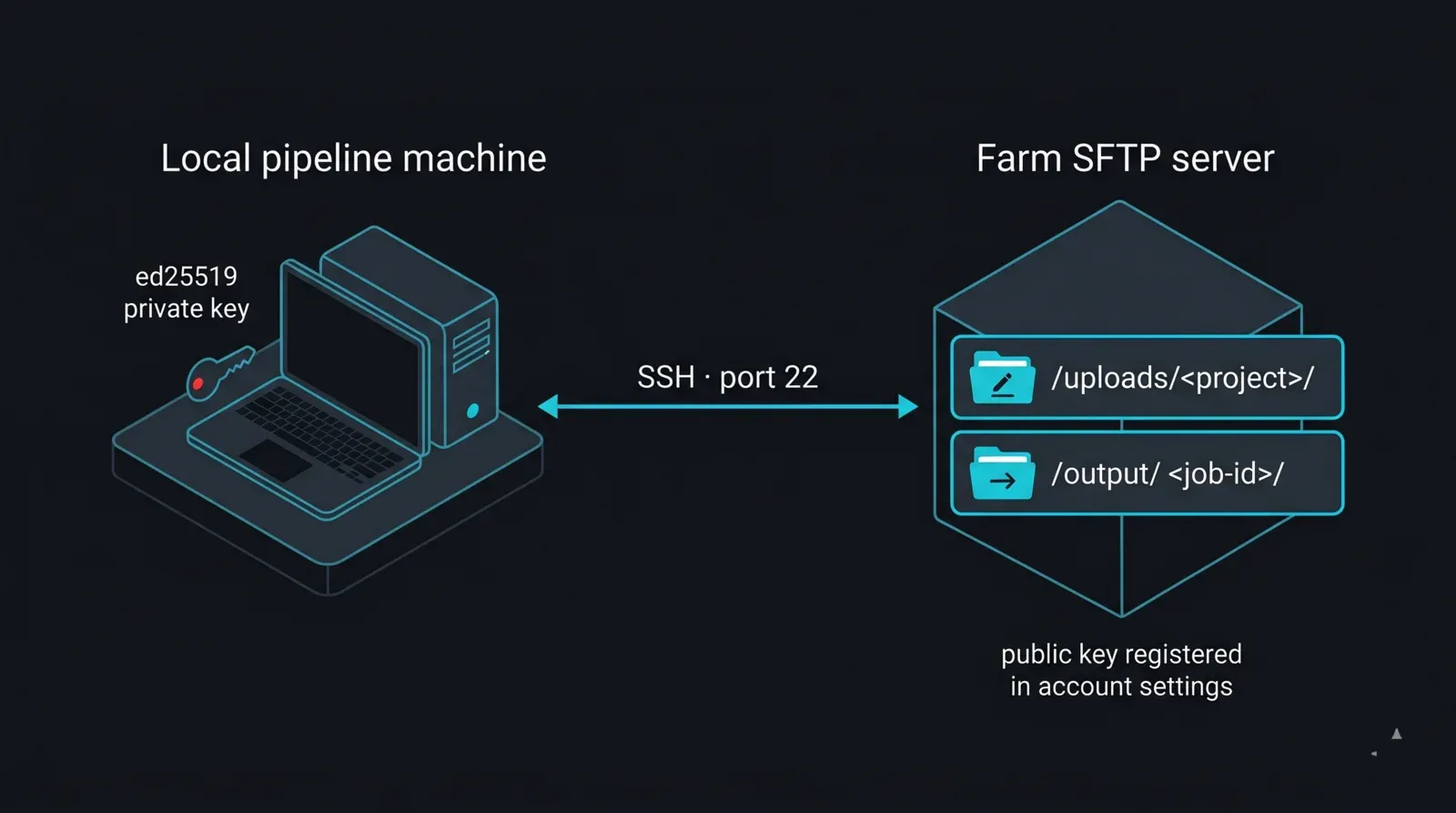
Diagramm des SFTP-Konto-Layouts und der schlüsselbasierten Authentifizierung für eine verwaltete render farm: Eine lokale Pipeline-Maschine mit einem privaten ed25519-Key verbindet sich über SSH-Port 22 mit dem SFTP-Server der render farm, der zwei Verzeichnisse bereitstellt — /uploads/<Projekt>/ als Schreibbereich für eingehende Projekte und /output/<job-id>/ als Lesebereich für fertige Frames; der passende öffentliche Key ist in den Kontoeinstellungen registriert
Ein Projekt so verpacken, dass es einen unbeaufsichtigten Upload übersteht
Die meisten fehlgeschlagenen Render-Jobs sind keine Engine-Fehler — sie sind Verpackungsprobleme. Eine Szene, die auf der Workstation eines Artists problemlos rendert, schlägt auf einem frischen Worker-Node fehl, weil ein Texturpfad auf ein lokales Laufwerk zeigt oder eine referenzierte Unterszene nie gebündelt wurde. Automatisierung verstärkt dieses Problem: Ein unbeaufsichtigter Upload eines fehlerhaften Pakets erzeugt einen unbeaufsichtigten Fehler. Zwei Regeln halten Pakete sauber.
Erstens: Machen Sie das Projekt durch relative Pfade eigenständig. Führen Sie den Sammel-und-Paketier-Befehl Ihres DCCs aus (Archive, Collect Files, Save Project with Assets), damit jede Textur, jeder Proxy und jeder Cache relativ zum Projektstamm aufgelöst wird. Zweitens: Achten Sie auf das Archivformat, wenn Sie vor dem Upload komprimieren: Wir unterstützen tar, tar.gz und 7z, aber kein .zip — packen Sie es als .tar.gz um, oder lassen Sie das Archivieren ganz weg und lassen Sie rsync den Ordnerbaum übertragen, was für laufende Projekte ohnehin die bessere Wahl ist. Als praktische Obergrenze sollte ein einzelner Upload unter ca. 300 GB bleiben; darüber hinaus setzen Sie besser auf rsync mit Fortsetzen statt auf einen monolithischen Transfer.
Ein Projekt mit paramiko hochladen
Der erste Baustein ist ein rekursiver Uploader. Er verbindet sich mit einem Key, durchläuft den lokalen Projektbaum, erstellt die Verzeichnisstruktur unter /uploads/ neu und überträgt jede Datei. Wir fixieren Host-Keys mit RejectPolicy und lesen Verbindungsdetails aus der Umgebung, damit nichts Sensibles im Skript steht.
import os
import paramiko
def connect():
host = os.environ["SRF_SFTP_HOST"]
user = os.environ["SRF_SFTP_USER"]
key_path = os.environ["SRF_SFTP_KEY"] # Pfad zum privaten Key
client = paramiko.SSHClient()
client.load_system_host_keys() # nur ~/.ssh/known_hosts vertrauen
client.set_missing_host_key_policy(paramiko.RejectPolicy())
client.connect(hostname=host, port=22, username=user, key_filename=key_path)
return client, client.open_sftp()
def _ensure_remote_dir(sftp, remote_dir):
# mkdir -p über SFTP: Pfad Segment für Segment aufbauen
path = ""
for segment in remote_dir.strip("/").split("/"):
path += "/" + segment
try:
sftp.stat(path)
except IOError:
sftp.mkdir(path)
def upload_dir(sftp, local_dir, remote_dir):
for root, _dirs, files in os.walk(local_dir):
rel = os.path.relpath(root, local_dir)
remote_root = remote_dir if rel == "." else f"{remote_dir}/{rel.replace(os.sep, '/')}"
_ensure_remote_dir(sftp, remote_root)
for name in files:
local_path = os.path.join(root, name)
remote_path = f"{remote_root}/{name}"
sftp.put(local_path, remote_path)
print(f"uploaded {remote_path}")
Aufruf für ein einzelnes Projekt:
client, sftp = connect()
try:
upload_dir(sftp, "/local/projects/archviz-tower", "/uploads/archviz-tower-2026-06")
finally:
sftp.close()
client.close()
Das reicht für kleine und mittelgroße Projekte. sftp.put akzeptiert auch ein callback=-Argument, das übertragene Bytes und die Gesamtzahl empfängt und das Sie an eine Fortschrittsanzeige oder eine Log-Zeile pro Datei ankoppeln können. Für die großen, wiederholten Transfers, die die Arbeit in Studios prägen, ist rsync jedoch das bessere Werkzeug.
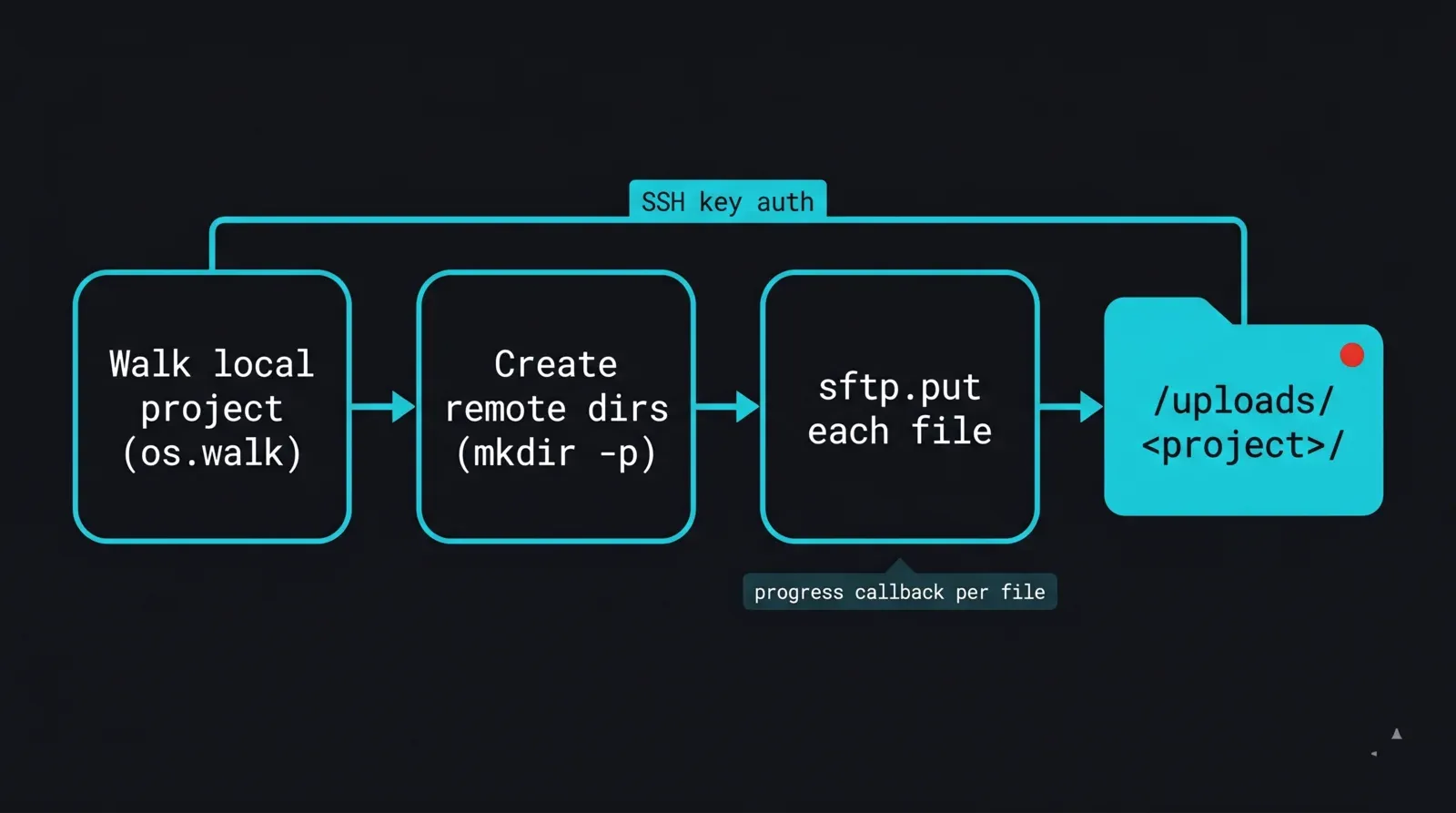
Flussdiagramm einer paramiko-Upload-Routine für eine render farm: Ein lokaler Projektordner wird Datei für Datei mit os.walk durchlaufen, der Remote-Verzeichnisbaum wird unter /uploads mit einer mkdir-p-Schleife erstellt, dann wird jede Datei per sftp.put über eine schlüsselauthentifizierte SSH-Verbindung gesendet, mit einem Fortschritts-Callback, der jede abgeschlossene Datei protokolliert
Inkrementelle Synchronisierung mit rsync über SSH
Ein Render-Projekt wird selten nur einmal hochgeladen. Sie optimieren einen Shader, rechnen eine Simulation neu, passen ein Licht an und laden erneut hoch. Jedes Mal den gesamten Ordner zu senden verschwendet Stunden; rsync sendet nur das, was sich geändert hat. Für ein Studio, das nächtlich hochlädt, ist das die einzelne größte Zeitersparnis in der Transferschicht — weil nur das Delta und nicht das gesamte Projekt übertragen wird.
Der kanonische Aufruf:
rsync -avz --partial --progress \
/local/projects/archviz-tower/ \
"$SRF_SFTP_USER@$SRF_SFTP_HOST:/uploads/archviz-tower-2026-06/"
-a bewahrt Struktur und Zeitstempel, -z komprimiert unterwegs, --partial behält teilweise übertragene Dateien, sodass eine unterbrochene Verbindung fortgesetzt statt neu gestartet wird, und --progress berichtet pro Datei. Wenn Sie denselben Befehl nach einer Änderung erneut ausführen, werden nur die geänderten Dateien übertragen. Da das Ziel die Automatisierung ist, binden Sie rsync in Python ein, damit es im selben Skript wie alles andere lebt und Sie auf seinen Exit-Code reagieren können:
import subprocess
def rsync_up(local_dir, remote_subdir):
host = os.environ["SRF_SFTP_HOST"]
user = os.environ["SRF_SFTP_USER"]
dest = f"{user}@{host}:/uploads/{remote_subdir}/"
cmd = ["rsync", "-avz", "--partial", "--progress",
f"{local_dir.rstrip('/')}/", dest]
subprocess.run(cmd, check=True) # löst CalledProcessError bei Fehler aus
Um es unbeaufsichtigt auszuführen, planen Sie es ein. Ein Studio, das ein Arbeitsverzeichnis jede Nacht um 1 Uhr zur render farm spiegelt, braucht nur eine Cron-Zeile:
0 1 * * * cd /studio/pipeline && /usr/bin/python3 nightly_sync.py >> sync.log 2>&1
Damit rsync über SSH ohne Eingabeaufforderung authentifiziert wird, verweisen Sie mit -e "ssh -i ~/.ssh/id_ed25519" auf Ihren Key oder lassen Sie einen SSH-Agent den freigeschalteten Key für die Sitzung halten.
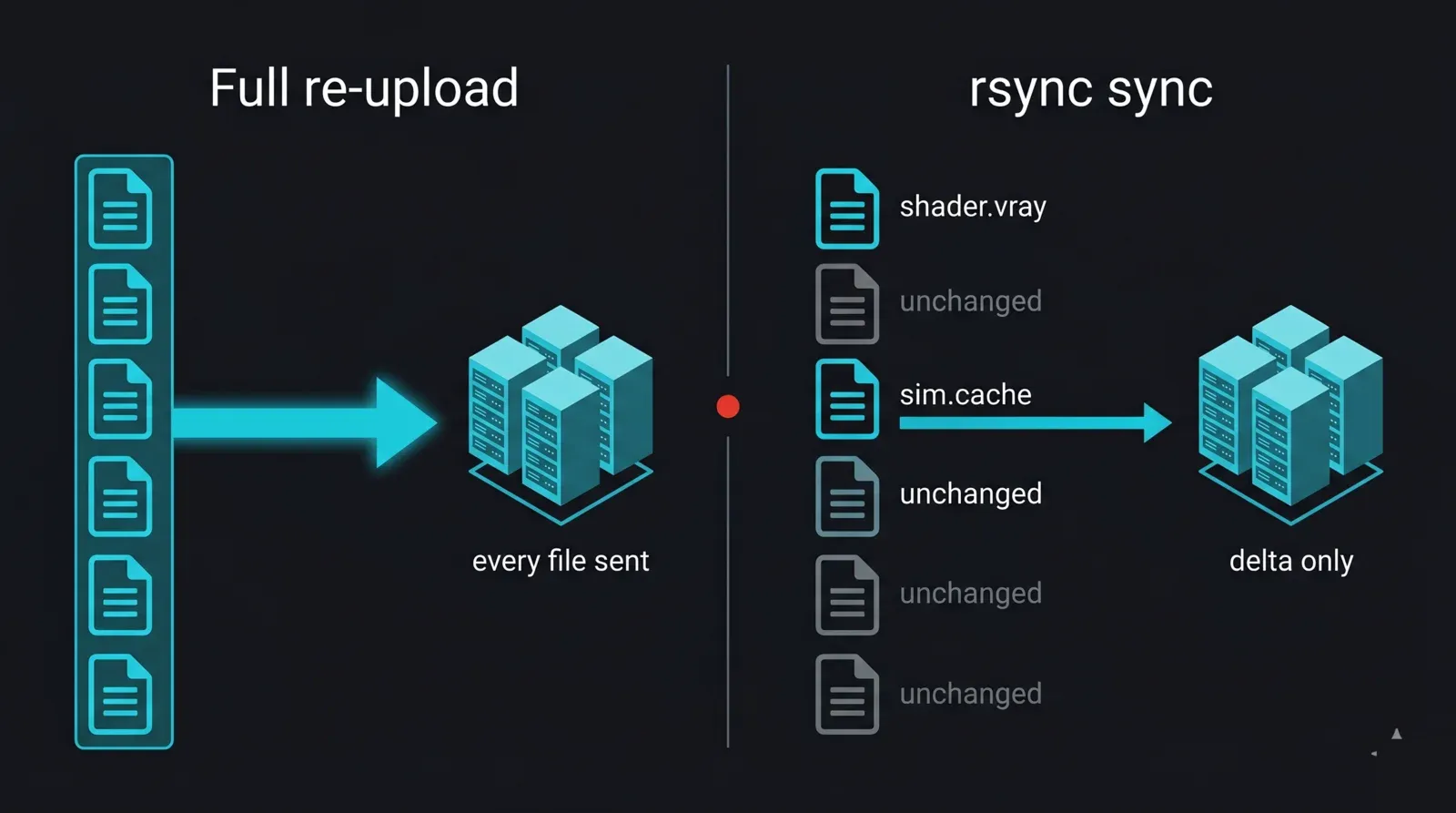
Vorher-Nachher-Diagramm, das einen vollständigen Neu-Upload mit einer inkrementellen rsync-Synchronisation zu einer render farm vergleicht: Links wird jede Datei eines Projekts jede Nacht neu gesendet; rechts vergleicht rsync lokale und Remote-Dateien und überträgt nur die geänderten Dateien (ein geänderter Shader und ein neuer Cache), während die unveränderte Masse übersprungen wird — das illustriert den Delta-Only-Transfer, der nächtliche Studio-Uploads beschleunigt
Fertige Frames automatisch herunterladen
Wenn ein Job abgeschlossen ist, werden die Ausgabe-Frames in /output/<job-id>/ auf dem SFTP-Server geschrieben. Die Download-Seite spiegelt die Upload-Seite — ein rekursives get mit paramiko oder ein rsync-Pull. Die paramiko-Version durchläuft das Remote-Verzeichnis und erstellt es lokal neu:
import stat
def download_dir(sftp, remote_dir, local_dir):
os.makedirs(local_dir, exist_ok=True)
for entry in sftp.listdir_attr(remote_dir):
remote_path = f"{remote_dir}/{entry.filename}"
local_path = os.path.join(local_dir, entry.filename)
if stat.S_ISDIR(entry.st_mode):
download_dir(sftp, remote_path, local_path)
else:
sftp.get(remote_path, local_path)
print(f"downloaded {local_path}")
Für große Ausgabe-Sets ist der rsync-Pull wieder die effizientere und fortsetzbarere Wahl:
rsync -avz --progress \
"$SRF_SFTP_USER@$SRF_SFTP_HOST:/output/<job-id>/" \
/local/downloads/<job-id>/
Ein betriebliches Detail ist für unbeaufsichtigte Pipelines wichtig: Gerenderte Ausgaben werden 45 Tage nach Jobabschluss aufbewahrt und dann automatisch gelöscht. SFTP verlängert dieses Fenster nicht. Das sichere Muster ist eine nächtliche Synchronisation, die die Ausgabe in ein lokales Archiv spiegelt, sobald sie erscheint, damit die Aufbewahrungsfrist nie der Grund ist, warum ein Frame verloren geht.
Jobabschluss ohne Status-API erkennen
Hier wird die ehrliche Grenze zu einer konkreten technischen Entscheidung. Es gibt keinen öffentlichen Endpunkt, der beantwortet, ob Job 12345 fertig ist — aber das Ausgabeverzeichnis selbst ist über SFTP beobachtbar. Das pragmatische Muster besteht darin, /output/<job-id>/ abzufragen, die Dateien zu zählen und zu warten, bis die Anzahl die erwartete Frame-Gesamtzahl erreicht und über aufeinanderfolgende Prüfungen hinweg stabil bleibt (damit Sie nicht mitten in einen Schreibvorgang hinein zu laden beginnen).
import time
def wait_for_output(sftp, output_dir, expected_frames, poll=120, stable_checks=2):
last_count, stable = -1, 0
while True:
try:
files = sftp.listdir(output_dir)
except IOError:
files = [] # Ordner noch nicht erstellt -> nicht gestartet
count = len(files)
if count >= expected_frames and count == last_count:
stable += 1
if stable >= stable_checks:
return files # Anzahl erreicht und stabil -> als fertig betrachten
else:
stable = 0
last_count = count
time.sleep(poll)
Seien Sie sich klar darüber, was das ist. Frames erscheinen inkrementell, daher reicht die bloße Anwesenheit nicht als Abschlussindikator; die Anzahl gegen die erwartete Gesamtzahl zu prüfen und zu bestätigen, dass sie zwischen Abfragen stabil ist, macht es zuverlässig genug für die Automatisierung. Es ist eine Verzeichnisheuristik, kein Vertrag. Wenn die öffentliche API erscheint, kollabiert diese gesamte Funktion zu einem Status-Aufruf — bis dahin ist das Beobachten des Ausgabeverzeichnisses der fundierte Weg, die Lücke zu überbrücken, und er hängt von nichts ab, das nicht schon existiert.
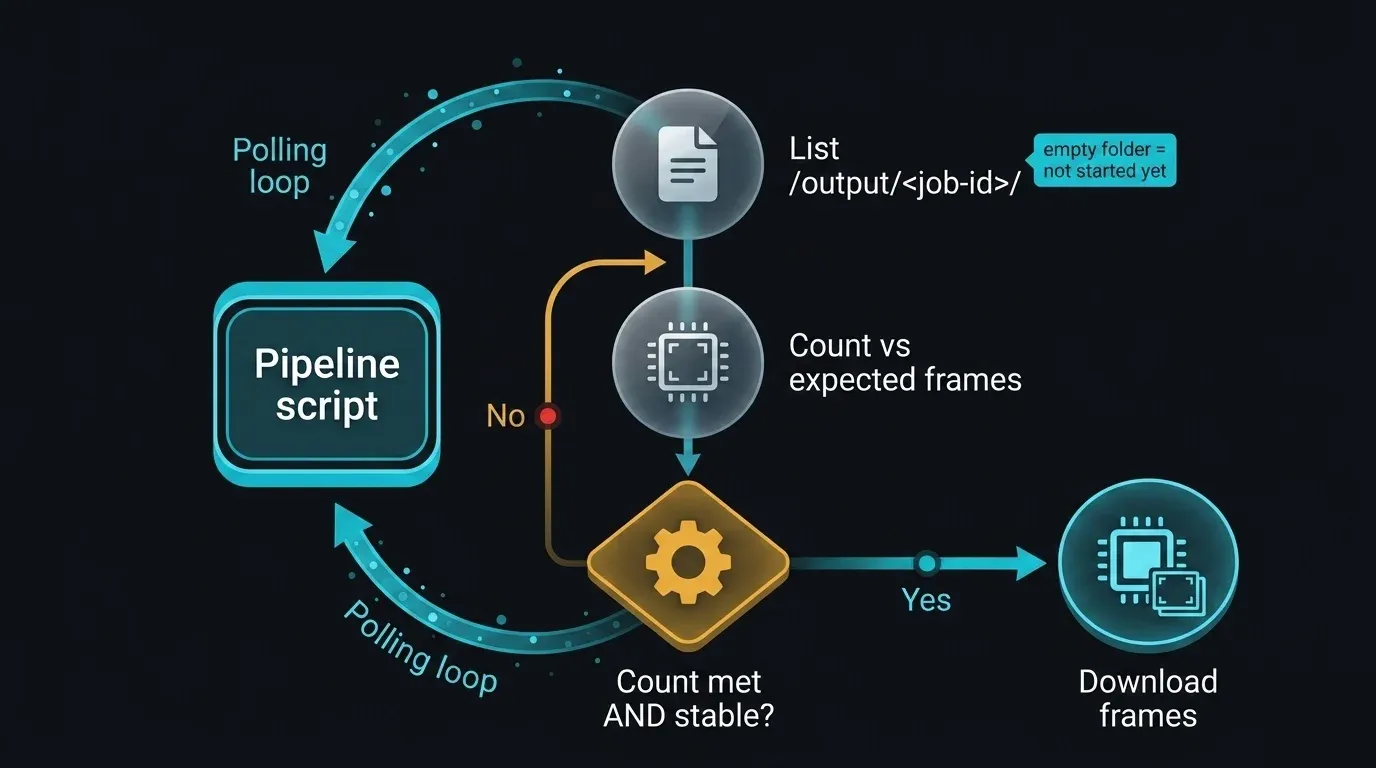
Sequenzdiagramm der Abfrage des SFTP-Ausgabeverzeichnisses zum Erkennen des Render-Abschlusses ohne Status-API: Ein Pipeline-Skript listet wiederholt /output/<job-id>/ auf, vergleicht die Frame-Anzahl mit der erwarteten Gesamtzahl, wartet bis die Anzahl sowohl das Ziel erreicht als auch über zwei aufeinanderfolgende Prüfungen stabil bleibt, und fährt dann mit dem Herunterladen fort — mit einem frühen leer-Ordner-Zustand, der als Job-nicht-gestartet gezeigt wird
Alles zusammensetzen: eine unbeaufsichtigte Transfer-Pipeline
Die Einzelteile setzen sich zu einem einzigen nächtlichen Skript zusammen. Die Struktur ist: das Projekt per Sync hochladen, an die Einreichung übergeben, warten bis die Ausgabe erscheint und sich stabilisiert, sie herunterladen, verifizieren und archivieren. Der Einreichungsschritt ist die bewusste GUI-Übergabe — bei einer verwalteten render farm reichen Sie Jobs über das Webformular, die Client-App oder ein DCC-Einreich-Plugin ein. Die DCC-spezifischen Plugins können aus der eigenen Skriptumgebung der Host-Anwendung gesteuert werden (MAXScript, Python innerhalb des DCCs), wenn die Einreichung in einem Werkzeug lebt, das Sie ohnehin skripten. Wir kennzeichnen diesen Schritt ehrlich, anstatt ihn in eine Funktion einzuwickeln, die so tut, als gäbe es eine API.
def nightly_pipeline(project_dir, remote_subdir, job_id, expected_frames):
client, sftp = connect()
try:
# with_retries() (im nächsten Abschnitt definiert) umschließt die anfälligen Netzwerkaufrufe
with_retries(lambda: rsync_up(project_dir, remote_subdir)) # 1. Delta hochladen
# 2. EINREICHEN: GUI / Client-App / DCC-Plugin -- keine öffentliche API (noch nicht)
files = wait_for_output( # 3. Ausgabeverzeichnis beobachten
sftp, f"/output/{job_id}", expected_frames)
with_retries(lambda: # 4. fertige Frames herunterladen
download_dir(sftp, f"/output/{job_id}", f"/local/downloads/{job_id}"))
print(f"job {job_id}: {len(files)} frames retrieved")
finally:
sftp.close()
client.close()
Schritte 1, 3 und 4 sind vollständig automatisiert; Schritt 2 ist die Übergabe. Wenn eine öffentliche Einreich-API verfügbar ist, werden Schritte 2 und 3 zu API-Aufrufen und die Verzeichnisabfrage entfällt. Die Architektur ändert sich nicht — nur die Einreichungs- und Status-Beine bewegen sich von GUI und Heuristik zu einem Endpunkt.
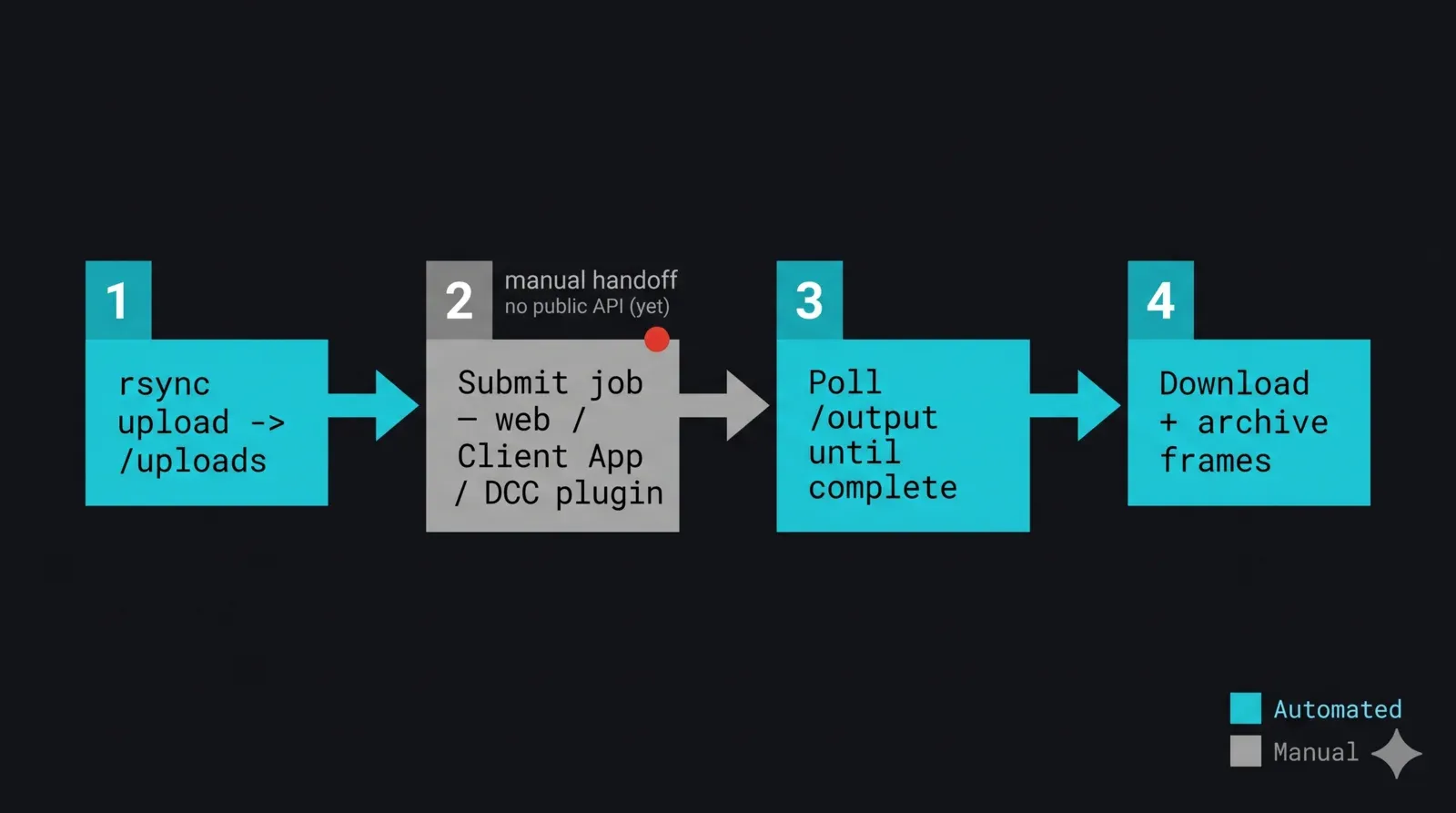
End-to-End-Flussdiagramm einer unbeaufsichtigten render-farm-Transfer-Pipeline, die aus Python gesteuert wird: Schritt 1 lädt das Projekt-Delta per rsync nach /uploads hoch, Schritt 2 ist eine klar gekennzeichnete GUI-Übergabe, bei der der Job über Webformular, Client-App oder DCC-Plugin eingereicht wird (keine öffentliche API), Schritt 3 fragt /output/<job-id> ab bis die Frames vollständig und stabil sind, Schritt 4 lädt die fertigen Frames herunter und archiviert sie lokal — automatisierte Schritte in Cyan und der manuelle Einreichungsschritt in Grau gezeigt
Fehlerbehandlung, Wiederholungsversuche und fortsetzbare Transfers
Unbeaufsichtigt bedeutet, dass niemand zusieht, wenn ein Transfer ins Stocken gerät, also muss das Skript sich selbst erholen. Drei Gewohnheiten decken die meisten Fehler ab.
Transiente Fehler mit Backoff wiederholen. Netzwerkaussetzer und kurze Verbindungsabbrüche sind bei langen Transfers normal. Umschließen Sie die anfälligen Aufrufe — wie nightly_pipeline oben —, damit ein einzelner Abbruch den Lauf nicht beendet. Fangen Sie die spezifischen transienten Fehler ab, nicht alles: paramikos SSHException, die OSError-Familie für Sockets und CalledProcessError für ein fehlgeschlagenes rsync.
def with_retries(fn, attempts=3, backoff=5):
transient = (paramiko.SSHException, OSError, subprocess.CalledProcessError)
for i in range(1, attempts + 1):
try:
return fn()
except transient: # SSH / Netzwerk / rsync-Aussetzer wiederholen
if i == attempts:
raise
time.sleep(backoff * i) # Backoff: 5 s, 10 s, 15 s
Auf Fortsetzbarkeit setzen. rsync --partial setzt unterbrochene Dateien bereits fort, und das erneute Ausführen von rsync ist idempotent — es sendet nur das Fehlende —, daher ist ein wiederholter Sync günstig, kein Neustart. Bei paramiko-Transfers erreicht ein Wiederholungsversuch plus erneutes Durchlaufen denselben Effekt, weil bereits vorhandene Dateien nahezu sofort übertragen werden.
Host-Key- und Verbindungsfehler explizit behandeln. Ein Fehler „Host Key Verification Failed" bedeutet, dass der zwischengespeicherte Key in ~/.ssh/known_hosts nicht mehr mit dem Key des Servers übereinstimmt — meistens nach einer seltenen Host-Key-Rotation. Entfernen Sie die veraltete Zeile, die der Fehler nennt, und verbinden Sie sich erneut, um den neuen Key zu akzeptieren. „Connection Refused" oder Timeout bedeutet normalerweise, dass eine Studio-Firewall ausgehendes TCP 22 blockiert — erlauben Sie es oder fragen Sie den Support nach Alternativen. Und wenn der Durchsatz deutlich unter Ihrer Verbindungsrate liegt, ist der SFTP-Overhead pro Paket bei Weitstreckenverbindungen die Ursache — lftp mit parallelen Segmenten oder mehrere gleichzeitige SFTP-Sitzungen können den größten Teil des Abstands wettmachen.
Zusammenfassung: Was automatisieren und wie
Die Transferschicht ist der Teil einer verwalteten render-farm-Pipeline, den Sie in Code besitzen, und Python deckt sie vollständig ab.
| Aufgabe | In Python automatisierbar? | Werkzeug | Hinweise |
|---|---|---|---|
| Projekt hochladen | Ja | paramiko oder rsync | rsync für große/wiederholte Transfers; --partial zum Fortsetzen |
| Inkrementeller Neu-Upload | Ja | rsync über SSH | Überträgt nur geänderte Dateien |
| Fertige Frames herunterladen | Ja | paramiko get / rsync pull | Täglich spiegeln — 45 Tage Aufbewahrung |
| Abschluss erkennen | Partiell | /output/<job-id>/ abfragen | Anzahl + Stabilitätsheuristik, keine Status-API |
| Render-Job einreichen | Nein (heute) | Web / Client-App / DCC-Plugin | Öffentliche API auf der Roadmap |
| Authentifizieren | Ja | SSH-Key (ed25519) | Key + Passphrase; keine fest hinterlegten Geheimnisse |
Automatisieren Sie den Upload, automatisieren Sie den Download, überbrücken Sie die Mitte durch Beobachten des Ausgabeverzeichnisses, und halten Sie die Einreichungsübergabe explizit. Das ergibt eine nächtliche Pipeline, die ehrlich über ihre Nahtstellen ist und gerade deswegen zuverlässig ist. Für große simulationsintensive Projekte, bei denen die Zuverlässigkeit des Transfers am meisten zählt — etwa multi-terabyte-große Houdini-Caches —, skalieren dieselben Muster direkt auf Super Renders Farm; unsere Seite zur Houdini-Cloud-render-farm behandelt diese Arbeitslast.
FAQ
Q: Welche Python-Bibliothek sollte ich für Uploads zur render farm verwenden?
A: paramiko ist die Standardwahl und wird in unserer SFTP-Dokumentation direkt als unterstützter Client genannt. Es ist reines Python, behandelt SFTP sauber und eignet sich gut für Upload- und Download-Logik. Für sehr große oder häufig wiederholte Transfers sollten Sie aus Python mit subprocess auf rsync über SSH zurückgreifen — es sendet nur geänderte Dateien und setzt unterbrochene fort, was paramiko nativ nicht tut.
Q: Gibt es eine öffentliche API, um Render-Jobs aus meiner Python-Pipeline einzureichen? A: Noch nicht. Eine öffentliche REST-API für das Einreichen, Abfragen des Status und Abrufen der Ausgabe steht auf unserer Roadmap, aber es sind heute keine öffentlichen Endpunkte verfügbar. Aktuelle programmgesteuerte Einreichungswege sind die SuperRenders Client-App und das DCC-spezifische Einreich-Plugin, das sich in die eigene Skriptumgebung der Host-Anwendung wie MAXScript oder Python innerhalb des DCCs integriert. Wenn Ihre Pipeline speziell durch eine öffentliche Einreich-API blockiert ist, wenden Sie sich an den Support und schildern Sie den Anwendungsfall — die Roadmap wird durch echte Pipeline-Anforderungen geprägt.
Q: Wie erkenne ich, dass ein Render-Job abgeschlossen ist, wenn es keine Status-API gibt?
A: Fragen Sie das SFTP-Ausgabeverzeichnis des Jobs ab, /output/<job-id>/, und beobachten Sie die Frame-Anzahl. Behandeln Sie den Job erst dann als abgeschlossen, wenn die Anzahl die erwartete Gesamtzahl erreicht und über aufeinanderfolgende Prüfungen hinweg stabil bleibt, damit Sie nicht laden, während Frames noch geschrieben werden. Es ist eine Verzeichnisheuristik und kein offizielles Status-Signal, aber sie stützt sich nur auf Fähigkeiten, die heute bereits vorhanden sind.
Q: Soll ich SSH-Keys oder ein Passwort für automatisierte Transfers verwenden? A: Verwenden Sie einen SSH-Key. Ein Passwort fest im Skript zu hinterlegen ist ein Sicherheitsrisiko, und die Key-Authentifizierung läuft unbeaufsichtigt ohne interaktive Eingabeaufforderung. Generieren Sie einen ed25519-Key, registrieren Sie die öffentliche Hälfte unter Settings → SFTP → SSH Keys und schützen Sie den privaten Key mit einer Passphrase, die ein SSH-Agent hält. Da Zwei-Faktor-Authentifizierung auf Konten derzeit nicht unterstützt wird, ist der Key plus seine Passphrase die stärkste praktische Absicherung für den SFTP-Zugang.
Q: Kann ich ein .zip-Archiv aus meinem Skript hochladen?
A: Nein — .zip-Archive werden nicht unterstützt. Packen Sie als .tar.gz (oder .tar / .7z) um, oder lassen Sie das Archivieren weg und lassen Sie rsync den Ordnerbaum direkt übertragen, was für Projekte, die sich zwischen Uploads ändern, normalerweise die bessere Option ist. Halten Sie einen einzelnen Upload unter ca. 300 GB und verwenden Sie rsync --partial für alles Größere, damit eine unterbrochene Verbindung fortgesetzt statt neu gestartet wird.
Q: Wie groß darf ein Projekt sein, das ich so übertragen kann?
A: Multi-Terabyte-Transfers werden über SFTP unterstützt; die praktische Grenze ist Ihre eigene Upload-Bandbreite, keine farm-seitige Begrenzung. Ein 1-TB-Upload bei 100 Mbps dauert ungefähr einen Tag, planen Sie also entsprechend. Für maximalen Durchsatz bei schnellen oder Weitstreckenverbindungen verwenden Sie lftp mit parallelen Segmenten oder mehrere gleichzeitige SFTP-Sitzungen, da ein einzelner SFTP-Stream durch den Overhead pro Paket begrenzt ist.
Q: Wie lange sind meine gerenderten Frames zum Herunterladen verfügbar?
A: Die Ausgabe wird 45 Tage nach Jobabschluss aufbewahrt und dann automatisch gelöscht. SFTP verlängert dieses Fenster nicht. Für eine unbeaufsichtigte Pipeline spiegeln Sie die Ausgabe in ein lokales Archiv, sobald sie erscheint — ein nächtliches rsync-Pull von /output/<job-id>/ stellt sicher, dass die Aufbewahrungsfrist nie der Grund ist, warum ein Frame verloren geht.
Q: Wie unterscheidet sich das von Ihrem Leitfaden zu headless und unbeaufsichtigten Workflows?
A: Jener Leitfaden ist die konzeptionelle Übersicht — was Headless-Rendering bedeutet, wie man Szenen für das Rendering über die Befehlszeile vorbereitet und wie die unbeaufsichtigte Schleife auf einer verwalteten render farm zusammenpasst. Dieser hier ist der Code-Level-Begleiter mit Fokus auf die Transferschicht: das eigentliche paramiko und rsync, das Sie schreiben, um Projekte hochzuladen und Frames herunterzuladen. Lesen Sie den Workflow-Leitfaden für die Gesamtstruktur; verwenden Sie diesen für die Implementierung.
About Alice Harper
Blender and V-Ray specialist. Passionate about optimizing render workflows, sharing tips, and educating the 3D community to achieve photorealistic results faster.



