20ノード専用GPU render farmを国境をまたいで展開する方法(2026年)
概要
はじめに
クリエイティブチームが複数の国にまたがる専用render farmを求める場合、通常はSaaS型render farmでは解決できない制約が背景にあります。顧客のマスターサービス契約や下流クライアントの契約上、第三者がシーンファイルや認証情報を保持することを禁じているスタジオ、ある国のアーティストが別の国のノードを操作する分散チーム、あるいはフレーム単位の従量制が経済的に合わない長期のプロダクションハウスがその典型です。
私たちの経験では、難しいのは「GPUをもっとレンタルする」ことではありません。正しいピースを接続することです。顧客所有のクラウドストレージ、ワークロードに合わせたプライベートGPUフリート、ジッターに耐える暗号化された越境トランスポート、そして重い3Dビューポートで崩壊しないリモートデスクトップレイヤーです。どれか一つが間違っていると、クラスターは動作しているように見えながら、アーティストが気づいた瞬間からエンゲージメントは静かに劣化していきます。
私たちはSuper Renders Farm——相当規模のCPU+GPUフリートを持つクラウドrender farm——を運営しており、マネージドサービスに合わないワークフローを持つチームのために専用GPUクラスターも構築しています。本記事はそれらの実際のデプロイメントから得たフィールドガイドです。単一の専用施設から、国境をまたいで分散したクリエイティブチームにサービスを提供する20ノード専用GPU render farmをどのようにアーキテクチャするか——私たちが下した選択、撤回した選択、そして今デフォルトとして適用している教訓を正直に解説します。専用インフラとマネージドrender farmレンタルを比較検討している方には、専用パスがアーキテクチャ上の複雑さに見合うかどうかを判断するための指針になるでしょう。
専用 vs SaaS の判断基準
ほとんどのレンダリングワークロードに専用クラスターは必要ありません。マネージドクラウドrender farmは、シーンを受け取り、フレームをスケジュールし、分単位で課金します。所有するインフラも、管理するファイアウォールも、顧客側に配置するオペレーションチームも必要ありません。プロジェクト単位の作業——単発の短編、30秒のCM、静止画のバッチ——であれば、あらゆる重要な指標でこのモデルが勝ります。
専用クラスターがその複雑さを正当化するのは、以下のうち一つ以上が当てはまる場合だけです。
- IP管理が好みではなく契約上の要件である場合。 顧客のマスターサービス契約やエンドクライアントの契約が、第三者によるシーンファイルやレンダリング認証情報の保持を禁じている場合。基礎となるコンピュートが同一であっても、シーンのアップロードを仲介するSaaSパイプラインはこの制約に違反します。
- エンゲージメントが数日ではなく数ヶ月にわたる場合。 固定形状の作業——長期シリーズ、複数四半期にわたるarchvizパイプライン、継続的なバーチャルプロダクション——は、初期のアーキテクチャコストを回収します。フレーム単位の従量制は期間に比例してコストが増大し、一定の期間を過ぎると競争力を失います。
- ワークフローがマネージドパイプラインでホストできないほどカスタムである場合。 カスタムDCCプラグインスタック、社内レンダーマネージャー、共有キャッシュに事前ベイクするシミュレーション多用のパイプライン、プロプライエタリなツールチェーンは、いずれも顧客が直接設定できる専用ノードを必要とします。
- BYOCが絶対要件である場合。 顧客のプロジェクトアセットが顧客のアカウント下のクラウドファイルストリーミングプラットフォームに存在する場合、クラスターはインフラプロバイダーとしてではなく、顧客として認証する必要があります。これが以下で詳述する「モデルB」パターンです。
- ネットワークセグメンテーションの要件がテナント単位のVLANを超える場合。 一部のワークフローでは、クラスターがプロバイダーの広域ネットワークから見えないことが求められます——論理的な隔離だけでなく、ルーティング上の隔離も含めて。
これらの基準がいずれも当てはまらない場合、マネージドrender farmが正しい選択です。二つ以上当てはまる場合、会話は専用に向かいます。残る問いは地理的なものです。作業を推進するアーティストが施設の近くにいるのか、それとも国境を越えるパブリックISPバックボーンを介してクラスターがサービスを提供する必要があるのか。
アーキテクチャ概要
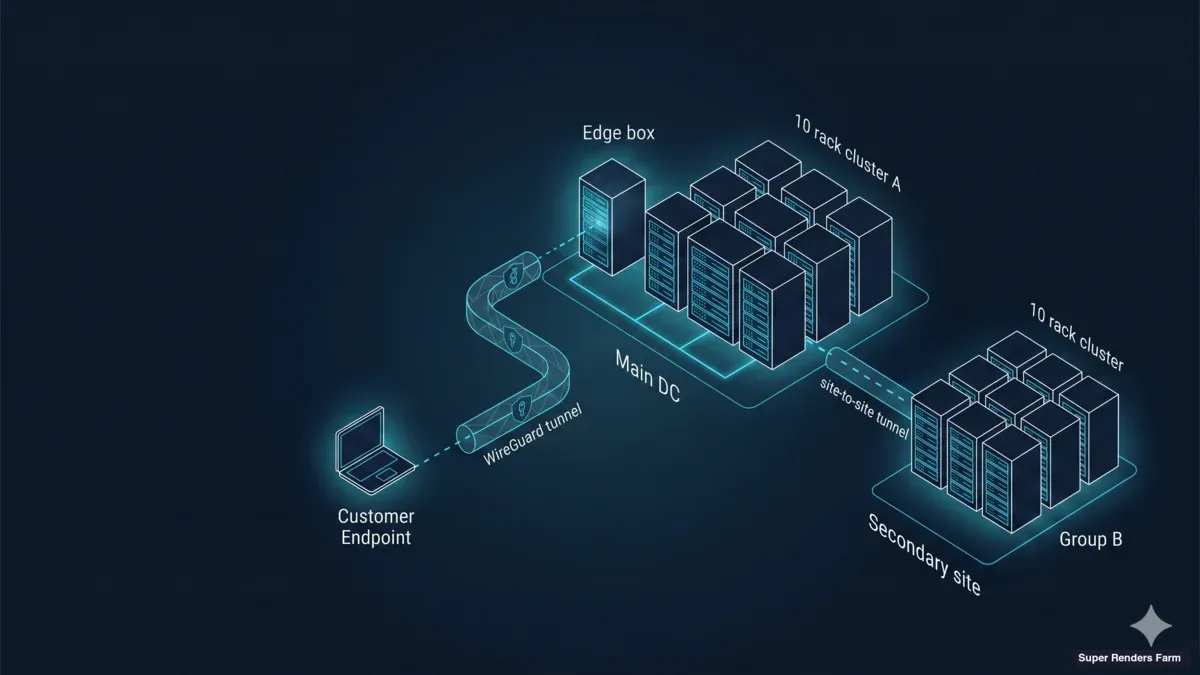
越境専用クラスターに私たちがデプロイするアーキテクチャには、トランスポートプレーン、コンピュートプレーン、ストレージアクセラレーションプレーンという3つのプレーンがあります。各プレーンには単一の障害モードがあり、私たちの経験では、それが壊れたときにオペレーション上の痛みの大部分を生み出します。
[ リモートアーティスト — 複数国に分散 ]
│
│ WireGuard ハブアンドスポーク
│ (UDP 51820, エンドツーエンド暗号化,
│ BBR + MSS クランプ済みトランスポート)
▼
┌─────────────────────────────────────────────────────┐
│ Super Renders Farm — 専用クラスター施設 │
│ │
│ ┌─────────────────────────────────────────────┐ │
│ │ エッジ + キャッシュボックス(Ubuntu単体ホスト) │ │
│ │ • WireGuard ハブ(NAT/MASQUERADE) │ │
│ │ • Samba SMB3 キャッシュ(SSD単体, ext4) │ │
│ │ • dnsmasq(.lan ゾーン) │ │
│ │ • chrony(NTP) │ │
│ │ • ufw + BBR + TCP MSS クランプ │ │
│ └────────────────────┬────────────────────────┘ │
│ │ LAN │
│ ┌────────────────────▼────────────────────────┐ │
│ │ 20 × RTX 5090 レンダーノード │ │
│ │ (Windows 11 Pro, Sunshine, クラウドファイル │ │
│ │ ストリームクライアント, キャッシュマウント — │ │
│ │ フリート全体で統一イメージ) │ │
│ └─────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
│
▼
[ 顧客のクラウドファイルストリーミングプラットフォーム —
各ノードで顧客がサインイン。Super Renders Farmは
認証情報を保持しない(モデルB)]
トランスポートプレーンはWireGuardで、ハブアンドスポークパターンです。すべてのアーティストのワークステーションは、暗号化されたUDPトンネルを通じてクラスター施設のハブに接続します。アーティストがいる国に関わらず、アーティストとクラスター間のすべてのトラフィックは同じトンネルトポロジーを経由します。コンピュートプレーンは20台のWindows 11 Proノードで、それぞれが32 GBのVRAMを持つ単一のNVIDIA RTX 5090を駆動し、1施設内の統一プールとして展開されます。ストレージアクセラレーションプレーンは、施設内の単一のエッジ&キャッシュボックスです。ext4上の単一SSDをバックエンドとするSamba SMB3共有をホストし、クラスターが依存するネットワークサービス(DNS、NTP、ファイアウォール)も担います。
重要な設計上の決定:エッジボックスとキャッシュボックスは同一のマシンです。以前のバージョンでは、エッジゲートウェイを別のアプライアンスに、キャッシュをNASに置いていましたが、コールドプル時にレースコンディションが発生し、パッチ適用の対象が2つになる問題がありました。Ubuntu 22.04 LTSの単一ホストに統合することで両方の問題が解決しました。このボックスは重要なリソースになりますが、顧客のプロジェクトデータは依然としてクラウドファイルストリーミングプラットフォームに存在するため、ローカル障害後にはアップストリームからキャッシュを再ウォームアップできます。
20ノードGPUクラスターのセットアップ
本記事で説明するデプロイメントのデフォルトサイジングは、1施設内の単一の統一プールとして展開されたRTX 5090ノード20台です。この規模は、10〜20名のアーティスト規模のクリエイティブチームに一貫して適合します。このレンジがIP敏感なワークフローで専用クラスターが収支の合う帯域です。
各ノードのハードウェアは同一の形状です。32 GBのVRAMを持つRTX 5090単体、最新のマルチコアCPU、64 GBまたは128 GBのシステムRAM、OSとスクラッチ専用にサイジングされたNVMeローカルディスク。永続的なプロジェクトデータは共有キャッシュまたはアップストリームのクラウドファイルストリーミングプラットフォームに存在し、ノード自体には置きません。
各ノードのOSはWindows 11 Proで、クリーンなイメージから展開されます。ノードイメージにDCCプラグインスタックをあらかじめ読み込まないことを意図的に選択しています。顧客が自分のDCCツール——Cinema 4D、Redshift、Houdini、After Effects、Blender、その他——のインストールを主導することで、ノードイメージは最小限で再現可能な状態を維持できます。エンゲージメントが終了したら、同じクリーンベースラインからワイプして再イメージします。
ノードごとに32 GBのVRAMを選択したのは意図的です。現代のGPUレンダラー——Redshift、Octane、Arnold GPU、Cycles——は、24 GBカードに収まらない大きなテクスチャ付きシーンを読み込むことが増えています。32 GBのRTX 5090は、プロダクションレンダラーにとって現在のスイートスポットです。ほとんどのarchviz、モーションデザイン、アニメーション作業をシステムRAMへのページングなしに処理できます。混在するGPUプールが静かに遅くなる原因がそこにあります。
20台のノードは同一設定——同じイメージ、同じDCCインストールセット、同じキャッシュマウント、同じWireGuardルート——で、顧客のレンダーマネージャーには単一プールとして表示されます。Deadline、Royal Render、または顧客独自のスケジューラーは、グループ単位のルーティングや手動のリバランスなしに、フリート全体を単一リソースとして扱います。フレームは空いているノードに割り当てられ、顧客のレンダーマネージャーがジョブキューレイヤーで負荷分散を処理します。
フリートはレイヤー3でルーティング可能です——顧客は自分のレンダーマネージャーをインストールし、各ノードをリモートデスクトップで操作するのではなく、リモートワークステーションから送信します。これは人々が予想する以上に重要で、アーティストが格闘するクラスターと、アーティストが存在を忘れるクラスターの違いです。
顧客所有の認証情報(モデルB)
IP敏感なワークフローで専用クラスターが正しい答えになることが最も多い単一のアーキテクチャ上の決定が、私たちがモデルBと呼ぶものです:顧客所有の認証情報。モデルA——私たち自身のSaaSサービスを含むマネージドrender farmのデフォルト——では、インフラプロバイダーがレンダリングパイプラインの認証情報を保持します。顧客はシーンファイルをアップロードし、プロバイダーのパイプラインがレンダリングを仲介します。これは膨大な数のワークロードで機能し、ほぼすべての商用クラウドrender farmの背後にあるモデルです。
モデルBでは、インフラプロバイダーはハードウェア、OS、ネットワーク、キャッシュレイヤーを提供しますが、クラウドファイルストリーミングプラットフォームまたはプロジェクトのソースデータに対する顧客の認証情報を決して保持しません。顧客は自分のワークステーションに座っているのと全く同じように、各ノードのクラウドプラットフォームにサインインします。プロジェクトファイルは顧客のクラウドからストリームされます。レンダリング出力は顧客のクラウドに書き戻されます。プロバイダーの役割はハードウェアとパイプラインレイヤーに限定されます。
これが重要な理由は3つあります。
- 契約上の理由: 顧客の下流クライアントが認証情報やソースファイルの保存先を制限するNDAまたはマスターサービス契約を持っている場合、モデルBはプロバイダーをその制限のスコープ外に置きます。顧客は、そのために設計されていない契約チェーンにレンダリングプロバイダーを交渉して組み込む必要がありません。
- 監査上の理由: 顧客がレンダリングパイプラインが第三者に認証情報を公開しないことをセキュリティ監査人に証明する必要がある場合、モデルBはクリーンな回答を提供します。プロバイダーはハードウェア、ネットワーク、オペレーションドキュメントを提示し、顧客は認証情報チェーンを提示します。
- エンゲージメント終了時の処理: プロバイダーが認証情報を保持していないため、エンゲージメント終了時のクリーンアップはシンプルです。顧客は自分のクラウドセッションを失効させ、プロバイダーはキャッシュをワイプし、ノードをクリーンベースラインから再イメージし、キャッシュとノードイメージが破棄されたことを書面で証明します。プロバイダーが認証情報を保持していなかったため、証明すべき認証情報のローテーションステップはありません。
モデルBは全員に向いているわけではありません。各ノードの認証情報ライフサイクルを顧客のオペレーションチームが担うことになります——シークレットが月次でローテートされる場合、20回の調整が必要です。このオペレーションの慣行が既に整っているチームはトレードオフを許容できます。そうでないチームはモデルAのマネージドレンダリングにとどまる傾向があります。
クラウドファイルストリーミングの統合
今回説明する構成では、顧客のプロジェクトアセットはクラウドファイルストリーミングプラットフォームに存在します——クラウドバックアップされたプロジェクトツリーを各ノードの仮想ファイルシステムとして公開するサービスです。アーティストがプロジェクトをマウントすると、ノードはオンデマンドでファイルを読み込み、プラットフォームはバッキングストレージ、バージョニング、クロスリージョンレプリケーションを処理します。
私たちは顧客が選択した汎用クラウドファイルストリーミングプラットフォームと統合します。プラットフォームは各ノードから顧客のアカウントを使ったサインインイベントを受け取り、ノード上で動作するプラットフォームのクライアントが既知のパスにプロジェクトツリーをマウントし、顧客のDCCアプリケーションはローカルワークステーション上と全く同じようにそのパスからファイルを開きます。クラウドプラットフォームはノードがレンダークラスターの一部であることを認識する必要はありません。
これが20ノードクラスターに接続されると変わるのはアクセスパターンです。単一のワークステーション上の単一アーティストは、作業しながら一度に一つのプロジェクトファイルをオンデマンドで引き出します。フレームレンジのために20台のレンダーノードが同時に同じシーンを開くと、同じアセットのクラウド読み込みが同期的なバーストになります。キャッシュなしでは、すべてのノードがすべてのテクスチャ、すべてのキャッシュ済みシミュレーション、すべての依存ファイルを並列に引き出します——これは国際的な帯域幅の無駄遣いであり、すべてのレンジの最初のフレームで遅延を引き起こします。
これが共有キャッシュが存在する理由です。次のセクションで詳しく説明しますが、クラウドファイルストリーミングとの統合がその必要性の根本です。クラウドからのアセット引き出しはキャッシュボックスを通じて一度だけ集約され、その後LANを介して20台すべてのノードに配布されます。クラウドプラットフォームは同じテクスチャへの20件の同時フェッチを見ることはありません——1件のフェッチと、その後のネットワーク内のウォームなSMBリードが見えるだけです。
もう一つの実践的な詳細は書き戻しです。レンダーフレームが完了すると、ノードはクラウドファイルストリーミングプラットフォームに出力を書き込みます——顧客のアカウントを通じて。リモートオフィスの顧客チームは、プロジェクトツリーにリアルタイムでフレームが現れるのを確認できます。手動アップロードのステップも、プロバイダーが仲介する転送もありません。クラウドプラットフォームがラウンドトリップを処理します。
共有キャッシュアーキテクチャ
共有キャッシュは、誤って設計するとクラスターの価値を静かに侵食する2〜3のアーキテクチャ上の選択の一つです。以前のデプロイメントでは失敗を経験しました。複数のビルドを経て定着したパターンは意図的に保守的なものです。
単一のエッジ&キャッシュボックスはUbuntu 22.04 LTSを実行し、ext4でフォーマットされた単一の8 TB SATA SSDを持ち、Samba SMB3でクラスターに公開されます。キャッシュマウントは固定パス(例:\\cache.lan\proj)で各レンダーノードに表示されます。ノードがクラウドファイルストリーミングクライアントを通じてプロジェクトファイルを開くと、ファイルはローカルキャッシュを通じてストリームされ、その後いずれのノードからの同じファイルへの読み込みもLAN上のSSDに直接ヒットします。
この段落には3つの意図的な選択が含まれています。
第一に、ノード単位のキャッシュではなく、単一キャッシュ。 以前のバージョンでは、ノード単位でキャッシュ素材を保存していました。20台の5090ノードでは、最大200 TBの冗長ストレージを管理し、何かが乖離したときに20個の別々のキャッシュ状態をデバッグする必要がありました。単一の共有キャッシュに統合することで、ストレージフットプリントが20分の1に削減され、キャッシュ状態はオペレーションチームが検査できる単一のアーティファクトになります。
第二に、XFS上のLUKSを使ったRAID 10ではなく、ext4上の単一SSD。 以前の計画では、XFS上のLUKS保存時暗号化を使ったRAID 10アレイにキャッシュを置くことになっていました。その計画は、私たちが実際にデプロイするハードウェア——SSD一台、ファイルシステム一つ、マウント一つ——に対して過剰設計でした。RAIDレイヤーを削除し、LUKSを削除し、ext4を使用しました。キャッシュはプロジェクトデータの信頼できる情報源ではないからです。顧客のクラウドが信頼できる情報源です。キャッシュドライブが故障しても、交換してアップストリームから再ウォームアップすればよく、クラウドレイヤーに冗長性があるのでキャッシュレイヤーに冗長性は不要です。(保存時暗号化はこの案件のスコープ外でしたが、下流クライアントが要求する場合は別途エンゲージメントとして提供可能です。)
第三に、最初のレンダー日前にキャッシュを事前ウォームアップする。 これは私たちが痛い経験から学んだ教訓です。D-Dayには、すべてのキャッシュミスがクラスター内で最もコストのかかる読み込みです——国際リンクを経由し、顧客のクラウドから引き出し、レンダラーが消費できるようになる前にローカルSSDに書き込みます。プロダクション開始の前日にプロジェクトのアセットツリーを構造的に走査する事前ウォームアップは、D-Dayの読み込みをコールドなクラウドプルからウォームなSMBリードに変換します。私たちは今、すべての専用クラスターエンゲージメントに事前ウォームアップウィンドウを計画に組み込んでいます。
施設内では、すべてのノードはローカルLAN上のSMB3を使って同じ固定パス(\\cache.lan\proj)にキャッシュをマウントします。施設内トラフィックはWireGuardトンネルを経由しないため、MSSクランプは適用されず、リンクはエンドツーエンドでギガビットイーサネット速度で動作します。キャッシュのマウントパスはすべてのノードで同一で、顧客のレンダーマネージャーの設定が簡素化されます——同じシーンファイルパスがプールのすべてのメンバーで同じように解決されます。
越境ネットワーク最適化
トランスポートレイヤーは、越境クラスターがシームレスに感じるか壊れているように感じるかの分岐点です。TCP/IPのデフォルト動作、IPフラグメンテーション、VPN越しのDNSは、SMBとリモートデスクトップを運ぶ長距離暗号化トンネルに対して微妙に誤っています。カーネルとネットワーク設定のチューニングはオプションではありません。それが機能するクラスターと、大きなパケットを謎めいた形でドロップするクラスターの違いです。
WireGuard、ハブアンドスポーク。 すべてのアーティストはワークステーションからWireGuardクライアントを通じてクラスター施設のハブに接続します。アーティストとクラスター間のすべてのトラフィックはエンドツーエンドで暗号化されます。私たちはプロトコルを混在させず、一つのVPN技術を使用します。IPSecを一つの役割に、別のVPNを別の役割に組み合わせると、セキュリティを向上させることなくオペレーション上の複雑さが増します。
TCP BBR。 Linuxのデフォルト輻輳制御(CUBIC)は低遅延・軽量パケットロスリンク向けに設計されています。暗号化されたトラフィックを運ぶ長距離パブリックISPリンクは非常に異なる外観を持ちます——適度な遅延、時折のジッター、非対称のロスパターン。BBRはCUBICよりも一貫してこれらのリンクで使用可能なスループットを生み出します。特にリンクが顧客の他のインターネットトラフィックと共有されている場合に顕著です。私たちはカーネルのストックBBR(BBR v1)を使用します。新しいBBRv3はこのビルドでは展開されませんでしたが、ストックバージョンは安定して動作しています。
TCP MSSクランプ。 これが「クラスターはほぼ機能するが大きなファイルで問題がある」というクレームの最も一般的な原因です。有効MTUを削減するトンネルを通じてトラフィックが経由するとき、大きなパケットはフラグメント化(低速)またはサイレントドロップ(さらに悪い)されます。小さなパケットとpingは正常に動作するため、問題の診断が難しくなります。修正は、TCP MSSをWireGuardルーター上でクランプして、TCPがトンネル内に収まるパケットサイズをネゴシエートするようにすることです。適用後、TLSハンドシェイク、RDPセッション、SMBの大ファイル読み込みが停止せずに動作するようになります。
VPNインターフェースを明示的にリストしたdnsmasq。 微妙な落とし穴:dnsmasqは、クライアントがプライベートな.lanアドレスを照会していても、WireGuardインターフェース(例:wg0)をその設定に明示的にリストしなければなりません。そうしないと、トンネル越しのDNSルックアップがタイムアウトしますが、pingはDNSを経由しないため正常に動作します。これは私たちが経験した最も混乱を招く診断セッションを生み出します。他のすべてのテストが正常に見えるからです。
chronyによるNTP。 時刻同期は些細に聞こえますが、レンダーマネージャー(Deadlineはジョブにタイムスタンプをつけます)、クラスター全体のログ相関、時刻コンポーネントを持つ認証トークンにとって重要です。chronyは長遅延リンクでの時計ドリフトを旧来のntpdよりうまく処理します。エッジボックスで実行し、各ノードがそれに同期するようにしています。
これらの選択の複合効果は、ほとんどのワークロードでLANのように感じられ、パブリックパスが異常に混雑しているときでも優雅に劣化するトンネルです。次のセクションでは、そのトンネル上で3D作業を実行することが実際にどのように見えるかを説明します。
Moonlight と Sunshine によるリモートデスクトップ
リモートデスクトップはアーティストが最も直接体験するレイヤーです。リモートデスクトップレイヤーが遅く感じたり、がくがくしたりすると、レンダラーがどれだけ速くても問題ありません——アーティストの手が遅くなり、エンゲージメントが劣化します。
私たちはリモートデスクトップにMoonlight(クライアント)とSunshine(各ノードのホスト)を使用しています。この組み合わせは、RTX 5090上のNVIDIAのNVENCハードウェアエンコーダーを使用してフレームバッファをリアルタイムにエンコードし、アーティストのワークステーションにストリームします。エンコードはノード内に既にあるGPU上で行われるため、レンダラーとの競合はなく、リモートデスクトップによって追加される遅延はネットワークラウンドトリップによって支配されます——エンコーディングステージではありません。
3Dビューポート作業では、従来のリモートデスクトップとは異なる方法でこれが重要になります。古いプロトコル——RDP、VNC、標準Microsoftリモートデスクトップ——はオフィスワークロード向けに設計されました。テキスト、ダイアログ、ゆっくり変化するウィンドウはうまく処理しますが、ターンテーブルプレビュー中のフルスクリーン3Dビューポートでは崩壊します。Moonlight + Sunshineはフレームバッファをビデオとして扱います。これが3D作業にとって正しいモデルです。
ノードをアーティストに引き渡す前に実行する品質ゲートテスト——非公式に「テスト8」と呼んでいます——があります。負荷をかけた状態で一定のビューポート操作シーケンスを実行し、リモートデスクトップ体験がベースラインを満たしていることを確認します。ノードがテストに失敗した場合、エンコードパイプラインをデバッグするか、問題が解決するまでノードをローテーションから外します。このテストはすべてのエンゲージメントの開始時と、ノードの再イメージ後に実行します。
ParsecはSunshineにホスト固有の問題がある場合の実行可能なフォールバックです。Sunshineを確実に設定できなかった場合に少数のノードをParsecで展開したことがあります。アーティストの体験は同様です。アカウントベースのクラウド調整モデルが、セルフホストのSunshineほどモデルBの認証情報処理に合致しないため、標準化していません。
初期計画では他のリモートデスクトップオプションも検討しましたが採用を見送りました——GPUエンコードなしの汎用リモートデスクトップツール、およびフルスクリーン3Dビューポートの品質ゲートを満たさなかったオープンソースの代替品です。重要な原則:GPUクラスターノードには、ハードウェアエンコードストリーミングが規模で成立する唯一のモデルです。
キャパシティプランニングと予約フロア
本ガイドの20ノード構成は、エンゲージメント期間中のSuper Renders Farmの広範なフリートからの予約済み専用スライスです。予約済みとは、ノードがマネージドサービスプールと共有されず、他のテナントとの同時スケジューリングもなく、フレーム単位の従量制にも適用されないことを意味します——顧客はスライスをフラットなオペレーションコストとして支払い、キックオフから解体まで、それらのノードを独占的に管理します。
スライスのサイジングを20ノードにするのは意図的な選択です。10ノード未満では、クラスターはマネージドrender farmに対してアーキテクチャ上の複雑さを正当化できません——SaaSパスがよりシンプルで経済的です。30を超えると、キャッシュレイヤーは再設計が必要になり(複数のキャッシュボックス、リージョナルキャッシュ)、オペレーションモデルも形が変わります。20は、単一のエッジ&キャッシュボックス、単一のWireGuardハブ、統一されたWindowsイメージがきれいに成立する帯域であり、10〜20名のアーティストのクリエイティブチームがクランチ中にフレームを流し続けながら、通常業務時にアイドル時間がなくて済む規模です。
Super Renders Farmはこの専用スライスを超える相当規模のフリートを運営しているため、エンゲージメントが必要とするときにスケールアップの余裕があります。同じ施設内への追加の予約済みノードの追加は、調達サイクルではなく設定変更です。複数ヶ月のエンゲージメントを実行している顧客は通常、キックオフ時にスライスサイズを固定し、元の計画に対する実際の需要に基づいて四半期の境界でスコープを見直します。
ネットワークセグメンテーション
このようなクラスターでネットワークセグメンテーションはオプションではありません。顧客はプロバイダーのインフラ上で動作していますが、顧客がプロバイダーの広域ネットワークを見ることができてはなりません——プロバイダーのNASも、プロバイダーのルーター管理インターフェースも、他のどのテナントも。同様に、プロバイダーの内部システムが顧客のワークロードに公開されてはなりません。
私たちは2層でセグメンテーションを実装します。
第1層——エッジファイアウォール。 エッジ&キャッシュボックスはデフォルト拒否インバウンドスタンスでufw(Uncomplicated Firewall)を実行します。パブリックインターネットに公開されるのはWireGuard UDPポート(51820)のみです。SSH、SMB、DNS、NTP、エッジで動作するその他のサービスは内部インターフェースにバインドされ、クラスター外からアクセスできません。フォワーディングルールはWireGuardインターフェースとクラスターLAN間のパケットを許可しますが、それらのいずれかとプロバイダーの他の内部ネットワーク間は許可しません。デフォルトのフォワードスタンスは、明示的に許可されない限りドロップです。
第2層——各ノードのホストファイアウォール。 すべてのレンダーノードは、エッジスタンスを反映する独自のWindowsファイアウォール設定を持っています——クラスターLAN IPからの、クラスターが必要とするサービス(SMB、リモートデスクトップ、レンダーマネージャー)のインバウンドを受け入れ、他はすべてドロップします。これは冗長ではありません。多層防御です。ノードが誤設定されたり侵害されたりしても、ホストファイアウォールはバリアとして残ります。
両層の背後にある原則は最小権限です。顧客とノードはノードグループだけを見るべきです。顧客にプロバイダーの内部ネットワークへの一般的なルートを与えません。顧客のトンネルはエッジボックスで終端し、エッジボックスはクラスターLANのみにルーティングし、クラスターLANはクラスターメンバー間のみにルーティングします。
実際には、顧客はたとえ望んでもプロバイダーの他のシステムをpingしたりスキャンしたりできません。共有管理プレーンも、他のテナントを公開する共有モニタリングパスもありません。
学んだ教訓
これらは、私たちが立ち上げたすべての専用クラスターで、適用することで何時間ものデバッグを節約するか——忘れて適用しなかったときに何時間ものデバッグを費やすことになった——5つのオペレーション上の教訓です。
1. デュアルホームゲートウェイルーティングの落とし穴。 エッジボックスに2つのネットワークインターフェース(パブリック用とLAN用)がある場合、操作の順序が重要です。LANルートはデフォルトルートが変更される前に設定しなければなりません。デフォルトルートを先に切り替えてからLANルートを追加しようとすると、デフォルトルートが変更された瞬間にログインに使ったSSHセッションがドロップし、ボックスからロックアウトされる可能性があります。修正は技術的ではなく手順的なものです。常に最初に内部ルートを設定し、検証してから、デフォルトルートに触れてください。
2. WireGuardとDNS。 dnsmasqはWireGuardインターフェースを含む、リッスンすべきすべてのインターフェースを明示的にリストしなければなりません。LANインターフェースのみをリストすると、VPNクライアントからのDNSルックアップがタイムアウトします——しかしpingはDNSを経由しないため、応答は正常に届きます。これは私たちが経験した最も診断を誤らせる障害モードの一つです。修正はdnsmasqの設定の1行ですが、どこを見ればよいかを知っている必要があります。
3. トンネル越しのTCP MSSクランプは非オプション。 TLSハンドシェイク、RDPセッション、SMBの大ファイル読み込み——大きなパケットを送りたいものすべて——MSSがクランプされていないとサイレントドロップします。最初の症状は通常「Moonlightが10秒間動いてからフリーズする」または「SMBがディレクトリをリストするが1 MB以上のファイルが読めない」です。修正はWireGuardホストの1つのiptablesルールです。クラスターが引き渡される前に適用してください。
4. ストレージを適切にサイジングし、過剰設計しない。 以前のバージョンのアーキテクチャはXFS上のLUKS暗号化を使ったRAID 10を指定していました。私たちが展開したキャッシュハードウェアは単一SSDでした。RAIDレイヤーを削除し、LUKSレイヤーを削除し、ext4を使用しました——キャッシュは信頼できる情報源ではなく、クラウドプラットフォームがそれだからです。キャッシュレイヤーの紙の上の冗長性をクラウドレイヤーの実際の冗長性に交換したのは正しい選択でした。教訓は、計画書で安全に感じるものではなく、データが実際に必要とするものを中心にストレージを設計することです。
5. キャッシュを事前ウォームアップする。 D-Dayには、すべてのキャッシュミスが国際リンクとクラウドプラットフォームへのラウンドトリップのコストをかけます。コールドキャッシュでのプロダクション開始の最初の1時間は、他のすべてが正しく設定されていても遅く感じます。私たちは今、すべてのエンゲージメントに事前ウォームアップウィンドウを計画します——通常、プロダクション開始の1〜2日前です。アーティストは事前ウォームアップを見ません。最初のフレームからすでに速いと感じるクラスターを見ます。
これらはアーキテクチャ上の教訓ではなく、オペレーション上の教訓です。アーキテクチャドキュメントではなく、デプロイメントチェックリストに存在します。しかし、これらが理論上機能するクラスターと、実際のプロダクション負荷に耐えるクラスターを分けます。より小さなパターンはエンゲージメント単位で適用されます——上記の5つはすべてのデプロイメントで現れたものです。
まとめ
IP管理が契約上の要件であり、エンゲージメントが複数ヶ月にわたり、ワークフローにカスタム設定が必要で、BYOC認証が絶対要件である場合、20ノード越境GPU専用render farmは正しいアーキテクチャです。これらの条件が当てはまらない場合、マネージドrender farmがほぼ常により良い答えです——プロジェクト単位の作業や、専任のオペレーション機能を持たないチームには、ここでのアーキテクチャ上の複雑さは正当化されません。
条件が当てはまる場合、ここで取り上げたパターン——モデルBの認証情報、ext4上の共有キャッシュ、WireGuardハブアンドスポークトランスポート、MSSクランプ付きBBR、リモートデスクトップのMoonlight + Sunshine、2層のファイアウォール——が私たちのデフォルトとして展開するものです。唯一有効なパターンではありませんが、デプロイメントを通じて成立し続けているパターンです。
Super Renders Farmのチームは、マネージドrender farmレンタルと専用クラスターデプロイメントの両方を運営しています——本ガイド全体で説明している専用GPUクラスター構成と越境トポロジーを含めて。
FAQ
Q: 典型的な20ノード専用クラスターのデプロイメントにはどのくらいかかりますか? A: スコープ、施設でのハードウェアの準備状況、顧客のクラウドファイルストリーミングの設定によって異なりますが、典型的なエンゲージメントはハードウェアとネットワークのプロビジョニングに数週間のリードタイムがかかり、プロダクション開始前に1〜2日の事前ウォームアップウィンドウがあります。タイムラインは固定テンプレートではなく、顧客のプロダクションカレンダーに合わせてサイジングします。
Q: チームが3大陸に分散している場合はどうなりますか? A: WireGuardのハブアンドスポークトポロジーは、クラスターアーキテクチャを変更することなく追加のクライアント拠点にスケールします。各リモートアーティストはWireGuardクライアントを実行し、クラスター施設の同じハブに接続します。各リージョンからの遅延は、そのリージョンとハブ間のパブリックインターネットパスによって決まります。私たちの経験では、BBRとMSSクランプがこれらのパスで使用可能と使用不可能の差を生みます。
Q: 複数ヶ月のエンゲージメントにコミットする前にクラスターを確認できますか? A: 通常、スコープ会話の中でプルーフオブコンセプトウィンドウを設けます。正確な形式は顧客のプロジェクトによります——アーティスト体験をテストするための単一ノードのリモートデスクトップセッションの場合もあれば、キャッシュとクラウドファイルストリーミングの統合を検証するための小規模なレンダーテストの場合もあります。具体的な条件はビジネスディスカッションです。お客様のタイムラインに合うものについて話し合うには、営業チームにお問い合わせください。
Q: エンゲージメント終了時のデータセキュリティはどのように処理されますか? A: モデルBは顧客の認証情報を私たちの手から遠ざけるため、エンゲージメント終了時のクロージャーはハードウェアとキャッシュのクリーンアップに集中します。SMBキャッシュをワイプし、クリーンベースラインからすべてのノードを再イメージし、キャッシュとノードイメージが破棄されたことを書面で証明します。顧客は自分のクラウドファイルストリーミングセッションを失効させます。これは私たちのシステム外です。具体的な契約上の言語(NDA、SLA、証明書の文言)は営業チームが処理します。
Q: 20ノード以上が必要な場合はどうなりますか? A: 20ノード構成は私たちが展開する最も一般的な形状ですが、アーキテクチャはそれ以上にスケールします。より大きなフリートは同じ施設内に追加されます——追加の予約済みノードは同じWireGuardハブ、同じSMB3キャッシュ、同じ統一Windowsイメージに接続されます。実際的な制限は通常キャッシュ帯域幅です。単一のエッジ&キャッシュボックスには有限のSMBリードの上限があり、非常に大きなフリートサイズではキャッシュアーキテクチャ自体を再考する必要があります(複数のキャッシュボックス、リージョナルキャッシュ)。これらの設計上の選択はエンゲージメント単位で話し合います。
Q: Cinema 4D、Redshift、その他のDCCツールの自分のライセンスを持ち込めますか? A: ライセンスモデル——BYOL対プロバイダー提供——は、特定のDCCと顧客の既存のライセンスインベントリに依存するビジネス上の決定です。顧客のライセンスできれいに機能する設定もあれば、プロバイダー提供の方がシンプルな場合もあります。スコープ会話の中で解決します。詳細については営業チームにお問い合わせください。
Q: EUとUSプロバイダーからのクラウドストレージはどのように処理されますか? A: クラウドファイルストリーミングプラットフォームは顧客の選択です。私たちのクラスターは、Windowsでサインインクライアントを実行でき、顧客のプロジェクトツリーをマウントされたファイルシステムとして公開できる任意のプラットフォームと統合します。アップストリームクラウドの地理的位置は、顧客からクラスターパスへの国際遅延に影響します——これが越境セットアップにWireGuardハブアンドスポークトランスポートとBBRチューニング設定を推奨する理由です。クラウドプラットフォーム自体はホストしません。顧客のアカウント下に残ります。
Q: WireGuardトンネルが切断された場合はどうなりますか? A: WireGuardは基礎となるネットワークが回復したときに自動的にセッションを再確立します。再ハンドシェイク中にリモートデスクトップセッションが一時的に一時停止する場合があります。レンダリング進行中にトンネルが切断された場合、レンダリング自体はノード上で実行を続けます(進行中の作業はトンネルに依存していません)が、クラウドへの書き戻しはトンネルが回復するまでキューに入ります。エッジボックスからトンネルの正常性を監視し、長時間のダウンタイムにはアラートを出します。
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



