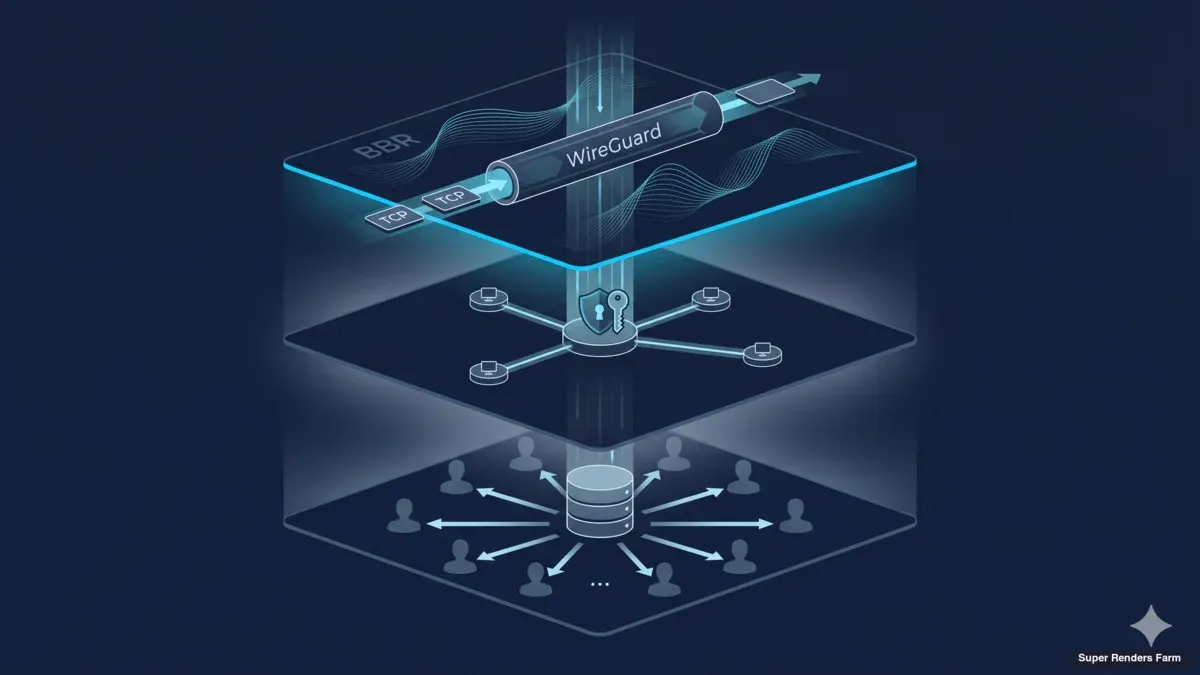
Architecture de render farm cross-country : WireGuard, BBR et cache SMB partagé
Aperçu
Introduction
Construire une render farm qui vit dans un seul rack, dans une seule pièce, sur un seul switch, est un problème résolu. Les câbles sont courts, les temps d'aller-retour se mesurent en microsecondes, et la bibliothèque d'assets vit sur un NAS que chaque worker lit à la vitesse du port switch. La plupart des guides de render farm supposent silencieusement cette topologie, parce que c'est celle où tout marche.
L'architecture change dès que la ferme doit s'étendre à plus d'un site. Un cluster de 20 nœuds réparti sur deux emplacements dans la même métropole est déjà un problème réseau différent ; un cluster qui s'étend à travers les pays est encore un autre problème. Les temps d'aller-retour passent de sous-milliseconde à des dizaines ou des centaines de millisecondes, le jitter sur les routes ISP publiques devient un bruit de fond constant, la MTU entre deux endpoints devient une question plutôt qu'une hypothèse, et la bibliothèque d'assets qui vivait sur un seul NAS doit maintenant soit se répliquer à chaque site, soit se mettre en cache à la demande. L'approche naïve — même NAS, même file d'attente de submission, même partage SMB, juste avec des câbles plus longs — apparaît sous forme de modes d'échec silencieux : sessions qui restent connectées sans jamais transférer une frame, submissions de rendu qui pendent à 99 pour cent parce que le push final d'asset vers un nœud distant fait timeout, license check-outs qui réussissent localement et échouent à distance sans raison évidente.
Cet article décrit l'architecture que nous opérons pour les déploiements de render farm cross-country — la topologie WireGuard hub-and-spoke, le contrôle de congestion TCP BBR, la discipline de MSS clamping, une couche de cache SMB3 partagée, et une surface de pare-feu durcie. Les composants sont communs, les choix de configuration ne sont pas toujours évidents, et les leçons apprises nous ont surtout coûté du temps de debugging avant de coûter de l'argent à qui que ce soit. Le public visé est les architectes d'infrastructure et les ingénieurs DevOps qui dimensionnent un build similaire, plus les décideurs IT qui veulent savoir ce dans quoi leur équipe s'engage. Pour une procédure opérationnelle pas à pas sur le même stack, notre operational deployment guide couvre la séquence de rollout jour par jour. Pour une vue d'ensemble, la page cross-country render farm overview couvre le business case.
Topologie WireGuard hub-and-spoke

Tunnel chiffré reliant deux sites distants
La couche transport du cluster est WireGuard. Nous l'utilisons à la fois pour les connexions client (postes de travail des artistes vers la ferme) et pour la liaison site-à-site entre le datacenter principal et le site secondaire. La topologie est hub-and-spoke : un serveur WireGuard tourne au gateway du datacenter principal, chaque peer client se connecte à ce hub, et le site secondaire se connecte comme un autre peer avec un sous-réseau routé derrière.
L'attrait de WireGuard pour ce type de build est surtout mécanique. Le protocole utilise une cryptographie moderne fixe (Curve25519 pour l'échange de clés, ChaCha20-Poly1305 pour le plan de données, BLAKE2s pour le hachage), tourne dans le kernel Linux plutôt qu'en userspace, et se configure avec un fichier clé-et-AllowedIPs qui tient sur un écran. Comparé à OpenVPN, la surface de configuration est environ un ordre de grandeur plus petite, le débit sur un nœud Xeon typique est plusieurs fois supérieur au même coût CPU, et le codebase est assez petit pour que l'audit devienne traitable. Comparé à IPsec, il n'y a pas de phase de négociation IKE qui puisse échouer de manière intéressante, pas de danse d'identité de peer au rekey, et pas de daemon userspace à crasher. Nous avons opéré les trois sur des déploiements passés ; les configurations WireGuard sont celles qui restent en place sans intervention.
La disposition hub-and-spoke signifie que chaque flux site-à-site transite par le gateway du datacenter principal. Pour un déploiement cross-country à deux sites c'est le bon tradeoff : il concentre la surface d'attaque IP publique sur une box, applique un seul jeu de règles de routage et de pare-feu à un point d'étranglement, et rend le monitoring simple parce que chaque handshake et chaque compteur de flux sont visibles au hub. Un full mesh ferait économiser un hop sur le trafic site-à-site mais multiplierait le travail de configuration et la surface d'attaque publique au carré du nombre de sites. Pour deux ou trois sites, hub-and-spoke gagne sur la simplicité opérationnelle.
Le hub écoute sur le port UDP 51820 (défaut), et c'est le seul port que l'interface publique accepte. Il n'y a pas de fallback TCP. UDP-only est délibéré — le comportement de congestion de WireGuard est construit autour de datagrammes UDP, et un tunnel TCP-sur-TCP dégrade de manière fiable le débit longue distance. Sur les réseaux qui bloquent UDP entièrement, nous traitons cela comme une contrainte côté client et contournons à une autre couche.
Chaque peer client est configuré avec une seule entrée AllowedIPs couvrant le sous-réseau interne du cluster. Le peer site-à-site a un AllowedIPs couvrant le sous-réseau LAN distant pour que le kernel sache quels paquets encapsuler. PersistentKeepalive est réglé à 25 secondes sur chaque peer derrière NAT, ce qui maintient vivante l'entrée UDP conntrack entre handshakes. Nous l'avons omis exactement une fois et avons passé les deux jours suivants à débugger « les connexions tombent toutes les 90 secondes sur le site secondaire » ; sur le troisième site, PersistentKeepalive était la première ligne du fichier de config.
Contrôle de congestion TCP BBR
Une fois le tunnel WireGuard monté, la couche suivante est le comportement TCP. Linux livre CUBIC comme algorithme de contrôle de congestion par défaut. CUBIC fait varier sa fenêtre de congestion sur une courbe cubique en fonction du temps depuis le dernier événement de perte, ce qui fonctionne sur des liens où la perte de paquet est un signal fiable de congestion. Le piège est dans le mot « fiable ». Sur les routes ISP longue distance, la perte de paquet n'est souvent pas du tout de la congestion — c'est un débordement de queue sur un routeur intermédiaire, un lien sans fil qui retransmet de manière invisible à TCP, un rate-limiter mal configuré, ou un transitoire de routage. CUBIC traite tout cela comme de la congestion et effondre la fenêtre même quand le bottleneck a encore beaucoup de capacité.
BBR (Bottleneck Bandwidth and Round-trip propagation time) est l'alternative que nous utilisons sur les liens cross-country. BBR ignore la perte de paquet comme signal primaire de congestion et mesure à la place directement la bande passante du bottleneck et le RTT minimum du chemin. Il rythme ensuite l'émetteur au débit du bottleneck, avec une fenêtre dimensionnée pour garder exactement un produit bande-passante × délai en vol. Sur un long fat network — large bande passante, RTT élevé, pertes aléatoires modestes — BBR garde le pipe plein là où CUBIC diviserait sa fenêtre par deux pour des pertes non congestives.
L'effet pratique sur une render farm est mesurable. Les transferts d'assets via un tunnel cross-country, sur le même matériel, passent d'un débit en dents de scie avec des stalls fréquents sous CUBIC à une courbe de débit plus lisse proche de la capacité réelle du chemin sous BBR. Les chiffres dépendent de la route ISP et de l'heure de la journée, mais passer le côté émetteur du cluster à BBR a produit de manière constante un débit en régime établi supérieur et des tail latencies plus courtes sur les routes que nous opérons.
Nous utilisons l'implémentation BBR qui est dans le kernel Linux mainline depuis la version 4.9, activée par un sysctl d'une ligne : net.core.default_qdisc=fq plus net.ipv4.tcp_congestion_control=bbr. Les deux lignes vont dans /etc/sysctl.d/99-bbr.conf et survivent au reboot. Le BBR du kernel mainline est la version que nous opérons en production depuis des années. Des branches de recherche plus récentes de l'algorithme existent mais introduisent des changements de comportement que nous n'avons pas eu le temps de valider sur nos chemins ISP spécifiques ; le chemin d'upgrade est un point de roadmap séparé.
BBR est réglé côté émetteur de tout grand flux — la box cache et le render manager pour les transferts d'assets, le côté récepteur pour tout flux en sens inverse comme les license callbacks et le log shipping. BBR à une extrémité suffit pour voir l'essentiel du bénéfice ; BBR aux deux extrémités aide un peu plus sur les flux bidirectionnels.
TCP MSS clamping
De tous les problèmes réseau qui apparaissent après le montage du tunnel WireGuard, celui qui nous a coûté le plus de temps de debugging : la MTU. Le symptôme est constant et déroutant : les petits paquets passent proprement (ping fonctionne à taille par défaut, SSH echo les caractères, le handshake WireGuard termine), mais les gros paquets disparaissent dans le tunnel et n'en sortent jamais. Les handshakes TLS pendent au milieu. Les sessions SMB se connectent et échouent au premier gros read. Les sessions RDP s'établissent, affichent l'écran de login, puis se figent dès que l'utilisateur tape quelque chose. Les serveurs de licences checkout pour de petits tokens et timeout pour les gros.
La cause est l'overhead d'encapsulation du tunnel WireGuard qui réduit la MTU effective sous la MTU du chemin que les endpoints négocient en fonction de leurs interfaces LAN. WireGuard ajoute 60 octets d'overhead (20 IPv4 + 8 UDP + 32 WireGuard) à chaque paquet. Une charge utile de 1500 octets côté LAN devient un paquet de 1560 octets côté public, fragmenté ou rejeté selon le chemin. Path MTU Discovery (PMTUD) est censé corriger cela en renvoyant des ICMP « Fragmentation Needed » à l'émetteur, mais PMTUD casse sur l'internet moderne de manière routinière — l'ICMP est souvent filtré upstream de l'émetteur, le signal « utiliser des paquets plus petits » n'arrive jamais, l'émetteur continue d'émettre des paquets de 1500 octets, et le tunnel les drop silencieusement.
La solution est le TCP MSS (Maximum Segment Size) clamping. Nous configurons l'interface WireGuard côté routeur pour réécrire l'option MSS dans chaque TCP SYN qui traverse le tunnel, en la plafonnant à la MTU effective du tunnel moins l'overhead TCP/IP. Avec une MTU de tunnel de 1420 octets (un choix sûr qui survit à la plupart des variations upstream), le MSS clamp est 1380. Toute connexion TCP qui démarre après la mise en place de la règle négociera un MSS de 1380 octets, l'émetteur émettra des paquets de 1420 octets qui passent proprement, et les drops silencieux s'arrêtent.
Le clamp va sur la chaîne FORWARD de l'hôte WireGuard en mode routeur, sur l'interface wg0, appliqué aux paquets de handshake TCP. L'idiome iptables est iptables -t mangle -A FORWARD -o wg0 -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu (ou --set-mss 1380 pour une valeur fixe). nftables a l'équivalent. La règle doit s'appliquer dans les deux sens si les deux côtés initient des connexions TCP, ce qui sur une render farm est le cas commun.
Il n'y a aucun moyen de sentir que le MSS clamp manque tant que quelque chose de gros n'a pas échoué — les petits workloads testent proprement. Le clamp est une de ces configurations qui ne coûtent rien quand correctement appliquées et produisent des heures de debugging confus quand omises. Nous l'avons mis dans la checklist de déploiement standard après qu'un ticket support à 6 h sur « les transferts SMB pendent à des tailles aléatoires » s'est résolu à 8 h avec une règle iptables d'une ligne.
Conception du cache SMB3 partagé

Cache partagé servant les assets localement aux workers de rendu
Les workloads de rendu sont gourmands en assets et dominés par la lecture. Une scène typique va de quelques centaines de mégaoctets à plusieurs dizaines de gigaoctets — géométrie, textures, simulation caches et fichiers projet de la DCC de rendu. À travers un cluster de 20 nœuds, la même scène doit être lisible par chaque worker qui prend une frame. L'approche naïve est de copier la scène sur chaque nœud avant que le rendu ne démarre. Avec une scène de 10 Go et 20 nœuds, cela déplace 200 Go sur le réseau pour un working set de 10 Go. Multipliez par des dizaines de scènes par jour par studio et le coût de duplication domine le build.
L'architecture que nous utilisons à la place est une seule couche de cache partagée par site, exposée aux workers de rendu via SMB3. Le cache est une box Ubuntu 22.04 LTS avec un seul SSD (classe NVMe), formaté ext4, avec le répertoire de cache exposé par Samba via SMB3. Chaque worker de rendu monte le partage SMB au boot via cifs-utils et lit les fichiers d'asset depuis le cache comme s'ils étaient locaux. Le premier worker qui a besoin d'un asset donné déclenche un pull depuis l'asset store cloud upstream vers le cache ; les workers suivants et les frames suivantes lisent depuis le cache LAN à la vitesse du port switch. Par site, la box cache est à un saut switch de chaque worker ; l'asset atteint le cluster une fois et sert vingt workers.
Quelques choix de conception méritent un déballage. Le cache est un seul SSD, pas un array RAID, parce que le cache est par définition reconstructible depuis l'asset store cloud upstream. Si le SSD lâche, le pire cas est un délai pendant que la prochaine requête d'asset pull depuis le cloud, plus un rebuild de tout rendu in-flight qui dépendait d'un fichier intermédiaire non-mis-en-cache. Nous atténuons le risque « rendu in-flight » en rsyncant les outputs de rendu finis depuis le cache vers un NAS à la fin de chaque job, donc une panne SSD ne perd aucun deliverable déjà livré. Sauter le RAID économise le coût matériel, la complexité du contrôleur et l'overhead d'amplification d'écriture que certains niveaux RAID imposent aux SSD.
Le système de fichiers est ext4 plutôt que ZFS ou btrfs. Nous avons utilisé ZFS et btrfs dans des builds passés, et les feature sets qu'ils apportent (snapshots, checksumming, compression) sont de réels bénéfices dans certains workflows. Pour un cache de rendu, le pattern de lecture est surtout séquentiel et borné par la bande passante plutôt que transactionnel, et le contenu du cache est par conception jetable. Ext4 garde la pile de stockage simple et retire une classe de modes d'échec du jeu de postmortems d'incidents. Les opérateurs qui opèrent déjà ZFS à grande échelle peuvent absolument l'utiliser ici, mais pour un déploiement où la simplicité de la couche cache prime sur les gains de feature individuels, ext4 est le choix.
La stratégie de pre-warm compte. Avant qu'un job piloté par deadline ne démarre, l'artiste ou le TD pipeline pousse les assets de la scène dans le cache via un outil de pre-staging. La première frame qui atterrit sur un worker lit alors depuis un cache chaud plutôt que d'attendre un cold pull. L'étape pre-warm est optionnelle pour les jobs qui tournent la nuit (le cold pull va bien) et importante pour les jobs qui doivent finir dans une fenêtre contrainte.
Le partage de cache cross-site fonctionne via le tunnel WireGuard site-à-site. Le site secondaire a sa propre box cache et ses propres workers, mais sa box cache peut aussi atteindre le cache du site primaire via le tunnel pour tout asset qui est chaud là-bas et pas encore localement. En pratique nous configurons le cache secondaire pour se rabattre sur le cache primaire pour les misses avant d'aller au cloud upstream — ce qui garde le trafic inter-site sur le tunnel chiffré et évite les frais d'egress cloud pour des assets qui vivent déjà dans la ferme. C'est un des bénéfices pratiques d'un MSS clamp correct : les gros transferts d'assets entre sites se déplacent à un débit qui sature le tunnel plutôt que de staller au plafond des petits paquets.
Services internes : DNS et NTP
Un cluster doit connaître ses propres hostnames. Le choix naïf est de mettre chaque hôte dans /etc/hosts sur chaque nœud, ce qui marche à deux nœuds et commence à échouer à vingt. Le bon choix est un DNS interne, et nous opérons dnsmasq sur la même box gateway qui fait tourner WireGuard. Le cluster vit dans une zone .lan — cache.lan, rn-a01.lan à rn-a20.lan, mgr.lan, nas.lan. Chaque nom résout sur l'IP interne correspondante dans le sous-réseau du cluster, et le /etc/resolv.conf de chaque worker pointe sur le serveur dnsmasq.
Le bénéfice est que toute réassignation d'IP, swap d'hôte ou changement de topologie demande de modifier un fichier de configuration (le fichier hosts de dnsmasq) plutôt que toucher à chaque nœud. Le bénéfice s'étend au tunnel site-à-site : un worker sur le site secondaire peut résoudre cache.lan vers le cache secondaire via son dnsmasq local et résoudre mgr.lan vers le render manager du site primaire via du DNS forwarding à travers le tunnel. Nous avons, par le passé, utilisé des littéraux IP dans les configurations de render manager et l'avons regretté chaque fois qu'un nœud bougeait.
Le piège dnsmasq qui nous a mordu — et qui mord assez d'opérateurs pour mériter son propre paragraphe — est la ligne interface=. dnsmasq, par défaut, écoute sur chaque interface, ce qui semble bien jusqu'à ce qu'on réalise que la box gateway en a au moins trois : le WAN face au public, le LAN interne, et le tunnel WireGuard wg0. Si vous mettez interface=eth1 en pensant que vous restreignez dnsmasq au LAN, vous venez de rendre le site secondaire connecté WireGuard incapable de résoudre tout nom .lan, parce que wg0 n'est pas listé. La bonne ligne est interface=eth1,wg0 (ou l'équivalent pour vos noms d'interface), ou une ligne except-interface= qui ne nomme que le WAN. Nous avons vu cette mauvaise configuration produire le symptôme « le site distant peut pinger le cache par IP mais ne peut pas SMB-monter par hostname » plus d'une fois.
NTP est l'autre service interne. Nous opérons chrony sur le gateway comme serveur NTP, avec le gateway lui-même synchronisé aux pools NTP publics et chaque nœud synchronisé au gateway. La motivation est la corrélation des logs du render manager : si une frame échoue, l'entrée log du render manager et celle du worker doivent partager une timeline à la milliseconde près. Le clock drift sur un cluster de 20 nœuds, surtout quand les nœuds sont up depuis des semaines, devient une vraie source de confusion debugging « cette entrée log ne colle pas tout à fait ». chrony garde le drift sous quelques millisecondes et retire cette classe de confusion.
Pare-feu : ufw avec default-deny inbound
Le gateway est sur l'internet public, et sa posture de pare-feu est « default-deny inbound, default-allow outbound, default-allow forward pour le trafic tunnelé ». Sur Ubuntu 22.04 LTS, l'outil que nous utilisons est ufw — l'Uncomplicated Firewall. ufw est un frontend sur nftables (ou iptables sur les systèmes plus anciens) qui expose une petite surface de commande et refuse de faire des choses surprenantes. Pour une box gateway dont la config de pare-feu est la différence entre « sécurisée » et « compromise en quelques heures », une petite surface de commande est une feature.
La surface publique configurée est une règle : ufw allow 51820/udp comment 'wireguard'. Rien d'autre en inbound. SSH depuis le côté public est fermé ; nous administrons le gateway à travers le tunnel WireGuard depuis une IP opérateur connue. SMB, DNS, NTP et HTTPS (pour l'UI du render manager) sont tous sur des interfaces internes uniquement. Les réglages ufw default deny incoming et ufw default allow outgoing couvrent le reste de la surface.
La chaîne forward demande du soin. Le gateway agit comme routeur pour le trafic de cluster entre wg0 et le LAN interne, et la posture par défaut d'ufw est de refuser le forward. Nous mettons DEFAULT_FORWARD_POLICY="ACCEPT" dans /etc/default/ufw puis restreignons les règles forward à des paires source/destination spécifiques dans la chaîne FORWARD. La combinaison — default-deny incoming, default-deny forward au boot, puis des ACCEPT forward explicites entre sous-réseaux de cluster connus — donne une posture auditable qui ne route pas accidentellement du trafic entre sites qui ne devraient pas se parler.
Les pare-feux d'hôte par-nœud étendent cette couche Tier-1 gateway en une couche Tier-2 hôte. Chaque nœud de rendu fait tourner ufw localement avec des règles qui n'autorisent que le render manager et la box cache du cluster à initier des connexions. Un worker compromis ne peut pas pivoter vers un autre worker sans d'abord vaincre le pare-feu d'hôte, et le gateway logue chaque tentative de forward inattendue. Le modèle deux-tiers — gateway Tier 1, par-hôte Tier 2 — est le même que celui de tout cluster on-prem raisonnable ; ce qui change sur un déploiement cross-country est que la surface Tier 1 défend maintenant contre l'internet public. Le gateway est le périmètre ; les pare-feux par-hôte sont la défense en profondeur.
Diagramme d'architecture

Topologie de render farm hub-and-spoke, tunnel sécurisé unique vers internet
La description textuelle ci-dessus se mappe sur le diagramme ASCII suivant, le même que nous dessinons au tableau pendant les kick-offs de déploiement :
PUBLIC INTERNET
|
| UDP 51820 (only port open)
v
+------------------------+------------------------+
| MAIN DATACENTER |
| |
| +----------------+ +---------------+ |
| | Gateway |--LAN-->| Render Mgr | |
| | (ufw + wg0 + | | (mgr.lan) | |
| | dnsmasq + | +---------------+ |
| | chrony + BBR) | |
| +-------+--------+ +---------------+ |
| | -->| Cache | |
| | | | (cache.lan) | |
| v | | SSD ext4 SMB3| |
| +----------------+ | +-------+-------+ |
| | Worker Subnet |<----+ | |
| | rn-a01..a20 | v |
| | (Tier-2 ufw) | +---------------+ |
| +----------------+ | NAS | |
| | (archive) | |
| +---------------+ |
+------------------+------------------------------+
| WireGuard site-to-site
| (BBR + MSS clamp)
v
+------------------+------------------------------+
| SECONDARY SITE |
| |
| +----------------+ +-----------------+ |
| | Site Gateway |----->| Local Cache | |
| | (wg0 spoke) | | (falls back | |
| +-------+--------+ | to primary) | |
| | +--------+--------+ |
| v | |
| +----------------+ v |
| | Worker Subnet | (renders run |
| | rn-b01..b08 | locally; outputs |
| | (Tier-2 ufw) | ship over tunnel) |
| +----------------+ |
+-------------------------------------------------+
Le diagramme est volontairement générique — pas de paire de villes spécifique, pas d'ISP spécifique, pas de numérotation de sous-réseau spécifique. Chaque site que nous déployons suit la même forme ; les chiffres varient.
Caractéristiques de performance
Les chiffres de débit dépendent de la route ISP et de l'heure, mais la forme des performances est constante sur les déploiements que nous avons opérés. Sur un tunnel entre deux sites de la même métropole (RTT sous 10 ms), les gros transferts se déplacent près du débit de ligne sur le lien bottleneck, et un worker de rendu lisant depuis le cache est indistinguable d'un worker lisant depuis un disque local. Sur un tunnel entre sites de pays différents (50–150 ms RTT selon la route), les gros transferts s'installent sur un débit régulier rythmé par BBR proche de la bande passante du bottleneck, avec le MSS clamp maintenant la taille par segment alignée sur la MTU du tunnel.
La lecture depuis le cache LAN local est là où l'architecture gagne sa croûte. Un worker de rendu lisant un texture pack de 4 Go depuis cache.lan via SMB3 sur un LAN switché gigabit termine en gros dans le temps que le port switch met à pousser les octets — quelques dizaines de secondes plutôt que les délais en plusieurs minutes qu'un cold pull depuis un stockage cloud cross-country prendrait. Pour un job qui touche le même texture pack sur deux cents frames, la cache hit ratio s'approche de 1,0 après la première lecture chaude, et le tunnel cross-country n'est utilisé que pour le pre-warm initial, la sync cross-site des outputs du site secondaire et la télémétrie en régime établi.
Pour les frames 4K et 8K spécifiquement, la valeur de l'architecture monte avec la taille de frame. Une séquence EXR 8K avec plusieurs AOV peut pousser les outputs de frames individuels dans les centaines de mégaoctets, et 200 d'entre eux font une écriture de plusieurs dizaines de gigaoctets par scène. Garder cette écriture en local-LAN et n'expédier que l'output compressé final via le tunnel est la différence entre « finit pendant la nuit » et « finit quand l'upload se termine, demain ».
Foire aux questions
Q: Pourquoi WireGuard et pas OpenVPN ? A: La surface de configuration de WireGuard est plus petite, son débit côté data plane constamment plus élevé sur le même matériel, son implémentation kernel retire un mode d'échec userspace, et sa posture à chiffrement fixe retire une classe de bugs de négociation. OpenVPN est un outil solide avec vingt ans d'historique opérationnel ; nous utilisons WireGuard parce que les propriétés opérationnelles pour un tunnel de cluster longue durée sont meilleures sur les métriques qui nous importent. Sur les routes où l'UDP de WireGuard est bloqué entièrement, OpenVPN sur TCP 443 est un fallback légitime — mais TCP-sur-TCP introduit ses propres pathologies, et nous traitons cela comme une contrainte côté client.
Q: Comment BBR aide-t-il sur des routes ISP bruyantes ? A: BBR utilise la bande passante bottleneck et le RTT comme signal de congestion plutôt que la perte de paquet. Sur les routes où la perte est dominée par le débordement de buffer sur des routeurs intermédiaires, les retransmissions sans fil ou les événements transitoires de routage — c'est-à-dire la plupart des routes ISP publiques — BBR maintient la cadence d'envoi au débit réel du chemin au lieu de diviser la fenêtre par deux à répétition pour des pertes non congestives. L'effet est un débit en régime établi supérieur, une tail latency plus courte sur les gros transferts et moins d'incidents « le transfert s'est arrêté trente secondes puis a repris » sur les longs flux.
Q: Qu'est-ce que le MSS clamping et pourquoi en ai-je besoin ? A: Le MSS clamping réécrit l'option Maximum Segment Size dans les paquets TCP SYN pour que la taille de segment négociée passe proprement dans un tunnel à MTU effective réduite. Sans, les endpoints négocient une taille de segment basée sur leurs interfaces LAN (typiquement MTU 1500, MSS 1460), le tunnel WireGuard ne peut pas porter ces paquets à pleine taille, Path MTU Discovery échoue parce qu'ICMP est filtré quelque part upstream, et les gros paquets disparaissent silencieusement. Le symptôme est « les petits paquets passent, les gros non » — les pings passent, les handshakes TLS pendent, les transferts SMB stallent au milieu d'un fichier. La solution est une règle iptables ou nftables d'une ligne sur l'interface WireGuard côté routeur.
Q: Puis-je déployer cette architecture moi-même, ou ai-je besoin d'un vendeur de render farm ?
A: L'architecture est entièrement construite à partir de composants open source — WireGuard, l'implémentation BBR de Linux, iptables/nftables, Samba SMB3, dnsmasq, chrony, ufw, ext4. Il n'y a pas de composant SRF-only. Une équipe avec des compétences d'ingénieur infrastructure peut déployer le même stack elle-même, et les choix de configuration dans cet article ne sont pas des secrets ; ce sont les choix que nous avons faits parce qu'ils fonctionnaient. Ce qu'un vendeur apporte est l'expérience opérationnelle — les pièges comme la ligne interface= de dnsmasq, l'histoire de la découverte du MSS clamp, le bon dimensionnement du SSD de cache, l'outillage de pre-warm — roulé en un playbook de déploiement qui ne demande pas la redécouverte à chaque build. Que l'équipe absorbe cette courbe d'expérience ou achète pour la contourner est une question de budget et de timeline.
Q: Quelle est la cache hit ratio pour des workflows de rendu typiques ? A: Pour les workloads parallèles par frame où la même scène est rendue sur plusieurs frames (le pattern dominant en animation, VFX, archviz et visualisation produit), la cache hit ratio s'approche de 1,0 après le premier pull chaud de chaque asset. La pénalité de cold pull est payée une fois par asset par cache, et chaque worker suivant sur le même site lit depuis le cache chaud à vitesse LAN. Pour les workloads qui touchent un asset set différent par frame (rare, mais cela arrive dans certains workflows procéduraux), la hit ratio est plus basse et le cache agit plus comme un buffer de transit qu'un store long-terme. L'étape pre-warm avant des jobs deadline rend effectivement la hit ratio à 1,0 pour le workload planifié.
Q: Comment cette architecture monte-t-elle au-delà de 20 nœuds ? A: La topologie WireGuard hub-and-spoke monte linéairement avec le nombre de peers — le coût CPU du hub est crypto par peer et routage par paquet, et un gateway Xeon moderne peut gérer des centaines de peers avant de devenir le bottleneck. La couche cache monte soit en faisant croître la box cache unique (plus de capacité SSD, NIC plus rapide), soit en shardant à travers plusieurs boxes avec une stratégie de mount consciente du workload. Pour des builds au-delà de 50 nœuds par site, nous ajoutons typiquement une seconde box cache et splitons les workers entre elles ; au-delà de 100 nœuds par site, la couche cache devient un design read-replica distribué, et c'est un autre article. Le tunnel cross-country lui-même n'a pas besoin de changement architectural quand le cluster grandit — le BBR pacing et le MSS clamp continuent de faire leur travail à n'importe quel débit agrégé tant que le lien ISP sous-jacent a la capacité.
Pour plus de détails pratiques sur la séquence de déploiement avec laquelle nous montons cette architecture, voyez notre operational deployment guide. Pour la posture de sécurité posée sur ce design réseau, notre article network segmentation security couvre plus profondément le modèle pare-feu Tier-1 et Tier-2. Et pour les cas limites éprouvés sur le terrain que nous n'avons pas toujours bien réussis du premier coup, le writeup deployment lessons learned couvre les modes d'échec spécifiques qui ont façonné cette architecture.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



