
Automazione upload per render farm con Python: guida a paramiko e rsync
Panoramica
La parte più lenta di un render cloud spesso non è il render in sé. Per uno studio che ogni notte invia una ripresa VFX multi-camera o una cache Houdini da 400 GB a una render farm, il collo di bottiglia è spostare i dati: caricare il progetto in modo affidabile e scaricare i frame completati prima che il team arrivi al mattino. Fare tutto a mano, guardando una barra di avanzamento a mezzanotte, non è scalabile. Automatizzarlo lo è.
Questa guida spiega come automatizzare il livello di trasferimento in Python. Gestiamo Super Renders Farm, una render farm completamente gestita, e "completamente gestita" ha un significato preciso per l'automazione: non si accede alle macchine da remoto, non si installa software, non si gestiscono licenze — la parte della pipeline che si controlla via script è quella che si possiede davvero: i file in ingresso e i render in uscita. La superficie di trasferimento è genuinamente scriptabile via SFTP, e Python è un modo di prima classe per gestirla. La documentazione ufficiale di Super Renders Farm nomina direttamente la libreria paramiko di Python come client supportato, insieme a rsync via SSH e al comando standard sftp.
La guida è altrettanto precisa su ciò che oggi non è possibile automatizzare da Python, perché una pipeline costruita su una funzionalità che non esiste è una pipeline destinata a fallire al primo avvio non presidiato. Per una panoramica concettuale più ampia — cosa significano "headless" e "unattended", come preparare le scene per il rendering da riga di comando — esiste una guida companion separata. Questa rimane al livello del codice, concentrandosi sul livello di trasferimento: paramiko, rsync, chiavi SSH, retry e un pattern di sincronizzazione notturna da integrare nell'automazione dello studio.
Cosa si può automatizzare in Python oggi
Prima di scrivere qualsiasi codice conviene delimitare il perimetro. Su una farm gestita, alcune parti della pipeline sono completamente scriptabili, altre sono deliberatamente orientate alla GUI, e una si trova a metà strada. Essere precisi su questo punto evita che l'automazione si interrompa in silenzio.
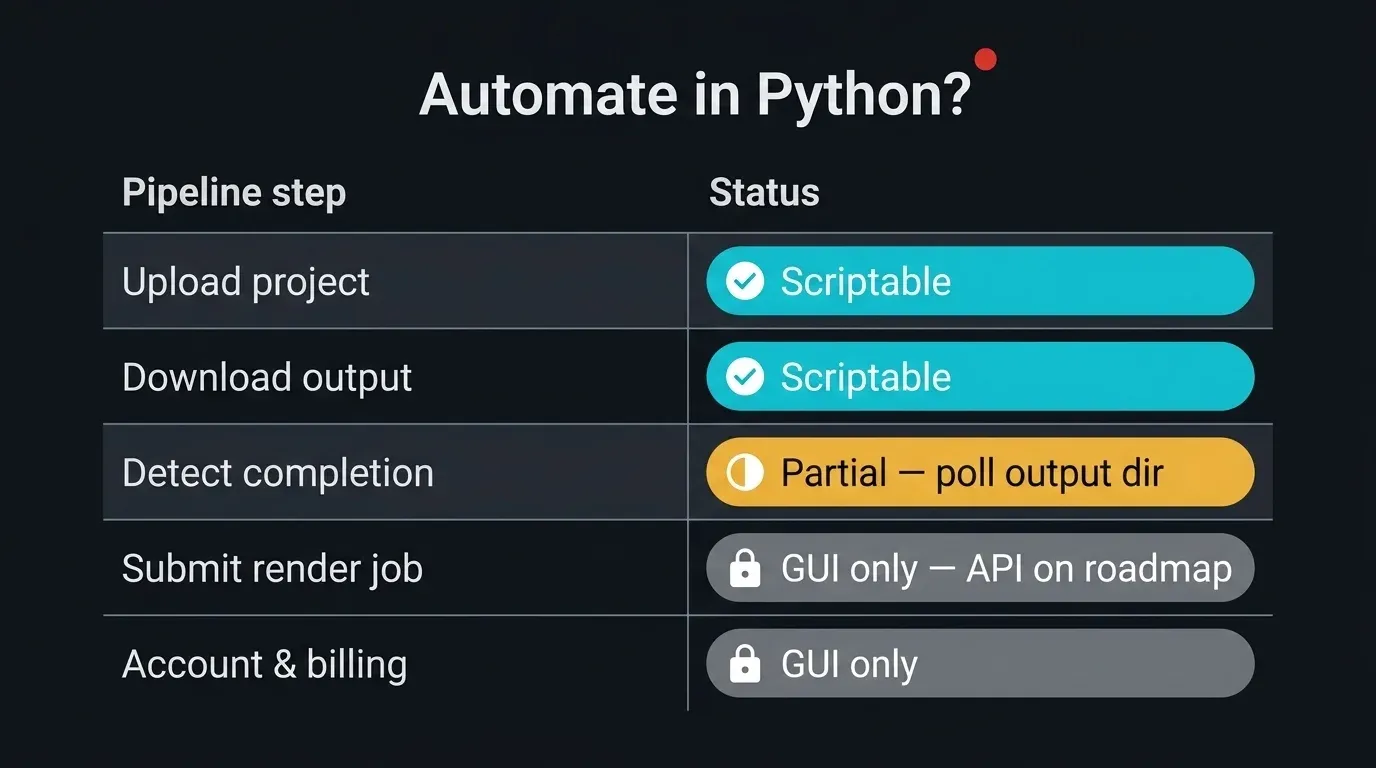
Diagramma a matrice che mostra quali passaggi della pipeline di una render farm cloud gestita possono essere automatizzati in Python: Upload del progetto (completamente scriptabile via paramiko, rsync, sftp), Download dell'output (completamente scriptabile), Rilevamento del completamento del job (parziale — polling della directory di output SFTP, nessuna API di stato), Invio del job di rendering (solo GUI — modulo web, Client App o plugin DCC), Gestione account e fatturazione (solo GUI), con colonne di stato verde, ambra e grigio
- Caricamento di un progetto — completamente scriptabile. SFTP con
paramiko,rsynco comandisftpda script funzionano sul server SFTP. È il nucleo di quanto segue. - Download dei frame completati — completamente scriptabile. L'output viene scritto in una directory per job che si può recuperare con gli stessi strumenti.
- Rilevamento del completamento di un job — parziale. Non esiste un'API di stato pubblica su cui fare polling. È possibile però monitorare la directory di output SFTP e attendere che i frame compaiano e si stabilizzino. Si tratta di un'euristica, non di un segnale ufficiale, e viene trattata come tale più avanti.
- Invio di un job di rendering — solo GUI al momento. L'invio avviene tramite il modulo web, la SuperRenders Client App o un plugin di invio specifico per DCC. Un'API REST pubblica per l'invio dei job, il polling dello stato e il recupero dell'output è nella roadmap, ma al momento non sono disponibili endpoint pubblici per l'integrazione diretta. Se la pipeline è bloccata specificamente sull'assenza di un'API di invio, è possibile contattare il supporto e descrivere il caso d'uso — la roadmap viene definita anche in base a requisiti di pipeline reali.
- Gestione account, crediti o fatturazione — solo GUI. Non rientra nell'automazione del trasferimento.
La superficie automatizzabile riguarda quindi il trasferimento: caricare il progetto, scaricare i render e colmare il divario nel mezzo monitorando la directory di output. Il passaggio di invio rimane un handoff deliberato, che verrà indicato chiaramente nella pipeline finale senza fingere che non esista. Per una trattazione più completa di ciò che il rendering gestito espone o meno, la guida su cos'è una render farm completamente gestita copre il modello; i nuovi account possono partire dalla guida introduttiva.
Prerequisiti: accesso SFTP, chiavi SSH e ambiente Python
Tre elementi devono essere in ordine prima del primo upload automatizzato.
Accesso SFTP, abilitato per account. L'SFTP viene abilitato su richiesta per ogni account. Accedere, cercare "SFTP access" nelle impostazioni dell'account e generare le credenziali lì; se non è visibile, contattare il supporto per abilitarlo. Le credenziali includono un hostname del server (varia per regione e allocazione di storage — va letto dalla configurazione, mai scritto fisso nel codice), un nome utente legato all'account, una password o una chiave SSH e la porta SFTP standard 22. Due path sono rilevanti: /uploads/<cartella-progetto>/ è l'area di scrittura, e /output/<job-id>/ è dove compaiono i render completati.
Una chiave SSH, non una password. Per qualsiasi operazione automatizzata, l'autenticazione tramite chiave SSH è la scelta corretta: mantiene i segreti fuori dagli script e funziona in esecuzione non presidiata senza prompt interattivi. Generare una coppia di chiavi moderna e registrare la parte pubblica sull'account:
ssh-keygen -t ed25519 -C "pipeline@yourstudio.example"
# aggiungere il contenuto di ~/.ssh/id_ed25519.pub in
# superrendersfarm.com -> Settings -> SFTP -> SSH Keys
Una nota sulla sicurezza dell'account: l'autenticazione a due fattori non è attualmente supportata, quindi per SFTP il rafforzamento più efficace consiste in una passphrase sul file della chiave più un agente SSH che la mantiene sbloccata per la sessione. La chiave più la conoscenza della passphrase svolge un ruolo simile a un secondo fattore — possesso più segreto.
Un ambiente Python con paramiko. Tutto ciò che segue usa paramiko, la libreria Python pura per SSH/SFTP, e lancia rsync per i trasferimenti incrementali di grandi dimensioni.
python3 -m venv .venv && source .venv/bin/activate
pip install paramiko
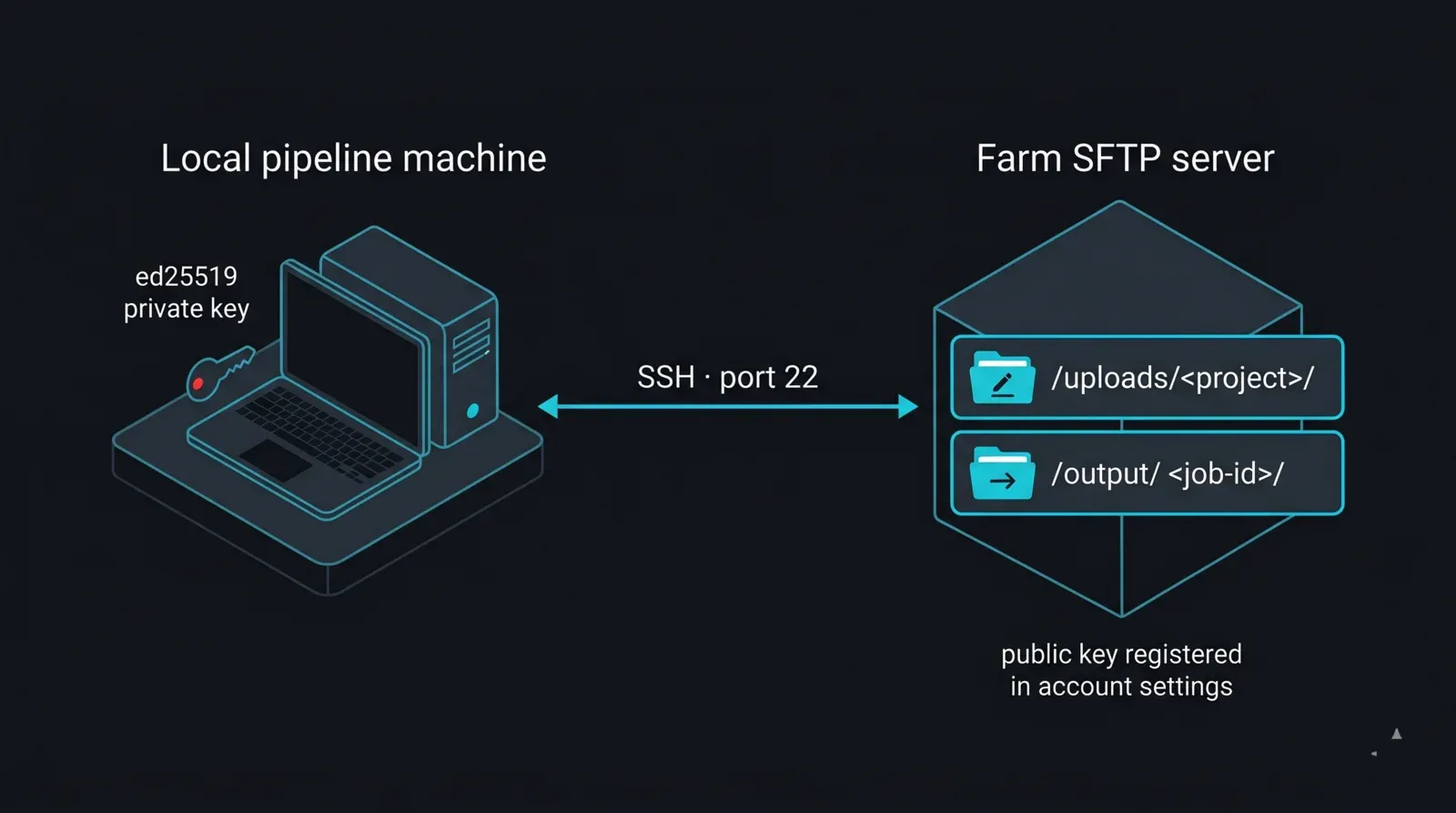
Diagramma del layout dell'account SFTP e dell'autenticazione con chiave per una render farm gestita: una macchina pipeline locale con una chiave privata ed25519 si connette via SSH porta 22 al server SFTP della farm, che espone due directory — /uploads/<progetto>/ come area di scrittura per i progetti in ingresso e /output/<job-id>/ come area di lettura per i frame completati; la chiave pubblica corrispondente è registrata nelle impostazioni dell'account
Preparare un progetto affinché sopravviva a un upload non presidiato
La maggior parte dei job di rendering falliti non dipende da bug del motore — si tratta di lacune nel packaging. Una scena che si renderizza sulla workstation dell'artista fallisce su un worker vuoto perché un percorso texture punta a un disco locale, o una sub-scena referenziata non è stata inclusa nel bundle. L'automazione amplifica questo problema: un upload non presidiato di un pacchetto mal configurato produce un fallimento non presidiato. Due regole mantengono i pacchetti integri.
Prima regola: rendere il progetto autocontenuto con percorsi relativi. Eseguire il comando di raccolta e packaging del proprio DCC (Archive, Collect Files, Save Project with Assets) in modo che ogni texture, proxy e cache si risolva in modo relativo alla radice del progetto. Seconda regola: prestare attenzione al formato di archiviazione se si comprime prima dell'upload: Super Renders Farm supporta tar, tar.gz e 7z, ma non .zip — ricreare il pacchetto come .tar.gz, o rinunciare all'archivio e lasciare che rsync trasferisca l'albero di cartelle, soluzione generalmente migliore per i progetti in evoluzione. Come limite pratico, mantenere un singolo upload sotto ~300 GB; sopra questa soglia, conviene affidarsi a rsync con ripresa piuttosto che a un singolo trasferimento monolitico.
Caricare un progetto con paramiko
Il primo blocco di base è un uploader ricorsivo. Si connette con una chiave, percorre l'albero locale del progetto, ricrea la struttura di directory sotto /uploads/ e carica ogni file. Il pinning delle chiavi host avviene con RejectPolicy e i dettagli di connessione vengono letti dalle variabili d'ambiente, così nessun dato sensibile risiede nello script.
import os
import paramiko
def connect():
host = os.environ["SRF_SFTP_HOST"]
user = os.environ["SRF_SFTP_USER"]
key_path = os.environ["SRF_SFTP_KEY"] # percorso alla chiave privata
client = paramiko.SSHClient()
client.load_system_host_keys() # trust solo ~/.ssh/known_hosts
client.set_missing_host_key_policy(paramiko.RejectPolicy())
client.connect(hostname=host, port=22, username=user, key_filename=key_path)
return client, client.open_sftp()
def _ensure_remote_dir(sftp, remote_dir):
# mkdir -p via SFTP: costruisce il percorso un segmento alla volta
path = ""
for segment in remote_dir.strip("/").split("/"):
path += "/" + segment
try:
sftp.stat(path)
except IOError:
sftp.mkdir(path)
def upload_dir(sftp, local_dir, remote_dir):
for root, _dirs, files in os.walk(local_dir):
rel = os.path.relpath(root, local_dir)
remote_root = remote_dir if rel == "." else f"{remote_dir}/{rel.replace(os.sep, '/')}"
_ensure_remote_dir(sftp, remote_root)
for name in files:
local_path = os.path.join(root, name)
remote_path = f"{remote_root}/{name}"
sftp.put(local_path, remote_path)
print(f"uploaded {remote_path}")
Come si usa per un progetto:
client, sftp = connect()
try:
upload_dir(sftp, "/local/projects/archviz-tower", "/uploads/archviz-tower-2026-06")
finally:
sftp.close()
client.close()
Questo è sufficiente per progetti di piccole e medie dimensioni. sftp.put accetta anche un argomento callback= che riceve byte trasferiti e totale, collegabile a un indicatore di avanzamento o a una riga di log per file. Per i trasferimenti grandi e ripetuti tipici del lavoro in studio, però, rsync è lo strumento più adatto.
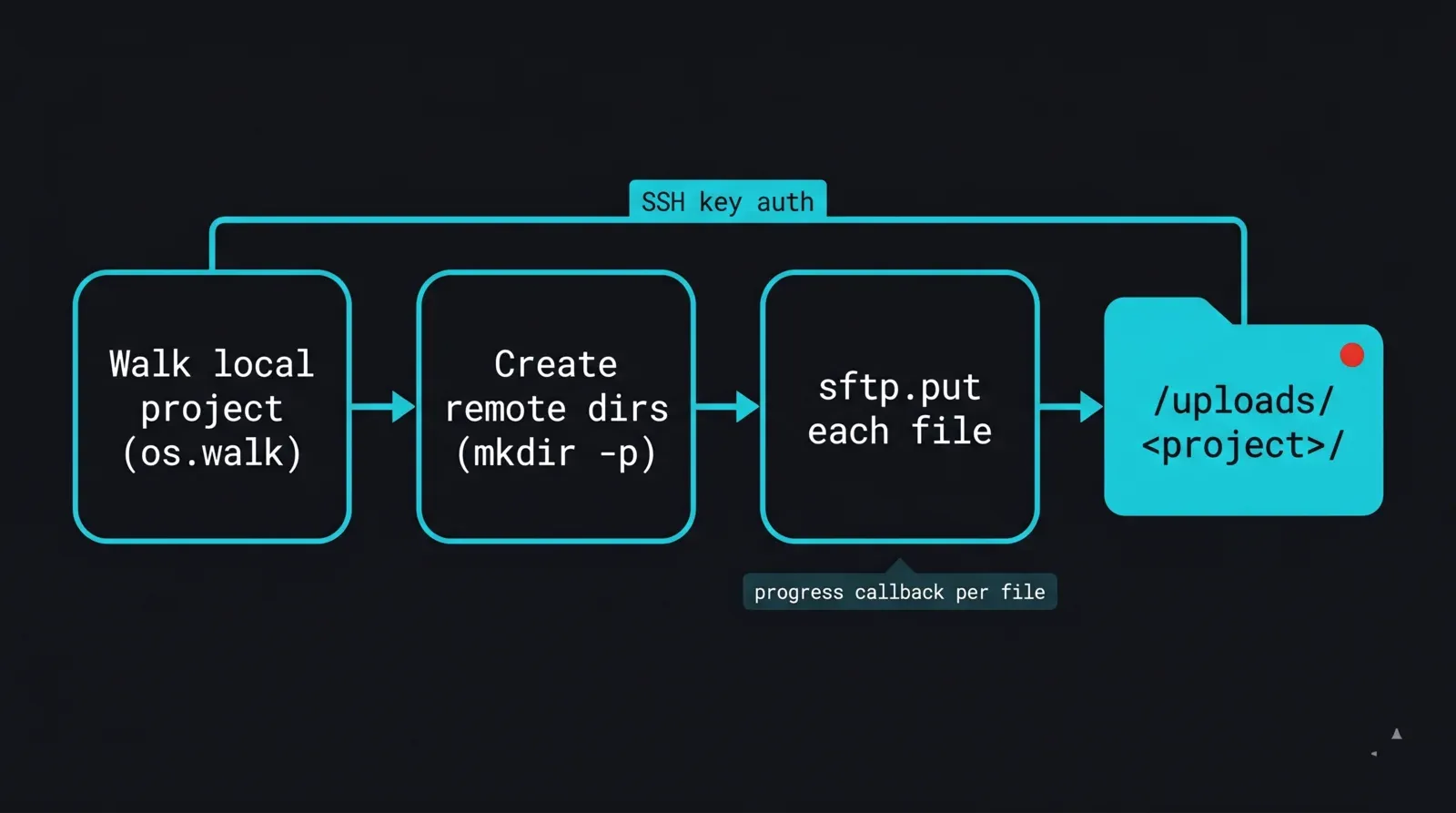
Diagramma di flusso di una routine di upload con paramiko per una render farm: una cartella di progetto locale viene percorsa file per file con os.walk, la struttura di directory remota viene creata sotto /uploads con un loop mkdir-p, poi ogni file viene inviato con sftp.put attraverso una connessione autenticata con chiave SSH, con una callback di avanzamento che registra ogni file completato
Sincronizzazione incrementale con rsync via SSH
Un progetto di rendering raramente viene caricato una volta sola. Si modifica uno shader, si ricalcola una sim, si sistema una luce e si ricarica. Inviare ogni volta l'intera cartella fa perdere ore; rsync invia solo le modifiche. Per uno studio che carica ogni notte, questo è il singolo risparmio di tempo maggiore nel livello di trasferimento, perché trasferisce solo il delta anziché il progetto intero.
La chiamata canonica:
rsync -avz --partial --progress \
/local/projects/archviz-tower/ \
"$SRF_SFTP_USER@$SRF_SFTP_HOST:/uploads/archviz-tower-2026-06/"
-a preserva struttura e timestamp, -z comprime in volo, --partial mantiene i file parzialmente trasferiti in modo che una connessione interrotta riprenda invece di ricominciare, e --progress riporta lo stato per ogni file. Rieseguire lo stesso comando dopo una modifica trasferisce solo i file modificati. Poiché l'obiettivo è l'automazione, conviene racchiuderlo in Python in modo che viva nello stesso script del resto e che sia possibile reagire al suo codice di uscita:
import subprocess
def rsync_up(local_dir, remote_subdir):
host = os.environ["SRF_SFTP_HOST"]
user = os.environ["SRF_SFTP_USER"]
dest = f"{user}@{host}:/uploads/{remote_subdir}/"
cmd = ["rsync", "-avz", "--partial", "--progress",
f"{local_dir.rstrip('/')}/", dest]
subprocess.run(cmd, check=True) # genera CalledProcessError in caso di errore
Per eseguirlo in modo non presidiato, si può pianificarne l'esecuzione. Uno studio che sincronizza una directory di lavoro con la farm ogni notte all'1:00 ha bisogno di una sola riga cron:
0 1 * * * cd /studio/pipeline && /usr/bin/python3 nightly_sync.py >> sync.log 2>&1
Perché rsync via SSH si autentichi senza prompt, è necessario puntarlo alla chiave con -e "ssh -i ~/.ssh/id_ed25519", oppure lasciare che un agente SSH mantenga la chiave sbloccata per la sessione.
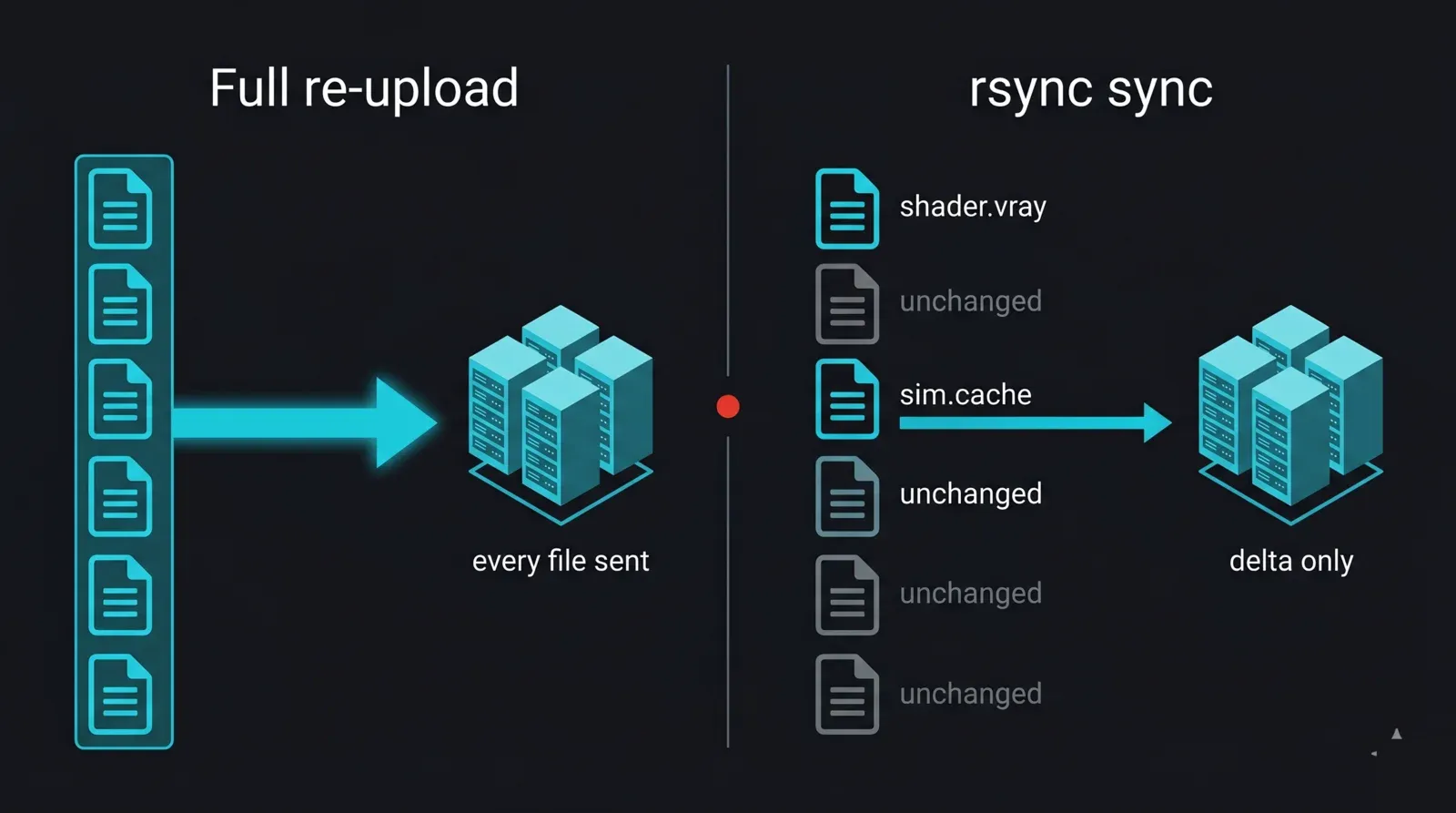
Diagramma prima-e-dopo che contrappone un re-upload completo con una sincronizzazione incrementale rsync su una render farm: a sinistra, ogni file del progetto viene reinviato ogni notte; a destra, rsync confronta locale e remoto e trasferisce solo i file modificati (uno shader modificato e una nuova cache), con il bulk invariato che viene saltato, illustrando il trasferimento solo-delta che rende veloci gli upload notturni in studio
Scaricare automaticamente i frame completati
Quando un job è completato, i frame di output vengono scritti in /output/<job-id>/ sul server SFTP. Il lato download è speculare al lato upload — un get ricorsivo con paramiko, o un pull rsync. La versione paramiko percorre la directory remota e la ricrea localmente:
import stat
def download_dir(sftp, remote_dir, local_dir):
os.makedirs(local_dir, exist_ok=True)
for entry in sftp.listdir_attr(remote_dir):
remote_path = f"{remote_dir}/{entry.filename}"
local_path = os.path.join(local_dir, entry.filename)
if stat.S_ISDIR(entry.st_mode):
download_dir(sftp, remote_path, local_path)
else:
sftp.get(remote_path, local_path)
print(f"downloaded {local_path}")
Per set di output di grandi dimensioni, il pull rsync è di nuovo la scelta più efficiente e riprendibile:
rsync -avz --progress \
"$SRF_SFTP_USER@$SRF_SFTP_HOST:/output/<job-id>/" \
/local/downloads/<job-id>/
Un dettaglio operativo rilevante per le pipeline non presidiate: l'output renderizzato viene conservato per 45 giorni dal completamento del job, poi eliminato automaticamente. L'SFTP non estende questa finestra. Il pattern sicuro è una sincronizzazione notturna che rispecchia l'output su archivio locale non appena compare, in modo che la retention non sia mai il motivo per cui un frame va perduto.
Rilevare il completamento del job senza un'API di stato
Qui il confine onesto diventa una scelta ingegneristica concreta. Non esiste un endpoint pubblico per chiedere "il job 12345 è terminato?" — ma la directory di output è osservabile via SFTP. Il pattern pragmatico consiste nel fare polling di /output/<job-id>/, contare i file e attendere che il conteggio raggiunga il totale di frame atteso e rimanga stabile tra controlli consecutivi (per evitare di iniziare il download mentre i file vengono ancora scritti).
import time
def wait_for_output(sftp, output_dir, expected_frames, poll=120, stable_checks=2):
last_count, stable = -1, 0
while True:
try:
files = sftp.listdir(output_dir)
except IOError:
files = [] # cartella non ancora creata -> non avviato
count = len(files)
if count >= expected_frames and count == last_count:
stable += 1
if stable >= stable_checks:
return files # conteggio raggiunto e stabile -> trattare come completato
else:
stable = 0
last_count = count
time.sleep(poll)
È importante essere chiari su cosa rappresenta questo approccio. I frame compaiono in modo incrementale, quindi la sola presenza non indica il completamento; verificare che il conteggio corrisponda al totale atteso e che rimanga stabile tra i poll è ciò che lo rende abbastanza affidabile per l'automazione. Si tratta di un'euristica sulla directory, non di un contratto. Quando l'API pubblica sarà disponibile, questa intera funzione si ridurrà a una chiamata di stato — fino ad allora, monitorare la directory di output è il modo concreto per colmare il divario, e si basa solo su capacità già esistenti.
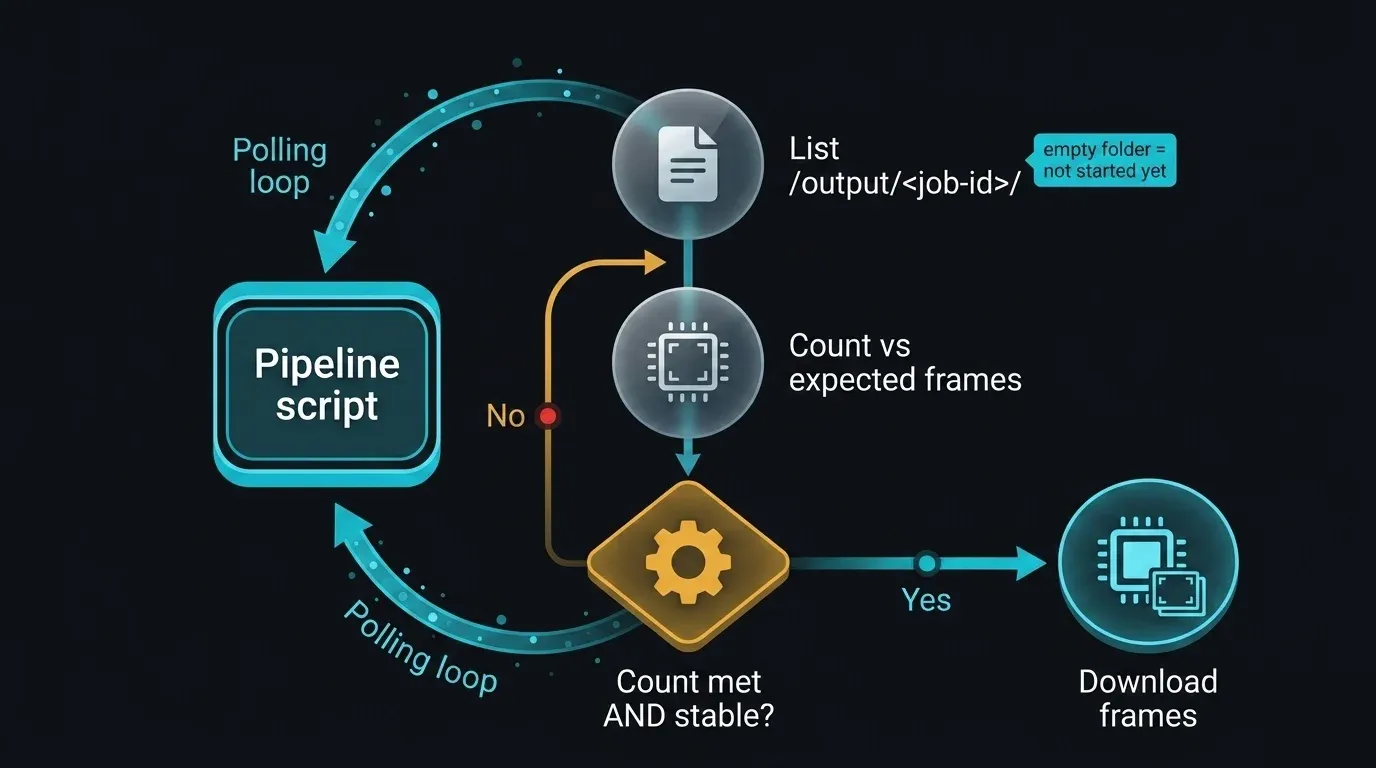
Diagramma di sequenza del polling della directory di output SFTP per rilevare il completamento del rendering senza un'API di stato: uno script pipeline elenca ripetutamente /output/<job-id>/, confronta il conteggio dei frame con il totale atteso, attende che il conteggio raggiunga l'obiettivo e rimanga stabile su due controlli consecutivi, poi procede al download — con uno stato iniziale di cartella vuota mostrato come job-non-avviato
Mettere tutto insieme: una pipeline di trasferimento non presidiata
I componenti si compongono in un unico script notturno. La struttura è: sincronizzare il progetto in upload, passare la mano per l'invio, attendere che l'output compaia e si stabilizzi, scaricarlo, verificarlo e archiviarlo. Il passaggio di invio è l'handoff deliberato alla GUI — su una farm gestita l'invio avviene tramite il modulo web, la Client App o un plugin di invio DCC; i plugin per DCC possono essere azionati dall'ambiente di scripting dell'applicazione host (MAXScript, Python all'interno del DCC) quando l'invio risiede in uno strumento già scriptato. Questo passaggio viene indicato in modo trasparente invece di avvolgerlo in una funzione che finge che un'API esista.
def nightly_pipeline(project_dir, remote_subdir, job_id, expected_frames):
client, sftp = connect()
try:
# with_retries() (definito nella sezione successiva) avvolge le chiamate di rete fragili
with_retries(lambda: rsync_up(project_dir, remote_subdir)) # 1. carica delta
# 2. INVIO: GUI / Client App / plugin DCC -- nessuna API pubblica (ancora)
files = wait_for_output( # 3. monitora directory output
sftp, f"/output/{job_id}", expected_frames)
with_retries(lambda: # 4. scarica frame completati
download_dir(sftp, f"/output/{job_id}", f"/local/downloads/{job_id}"))
print(f"job {job_id}: {len(files)} frames retrieved")
finally:
sftp.close()
client.close()
I passaggi 1, 3 e 4 sono completamente automatizzati; il passaggio 2 è l'handoff. Quando un'API di invio pubblica sarà disponibile, i passaggi 2 e 3 diventeranno chiamate API e il polling della directory andrà in pensione. L'architettura non cambia — solo le fasi di invio e stato passeranno da GUI ed euristica a endpoint.
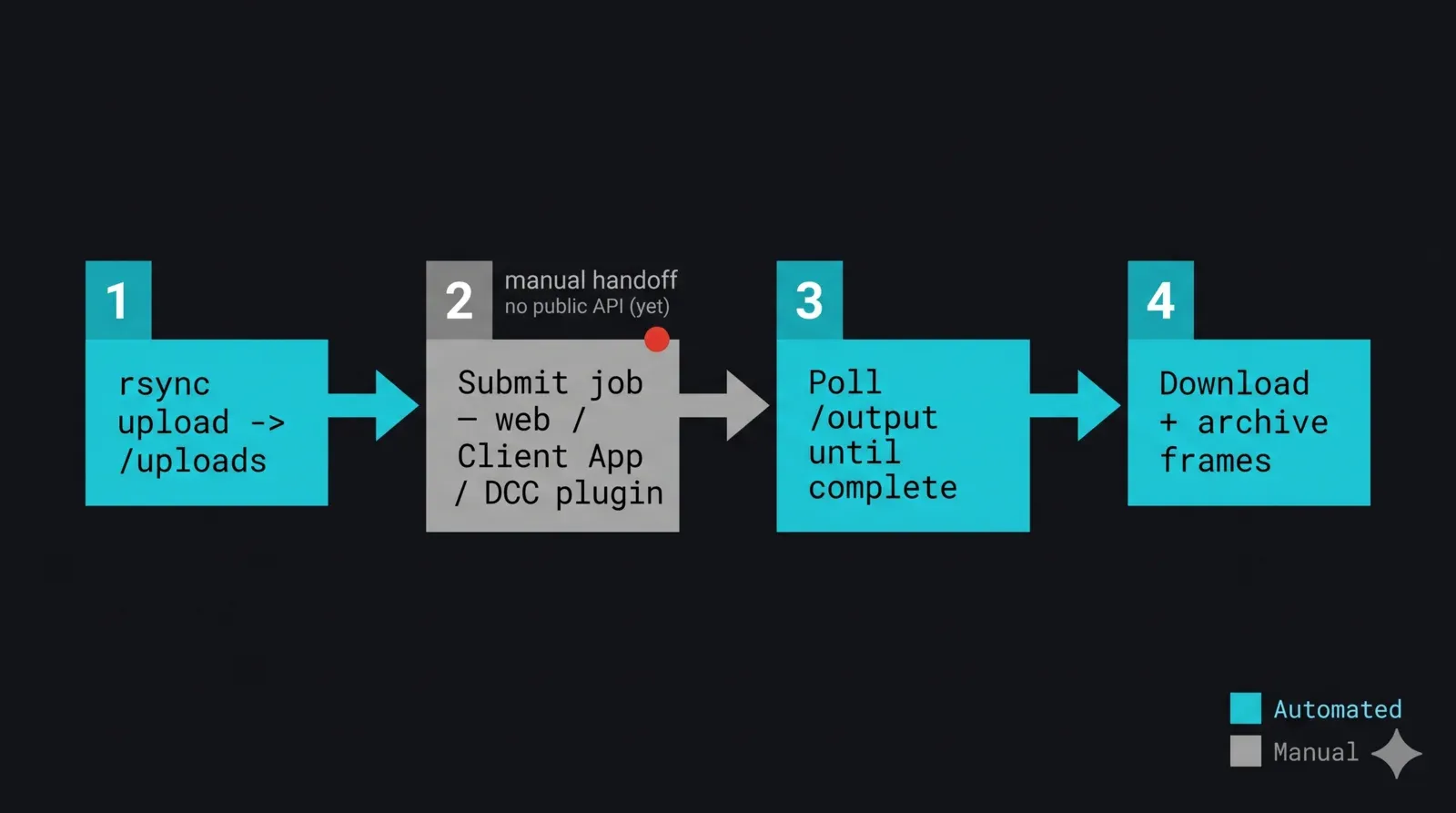
Diagramma di flusso end-to-end di una pipeline di trasferimento su render farm non presidiata gestita da Python: il passaggio 1 con rsync carica il delta del progetto in /uploads, il passaggio 2 è un handoff GUI chiaramente indicato in cui il job viene inviato tramite modulo web, Client App o plugin DCC (nessuna API pubblica), il passaggio 3 effettua polling di /output/<job-id> finché i frame non sono completi e stabili, il passaggio 4 scarica e archivia i frame completati localmente — con i passaggi automatizzati in ciano e il passaggio di invio manuale in grigio
Gestione degli errori, retry e trasferimenti riprendibili
Non presidiato significa che nessuno sta guardando quando un trasferimento si interrompe, quindi lo script deve ripristinarsi da solo. Tre abitudini coprono la maggior parte dei fallimenti.
Retry dei fallimenti transienti con backoff. I cali di rete e le brevi disconnessioni sono normali durante trasferimenti lunghi. Avvolgere le chiamate fragili — come fa nightly_pipeline sopra — in modo che una singola caduta non blocchi l'intera esecuzione. Catturare gli errori transienti specifici anziché tutto: SSHException di paramiko, la famiglia OSError per i socket e CalledProcessError per un rsync fallito.
def with_retries(fn, attempts=3, backoff=5):
transient = (paramiko.SSHException, OSError, subprocess.CalledProcessError)
for i in range(1, attempts + 1):
try:
return fn()
except transient: # retry su SSH / rete / rsync
if i == attempts:
raise
time.sleep(backoff * i) # backoff: 5s, 10s, 15s
Sfruttare la riprendibilità. rsync --partial riprende già i file interrotti, e rieseguire un rsync è idempotente — invia solo ciò che manca — quindi un sync ripetuto è economico, non un riavvio. Per i trasferimenti con paramiko, un retry con ri-walk ottiene lo stesso effetto perché i file già presenti vengono trasferiti quasi istantaneamente.
Gestire esplicitamente gli errori di chiave host e connettività. Un errore "host key verification failed" significa che la chiave in cache in ~/.ssh/known_hosts non corrisponde più a quella del server — il più delle volte dopo una rara rotazione della chiave host. Rimuovere la riga obsoleta indicata nell'errore e riconnettersi per accettare la nuova chiave. Connessione rifiutata o timeout indica generalmente che il firewall dello studio blocca il TCP 22 in uscita — consentirlo o contattare il supporto per alternative. Se il throughput rimane molto al di sotto della velocità del collegamento, l'overhead per pacchetto di SFTP è la causa su collegamenti a lunga distanza — lftp con segmenti paralleli, o diverse sessioni SFTP concorrenti, recupera gran parte del divario.
Riepilogo: cosa automatizzare e come
Il livello di trasferimento è la parte di una pipeline su farm gestita che si controlla via codice, e Python la copre interamente.
| Attività | Automatizzabile in Python? | Strumento | Note |
|---|---|---|---|
| Caricamento di un progetto | Sì | paramiko o rsync | rsync per upload grandi/ripetuti; --partial per riprendere |
| Re-upload incrementale | Sì | rsync via SSH | Trasferisce solo i file modificati |
| Download dei frame completati | Sì | get paramiko / pull rsync | Sincronizzare ogni notte — retention 45 giorni |
| Rilevamento completamento | Parziale | Polling /output/<job-id>/ | Euristica su conteggio + stabilità, nessuna API di stato |
| Invio di un job di rendering | No (oggi) | Web / Client App / plugin DCC | API pubblica nella roadmap |
| Autenticazione | Sì | Chiave SSH (ed25519) | Chiave + passphrase; nessun segreto scritto nel codice |
Automatizzare l'upload, automatizzare il download, colmare il mezzo monitorando la directory di output e mantenere l'handoff di invio esplicito. Questo produce una pipeline notturna che è onesta nei confronti dei propri punti di giuntura ed è affidabile proprio per questo. Per i progetti con simulazioni pesanti dove l'affidabilità del trasferimento conta di più — cache Houdini da più terabyte e simili — gli stessi pattern si scalano direttamente su Super Renders Farm; la pagina Houdini cloud render farm copre quel tipo di carico.
FAQ
Q: Quale libreria Python usare per caricare file sulla render farm?
A: paramiko è la scelta standard ed è citata direttamente nella documentazione SFTP di Super Renders Farm come client supportato. È puro Python, gestisce SFTP in modo pulito e funziona bene sia per l'upload che per il download. Per trasferimenti molto grandi o frequentemente ripetuti, conviene lanciare rsync via SSH da Python con subprocess — invia solo i file modificati e riprende quelli interrotti, operazioni che paramiko non esegue nativamente.
Q: Esiste un'API pubblica per inviare job di rendering dalla pipeline Python?
A: Non ancora. Un'API REST pubblica per l'invio, il polling dello stato e il recupero dell'output è nella roadmap, ma oggi non sono disponibili endpoint pubblici. I percorsi di invio programmatico attualmente disponibili sono la SuperRenders Client App e il plugin di invio specifico per DCC, che si integra con l'ambiente di scripting dell'applicazione host come MAXScript o Python all'interno del DCC. Se la pipeline è bloccata specificamente sull'assenza di un'API di invio pubblica, è possibile contattare il supporto e descrivere il caso d'uso — la roadmap viene definita anche in base a requisiti di pipeline reali.
Q: Come rilevare che un job di rendering è terminato se non esiste un'API di stato?
A: Fare polling della directory di output SFTP del job, /output/<job-id>/, e monitorare il conteggio dei frame. Trattare il job come completato solo quando il conteggio raggiunge il totale atteso e rimane stabile tra controlli consecutivi, per evitare di avviare il download mentre i frame vengono ancora scritti. Si tratta di un'euristica sulla directory piuttosto che di un segnale di stato ufficiale, ma si basa solo su capacità già esistenti.
Q: Per i trasferimenti automatizzati conviene usare chiavi SSH o password?
A: Conviene usare una chiave SSH. Inserire una password in uno script è un rischio per la sicurezza, e l'autenticazione con chiave funziona in modo non presidiato senza prompt interattivi. Generare una chiave ed25519, registrare la parte pubblica in Settings → SFTP → SSH Keys e proteggere la chiave privata con una passphrase gestita da un agente SSH. Poiché l'autenticazione a due fattori non è attualmente supportata sugli account, la chiave più la sua passphrase è il rafforzamento pratico più efficace per l'accesso SFTP.
Q: È possibile caricare un archivio .zip tramite script?
A: No — gli archivi .zip non sono supportati. Ricreare il pacchetto come .tar.gz (o .tar / .7z), oppure rinunciare all'archivio e lasciare che rsync trasferisca l'albero di cartelle direttamente, opzione generalmente migliore per i progetti che cambiano tra un upload e l'altro. Mantenere un singolo upload sotto circa 300 GB e usare rsync --partial per dimensioni maggiori in modo che una connessione interrotta riprenda invece di ricominciare.
Q: Qual è la dimensione massima di un progetto trasferibile in questo modo?
A: I trasferimenti multi-terabyte sono supportati via SFTP; il limite pratico è la larghezza di banda di upload disponibile, non un tetto imposto dalla farm. Un upload da 1 TB a 100 Mbps richiede circa un giorno, quindi è necessario pianificare in base al proprio collegamento. Per il throughput massimo su connessioni veloci o a lunga distanza, conviene usare lftp con segmenti paralleli o diverse sessioni SFTP concorrenti, poiché un singolo stream SFTP è limitato dall'overhead per pacchetto.
Q: Per quanto tempo i frame renderizzati rimangono disponibili per il download?
A: L'output viene conservato per 45 giorni dal completamento di un job, poi eliminato automaticamente, e l'SFTP non estende questa finestra. Per una pipeline non presidiata, conviene sincronizzare l'output su archivio locale non appena compare — un pull rsync notturno di /output/<job-id>/ evita che la retention diventi la ragione per cui un frame va perduto.
Q: In cosa differisce questa guida dalla guida headless e unattended?
A: Quella guida è la mappa concettuale — cosa significa rendering headless, come preparare le scene per il rendering da riga di comando e come si articola il loop unattended su una farm gestita. Questa è la guida companion al livello del codice, focalizzata sul livello di trasferimento: il codice paramiko e rsync concreto per spostare i progetti in upload e i frame in download. La guida al workflow serve per comprendere la struttura; questa serve per l'implementazione.
About Alice Harper
Blender and V-Ray specialist. Passionate about optimizing render workflows, sharing tips, and educating the 3D community to achieve photorealistic results faster.



