
クラウドベースレンダリングとクラウドコンピューティングレンダリング:2026年版比較ガイド
概要
はじめに
「クラウドレンダリング」を検索すると、実際には異なる2つのものが混在して表示されます。一方はクラウドベースレンダリングで、プロジェクトファイルをアップロードするとフレームが返ってくる専用レンダリングサービスです。もう一方はクラウドコンピューティングレンダリングで、汎用クラウドプロバイダーから仮想マシンを借りて自分でレンダリング設定を行うものです。同じ技術用語を使い、同じハードウェアを多く共有していますが、ワークフロー、料金体系、必要なスキルは、実際に運用してみると大きく異なります。
私たちはこれまで、スタジオがDIYのAWSレンダリング環境からマネージドパイプラインへ移行するケースや、逆にAzureやGoogle Cloud上でカスタム構築するためインハウスチームがIaaSへ切り替えるケースを数多く支援してきました。その都度、トレードオフのパターンは一貫していたため、このガイドにまとめました。
この記事では、クラウドベースレンダリングとクラウドコンピューティングレンダリングのアーキテクチャ上の違い、遭遇するベンダーカテゴリ、各モデルがどのようなチームのワークフローや予算に合うか、どちらのアプローチがコスト面で有利かを判断するためのコスト計算、そしてチームがモデルを切り替える際に多く見られる移行の落とし穴について解説します。
クラウドベースレンダリングとクラウドコンピューティングレンダリング — 本質的な違い
この2つの用語はブログ記事、ベンダーページ、AIアシスタントを問わず同義語として使われていますが、実際は異なります。
クラウドベースレンダリングはサービスの抽象化を意味します。レンダリング専用のインターフェース(デスクトップアップローダー、Webダッシュボード、シーンファイルを受け取ってフレームを返すAPI)を通じて操作します。その下にあるインフラは見えません。ソフトウェア、プラグイン、ライセンス、キュー管理、マシン選択、ファイル転送、ノード管理はすべてベンダーが担います。ユーザーが求めるのはレンダリングされたフレームであり、その間のステップはすべて処理済みです。
クラウドコンピューティングレンダリングはインフラへのアクセスを意味します。汎用クラウド(AWS EC2、Azure Virtual Machines、Google Compute Engine、または専門的なGPU IaaSプロバイダー)から仮想マシン(またはベアメタルインスタンス)を借りて自分で運用します。Cinema 4DやMayaをインストールし、RedshiftやV-Rayを設定し、ファイルパスを構成し、レンダーマネージャーを起動し、ジョブを監視し、完了後にすべてシャットダウンします。クラウドプロバイダーが提供するのはCPU/GPU/RAM/ディスクとネットワークです。オペレーティングシステムより上のすべてはユーザーの責任です。
どちらも最終的にはディスク上に同じ成果物を生成します。そこへ至る過程が異なります。
| 比較項目 | クラウドベースレンダリング | クラウドコンピューティングレンダリング |
|---|---|---|
| 主な購入単位 | レンダリングされたフレームまたはレンダー時間 | 仮想マシン時間 |
| ソフトウェアインストール | ベンダーが実施 | 自分で実施 |
| レンダリングエンジンのライセンス | 料金に含まれるかベンダーが管理 | 自分のライセンスを持参 |
| ファイル転送 | 組み込みアップローダー / S3方式 | 自分で設定 |
| スケーリング | 利用可能なノード全体で自動 | 手動またはスクリプトで制御 |
| 必要なスキル | レンダーアーティスト | レンダーアーティスト+クラウドオペレーションエンジニア |
| 最初のフレームまでの時間 | アップロード後数分 | 30〜90分(イメージビルド、ライセンス、ファイル同期) |
| アイドル課金 | なし — アクティブなレンダリング中のみ課金 | あり — 終了するまでVMの時間が積算される |
この違いが重要なのは、多くの「クラウドレンダリング」に関する判断が、実際にはどの抽象化レイヤーで操作したいかという判断であるためです。
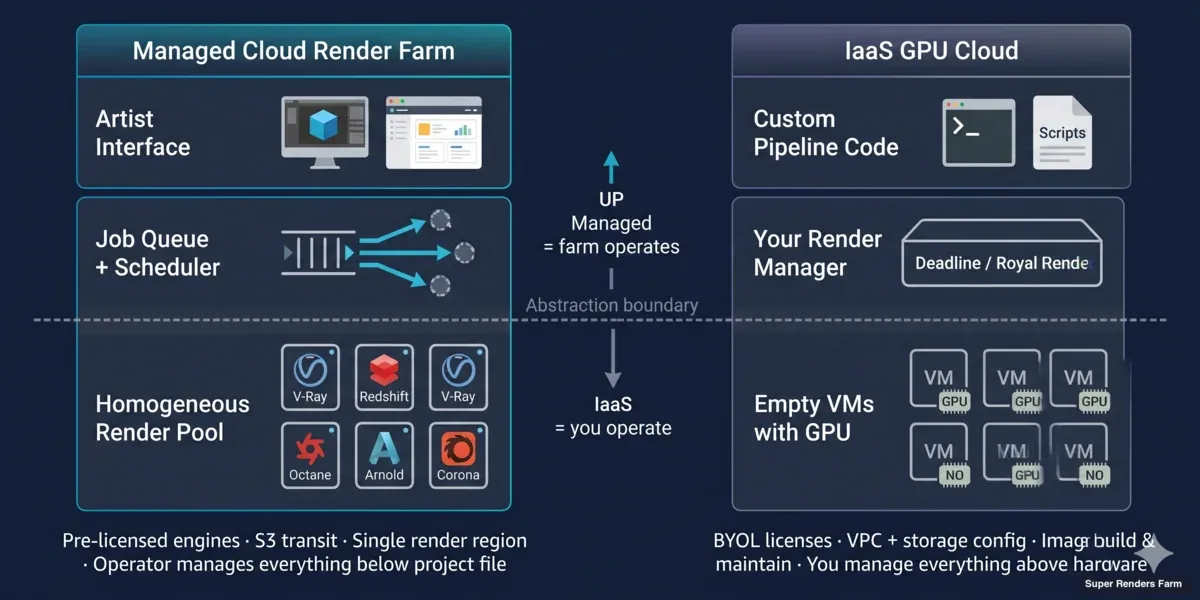
アーキテクチャの違い:マネージドレンダーファーム vs IaaS GPU クラウド
クラウドベースレンダリングサービスとクラウドコンピューティングレンダリングプラットフォームは、単にコンピュートのパッケージ方法が異なるだけでなく、異なる運用モデルのために構築されています。
マネージドクラウドレンダーファームのアーキテクチャ(クラウドベース):
レンダーファームのオペレーターは、ジョブキューの背後に均質なフリートを運用しています。すべてのノードには同じDCCソフトウェアがプリインストールされ、同じレンダリングエンジンのライセンス、同じネットワーク共有、同じ監視エージェントが備わっています。プロジェクトを送信すると、スケジューラーがフレームレベルのタスクに分割し、プール内の利用可能なノードに振り分けます。ユーザーがマシンを選ぶ必要はなく、プールが自動的に選択します。
弊社のファームでは、そのプールはCPUフリート全体で20,000以上のCPUコアと、NVIDIA RTX 5090(VRAMは各32 GB)を搭載した専用GPUマシンで構成されています。プロジェクトファイルはAWS S3を介してユーザーのマシンとレンダーノード間で転送されます。S3はここでは単なる転送レイヤーであり、コンピュートではありません。コンピュートはハノイにある1つのレンダリングリージョン内に集約されており、フレーム間のレイテンシを低く抑え、ライセンス管理をシンプルにしています。Maxonの公式パートナーおよびChaos Groupのレンダーパートナーとして、ファーム側でレンダリングエンジンのライセンスを管理しています。
Super Renders Farmはこのマネージドモデルで運用するGPU・CPUレンダーファームであり、キュー、ノードの選択、ライセンス管理はユーザー側ではなくオペレーター側にあります。
IaaS GPU クラウドのアーキテクチャ(クラウドコンピューティングレンダリング):
IaaS GPUプロバイダーは、GPUが接続された空のLinuxまたはWindowsインスタンスを提供します。AWS、Azure、GoogleはすべてGPUインスタンスを提供しており、CoreWeave、RunPod、Lambda、Vast.aiなどの専門プロバイダーは価格とプロビジョニング速度で競っています。彼らはRedshiftが何かを知りません。レンダリングをしているのか、モデルをトレーニングしているのか、動画をトランスコードしているのかを気にしません。
ユーザーが担当するのは次のすべてです:DCCとレンダリングエンジンがインストールされたマシンイメージのビルドまたは入手、ライセンスサーバーのアタッチまたはノードロックライセンスの移行、ストレージのマウント(ブロックストレージ、オブジェクトストレージ、またはNFS)、そのストレージへのシーンとアセットのコピー、レンダーマネージャーの起動(Deadline、Royal Render、カスタムスクリプト、または単純にredshiftCmdLine)、障害の監視、そしてアイドル時間が加算される前にすべてを終了することです。
抽象化の違いは明確です。クラウドベースのレンダーファームはインフラに関する選択肢の80%を隠蔽します。IaaS GPU クラウドはそのすべてを露出させます。
Layered architecture diagram comparing managed cloud render farm operations versus IaaS GPU cloud rendering operational responsibilities
クラウドベースレンダリングが適している場面
マネージドサービスモデルは、創造的なアウトプットに価値を置き、DCCでの作業に時間を使うべきチームに最適です。DevOpsには向きません。
Super Renders Farmはこのカテゴリーにおけるマネージドレンダーファームの選択肢の一つであり、以下のトレードオフはクラウドベースの抽象化を運用するあらゆるベンダーに当てはまります。
フリーランサーや1〜3人のモーションデザイン / 建築ビジュアライゼーション(archviz)スタジオ。 マルチノードのIaaS GPUパイプラインを構築することは、チームにクラウドのスキルがあり、月に100時間以上レンダリングする場合にペイします。それ以下では、イメージのメンテナンス、ライセンスサーバーの稼働維持、請求の予期せぬ増加といった運用上のオーバーヘッドがコスト削減を食い尽くします。
締め切り重視のパイプラインを持つスタジオ。 クライアントが納品を2日前倒しした場合、マネージドファームであればジョブの優先度を調整してスケーリングできます。IaaSでは、追加インスタンスのプロビジョニング、アセットのコピー、設定、そしてレンダーマネージャーへの組み込みが必要となり、締め切りに間に合うかどうかわかりません。
ボリュームライセンスなしで商用レンダリングエンジンを使用するチーム。 Redshift、V-Ray、Corona、Octane、Arnoldはすべて、自分で管理すると高額になるレンダーノードライセンス条件があります。弊社のモデルではそれらのライセンスをフレーム単価またはGHz時間単価に含んでいます。IaaSでは自分のライセンスを持参し、ノードロックを消費していきます。
一晩の失敗が締め切りを壊しかねない制作。 マネージドファームには、ほとんどの障害パターンを経験したサポートスタッフがいて、レンダリング中のジョブに介入できます。IaaSでは、深夜2時にスタックしたレンダリングをデバッグするのはユーザー自身です。
トレードオフは柔軟性です。マネージドファームはテスト済みのエンジンとプラグインバージョンで動作します。プロジェクトがまだ追加されていない新しいプラグインに依存している場合、サポートが検証するまで待つ必要があります。IaaSでは好きなものをインストールできます。
クラウドコンピューティングレンダリングが適している場面
IaaSモデルは、パイプライン自体が製品であるチームや、マネージドファームのカタログをはるかに超えたレンダリングニーズを持つチームに適しています。
カスタムまたは独自のレンダーパイプラインを持つチーム。 社内レンダラーを構築し、オープンソースエンジンを改変し、または非標準の分散パイプラインをカスタム依存関係で運用している場合、どのマネージドファームも一晩でそれを吸収することはできません。生のコンピュートを借りてオーケストレーションをスクリプト化するしか選択肢はありません。
MLとレンダリングのハイブリッド。 ガウシアンスプラッティング、ニューラルラジアンスフィールド、AIデノイズパイプライン、または独自モデルのトレーニングとレンダリングを並行して行うチームは、フルスタックを所有することで恩恵を受けます。フレームをレンダリングするのと同じGPUインスタンスで、レンダリングの合間に推論ジョブを実行できます。マネージドファームはその柔軟性を提供しません。
社内にクラウドオペレーションのスキルとLinuxに慣れたアーティストがいるスタジオ。 インハウスチームがすでに他のワークロードでAWS、Azure、またはGoogle Cloudを運用している場合、その上にレンダーパイプラインを追加することで、既存のスキル、請求、セキュリティの境界を再利用できます。
レンダーファームの料金モデルに合わないワークロード。 一部のパイプラインは、長時間のインタラクティブセッション(たとえば、ライブプレビューで重いシーンを反復するテクニカルアーティスト)を必要とし、フレーム単価の課金とうまく合いません。一日のためにインスタンスを借りる方が、モデルと格闘するよりも安上がりです。
トレードオフは運用コストです。クリエイティブな業務の上に、小規模なレンダー管理業務を運営することになります。これは現実のコストです。
コスト比較:クラウドベース vs クラウドコンピューティングレンダリング
どちらのモデルも低い時間単価を宣伝していますが、レンダリングを実際に完了させるために必要なすべてを含めると、総コストは大きく異なります。
クラウドベースレンダリング(フレーム単価またはGHz時間単価):
アクティブなレンダリング時間に対してのみ支払います。ライセンスコスト、マシンのアイドル、ソフトウェアの更新、サポート、ジョブ中のストレージはすべて料金に含まれています。GPUティアのハードウェアで1分/フレームの720フレームのモーションデザインカットは、弊社ファームの標準優先度で概ね15〜30ドル程度です。CPUで3分/フレームの1,500フレームの建築ビジュアライゼーションアニメーションは概ね80〜150ドル程度です。驚きはありません。ジョブを実行する前に見積もりが表示され、終了後に最終金額が表示されます。
クラウドコンピューティングレンダリング(VMの時間単価+その他諸々):
表面上の数字はGPUインスタンス料金です。AWS p5インスタンス(H100)、Azure NDv5、Google A3は構成によって概ね5〜30ドル/時間です。CoreWeave、RunPod、Vast.aiなどの専門GPUクラウドはコンシューマーグレードGPUで0.40〜2.50ドル/時間程度とさらに低い価格を掲げています。
インスタンス料金はあくまでも出発点です。次のものを加算してください:アウトバウンドのデータ転送(AWSで0.05〜0.09ドル/GB — 50 GBのプロジェクトを100 GBのEXRシーケンスとして取り出すと実際の費用が発生します)、オブジェクトストレージ(アイドル状態で0.023ドル/GB-month)、プロビジョニング時間(最初のフレームがレンダリングされるまでの有料時間30〜90分)、ライセンスコスト(Redshiftのノードロックは約45ドル/月/シート、V-Rayのレンダーノードは各約42ドル/月 — 使用率に関わらず課金)、BYOLを使用する場合はライセンスサーバーの稼働コストも加算されます。チームの実コストエンジニアリングレートが80〜150ドル/時間であれば、クラウドオペレーションのデバッグに費やす時間もすべてトータルコストに加算されます。
公平な比較を行うために、私たちはレンダーファームとインハウスのコスト比較とレンダーファームの料金モデルを通じてチームに判断材料を提供してから決定を下します。表面上の料金は当てになりません。IaaSで60%安く見えるはずの時間単価も、ライセンス、転送、アイドル、運用時間を加えると、通常10〜15%の差まで縮まります。それも締め切りリスクのイベントを考慮する前の話です。

Stacked bar infographic comparing total cost composition between cloud-based render farm pricing and IaaS GPU cloud rendering with hidden costs flagged
ベンダーカテゴリ:マネージドクラウドレンダーファーム vs IaaS GPU クラウド vs ハイブリッド
ベンダーの状況は抽象化のラインに沿って明確に分かれており、中間に小さなグループが存在します。
純粋なマネージドクラウドレンダーファーム。 このカテゴリのベンダーは独自の均質なレンダープールを運用し、レンダリングエンジンのライセンスを事前に取得し、レンダリング専用インターフェースを提供します。オペレーターはプロジェクトファイル以下のすべてのレイヤーを処理します。料金はフレーム単価、レンダー時間単価、またはGHz時間単価で、決してVM時間単価ではありません。典型的なワークフロー:デスクトップアプリをインストール → プロジェクトをアップロード → レンダリング → ダウンロード。
純粋なIaaS GPU クラウド。 AWS、Azure、Google Compute Engine、および専門プロバイダー(CoreWeave、RunPod、Lambda、Paperspace、Vast.ai)。GPUが接続された仮想マシンを販売します。一部はマーケットプレイス経由でDCCイメージを公開していますが、運用モデルは依然として「ボックスを借りて、独自のソフトウェアを実行する」です。
ハイブリッドプラットフォーム。 IaaS上にマネージドオーケストレーションを提供する小さな中間層があります。たとえば、AWSインスタンスをプロビジョニングし、ウィザードでレンダリングエンジンをインストールし、ジョブを分割するサービスなどです。これらはセットアップの負担を軽減しますが、ライセンス管理やサードパーティクラウドプロバイダーの料金変動への依存を排除するわけではありません。内部チームにクラウドアカウントとクレジットがあるがレンダーパイプラインの専門知識が不足している場合に役立ちます。
適切なベンダーカテゴリは、実際に何の抽象化が必要かによって完全に異なります。チームが間違った階層を選ぶことがあります。たとえば、クラウドオペレーション時間を予算化せずに「コスト削減」のためIaaSを選んだり、マネージドファームを選んでカスタムプラグインをインストールしようとしたりします。私たちが見る多くのパイプラインの問題は、チームの運用実態に合わないモデルのベンダーを選ぶことから生じています。
移行パス:クラウドベースとクラウドコンピューティングレンダリング間の移行
チームは双方向に移行します。最も多く見られるパターンは次のとおりです。
AWS上のDIYクラウドレンダリング → マネージドクラウドレンダーファーム。
よくあるきっかけ:小さなスタジオが1年前にSpotインスタンス+Deadlineのパイプラインを構築したが、それを構築したエンジニアが退職し、現在のチームはレンダリングの夜を問題なく乗り切れなくなった。移行は通常すぐに完了します。デスクトップアプリのインストール、シーンの準備の確認、テストレンダリングに数時間かかる程度です。難しいのは古いパイプラインを丁寧に廃止する部分です(予約済みインスタンスのキャンセル、チームが構築したSpot AMIのアーカイブ、バケットポリシーが変わる前にS3から古いレンダリングをエクスポートするなど)。
マネージドクラウドレンダーファーム → カスタムIaaSパイプライン。
よくあるきっかけ:スタジオが成長し、レンダーパイプラインエンジニアを採用し、ワークフローがどのファームオペレーターのカタログも超えていることに気づいた — カスタムAOVパス、独自のポストレンダースクリプト、または内部アセットDBとの統合など。移行は簡単ではありません:DCCイメージのビルドと維持、ライセンスサーバーの設定、レンダーマネージャーの選択、ストレージレイアウトの設計、監視のスクリプト作成。日単位ではなく週単位での予算を見込み、最初の3ヶ月は最適化が追いつくまで以前のファームの費用より高くなることを覚悟してください。
ハイブリッド(ワークロード分割)。
一部のスタジオは両方を運用しています。信頼性が重要な日常のクライアント業務にはマネージドファームを、柔軟性が重要な実験的または独自パイプラインにはIaaSを使います。二重の費用は煩わしいですが、運用上の適合性は良好です。
クラウドコンピューティングレンダリング設定の一般的な落とし穴
クラウドコンピューティングレンダリングプロジェクトのほとんどは、同じいくつかの場所で失敗します。IaaSの方法を選ぶ場合、節約できるお金は、これらを避けた場合にのみ現実のものになります。
転送コストの過小評価。 アウトバウンドのデータ料金(AWSで0.05〜0.09ドル/GB、Azure/GCPも同様)はEXRシーケンスでは急速に積み上がります。4Kアニメーションは数百GBを生成することがあります。400ドルのレンダリング予算を計画し、エグレスを見込んでいなかったために1,200ドルの請求書を受け取ったチームを見てきました。
アイドル時間の見落とし。 オペレーターが終了させるのを忘れた結果、週末中ずっと動き続けたGPUインスタンスは、レンダリング自体と同じだけコストがかかります。Spotインスタンスはこれを軽減しますが、スポット価格が変動するとレンダリング途中で終了するリスクがあります。
イメージビルド時間の過小評価。 動作するDCC+レンダリングエンジン+プラグインのイメージを最初から構築するには、1〜3日のエンジニアリング作業が必要です。さらにリリースサイクルごとに継続的なメンテナンスも発生します。チームはクラウドの費用だけ予算化し、イメージメンテナンスの時間を見込みません。
ライセンスサーバーの脆弱性。 VPC経由で一時的なインスタンスにトンネリングされたフローティングライセンスは、レンダリングのバグのように見える形で失敗します。固定の専用ライセンスを割り当てることで解決しますが、コストが上がります。
ストレージ選択のミス。 レンダリングに直接オブジェクトストレージをマウントするとI/Oレイテンシのスパイクが発生します。ブロックストレージは高速ですが、サイズとローカリティに制限があります。経験豊富なIaaSパイプラインのほとんどは、ハイブリッド(アーカイブ用にオブジェクト、アクティブなジョブの作業セット用にブロック)を使用しており、さらに設定の複雑さが増します。
ファイルパスの不一致。 WindowsワークステーションでオーサリングされたCinema 4DやMayaのシーンは、Linuxのレンダーインスタンス上には存在しない絶対パスやローカルドライブレターを参照していることがよくあります。パスのリマッピングは「テクスチャが見つからない」という障害の最も一般的な原因です。
これらの障害モードはマネージドファームでは発生しません。ファームオペレーターが一元的に処理するからです。これらはIaaSモデルに付随する運用コストです。
判断フレームワーク:どのモデルを選ぶべきか
ほとんどのチームを適切な階層に当てはめる短いチェックリストです。
クラウドベースレンダリング(マネージドファーム)を選ぶ場合:
- 月に100時間未満のレンダリング量
- チームが1〜5人でクリエイティブなアウトプットに集中している
- 標準的な商用レンダリングエンジン(V-Ray、Corona、Arnold、Redshift、Octane、Cycles)を使用している
- 専任のクラウドオペレーションエンジニアがいない
- 締め切りの信頼性が請求の柔軟性より重要
クラウドコンピューティングレンダリング(IaaS GPU)を選ぶ場合:
- カスタムまたは非標準のレンダーパイプラインがある
- チームにアクティブなクラウドオペレーション経験者がいる
- 他のクラウドワークロード(ML、内部アセットDB、カスタムサービス)と密接に統合する必要がある
- ワークロードにフレームバッチだけでなく、インタラクティブな長時間セッションが含まれる
- パイプラインを運用するためのエンジニアリング時間を予算化できる
ハイブリッドを検討する場合:
- 日常のクライアント業務が標準エンジン+締め切り重視(マネージド)
- R&Dや実験的な作業がカスタム(IaaS)
- 2つが同じプロジェクトで重複しない
私たちが一緒に取り組むほとんどのスタジオでは、IaaSの運用コストが一貫して過小評価されるため、マネージドファームモデルがトータルコストで優位に立ちます。
これがSuper Renders Farmのようなマネージドサービスの背景にある理屈です。フレーム単価とGHz時間単価が、IaaS予算では別途負担しなければならないライセンス、アイドル、サポートのオーバーヘッドを吸収します。 本当にエンジニアリング能力と非標準なワークロードを持つチームの約10〜15%にとっては、IaaSが正解です。残りの約10%はハイブリッドに位置します。
この判断のコスト面を試算する場合、料金計算ツールでマネージドファームの料金に対するプロジェクト単位の見積もりを確認できます。それをライセンス、転送、アイドル、運用時間を含めた正直なIaaS予算と比較することが、唯一公平な判断方法です。両方のモデルにまたがる分散レンダリングの仕組みについては、クラウドレンダリング解説ガイドでコアアーキテクチャを説明しています。また、マネージドvs DIYクラウドレンダリングの比較では、最も多く見られる運用上のトレードオフをより詳しく解説しています。
FAQ
Q: クラウドベースレンダリングとクラウドコンピューティングレンダリングの違いは何ですか? A: クラウドベースレンダリングはサービスの抽象化です。プロジェクトをレンダリング専用のプラットフォームにアップロードするとレンダリングされたフレームが返ってきて、ソフトウェア、ライセンス、インフラはベンダーが処理します。クラウドコンピューティングレンダリングはインフラへのアクセスです。汎用クラウドプロバイダーから仮想マシンを借りて自分で設定します。ディスク上の最終成果物は同じですが、そこへ至る道筋は大きく異なります。
Q: クラウドコンピューティングレンダリングは常にマネージドクラウドレンダーファームより安いですか? A: 実際はそうとは限りません。AWS、Azure、または専門GPUクラウドのVM時間の表面上の料金は低く見えることが多いですが、トータルコストにはレンダリングエンジンのライセンス、アウトバウンドのデータ転送料金、ストレージ、最初のフレームが出るまでのプロビジョニング時間、イメージのメンテナンス、パイプラインを運用するためのエンジニアリング時間を含める必要があります。それらを含めると、標準的なワークロードでは通常10〜15%の差まで縮まります。IaaSがコスト面で優位になるのは、チームに既存のクラウドオペレーション能力があり、運用上のオーバーヘッドを吸収できる場合のみです。
Q: レンダーファームの代わりにAWSやAzureをレンダリングに使えますか? A: 使えますし、多くのチームがそうしています。ただし、異なるスキルセットが必要です。DCCとレンダリングエンジンを自分でインストールし、ライセンスを管理し、ストレージとネットワークを設定し、再利用可能なマシンイメージを構築し、レンダーマネージャーを運用することになります。カスタムパイプライン、MLとレンダリングのハイブリッド、またはインハウスのクラウドオペレーション経験を持つチームには合っています。標準的なワークフローで商用レンダリングエンジンを使用する場合、マネージドクラウドレンダーファームの方が作業量が少なく、トータルコストは近似することが多いです。
Q: マネージドクラウドレンダーファームとは何ですか?IaaS GPU クラウドとどう違いますか? A: マネージドクラウドレンダーファームは、ジョブキューの背後に設定済みのレンダーノードの均質なフリートを運用しています。プロジェクトをアップロードすると、システムが利用可能なノード全体にフレームをスケジュールし、結果を受け取ります。IaaS GPU クラウドはGPUが接続された空の仮想マシンを販売します。DCCソフトウェア、レンダリングエンジン、スケジューラー、ライセンスは含まれていません。レンダーファームモデルは運用のシンプルさと引き換えに柔軟性を放棄し、IaaSモデルはシンプルさと引き換えに柔軟性を得ます。
Super Renders Farmは、この対比におけるマネージドレンダーファーム側の一例です。プロジェクトを送信してフレームを受け取り、レンダリングエンジン、ライセンス、スケジューリングはファーム側で処理されます。
Q: AWSのDIYクラウドレンダリングからマネージドレンダーファームへの移行をいつ検討すべきですか? A: よく見られるきっかけ:元のパイプラインを構築したエンジニアが退職してチームが維持できなくなった、クラウドの費用が同等のマネージドファーム費用を超えた、締め切りに重要なジョブが時間外に失敗するようになった、またはチームがクラウドオペレーションよりもクリエイティブな業務に多くの時間を費やしていることに気づいた。移行自体は通常すぐに完了します。デスクトップアプリのインストール、シーンの準備、テストレンダリングで済みます。ただし、継続的に費用が発生しないよう古いAWSインフラを丁寧に廃止する時間を確保してください。
Q: クラウドレンダーファームにはレンダリングエンジンのライセンスを持参する必要がありますか? A: 公式パートナーシップのもとで運営されているほとんどのマネージドクラウドレンダーファームでは不要です。V-Ray、Corona、Arnold、Redshift、Octane、Cyclesのレンダーライセンスは料金に含まれています。IaaS GPU クラウドではほぼ必ず自分のライセンスを持参する必要があります。特定のインスタンスにノードロックされたもの(安いが柔軟性がない)か、ライセンスサーバーを通じてフローティングさせるもの(柔軟だが運用上の脆弱性がある)のいずれかです。ライセンス管理は自前でクラウドレンダリングを運用する場合の最大の隠れコストの一つです。
Q: クラウドベースのレンダリングサービスは通常どのようなハードウェアを使用していますか? A: 最新のクラウドレンダーファームは、プロダクションレンダリング用にサイズ設定されたCPUとGPUハードウェアの組み合わせを運用しています。弊社のファームでは、V-Ray、Corona、Arnoldなどのエンジン向けに20,000以上のCPUコアと、Redshift、Octane、V-Ray GPUのためにNVIDIA RTX 5090(VRAM 32 GB)を搭載した専用GPUマシンを運用しています。
Super Renders Farmはこのフリートを汎用コンピュートではなくプロダクションレンダリング向けにサイジングしており、これがジョブごとに構成する必要のあるIaaS GPUインスタンスとの実質的な違いです。 IaaS GPU クラウドはコンシューマーグレードのRTX 4090からデータセンター用のH100まで幅広い選択肢を提供しており、価格帯も大きく異なります。商用レンダリングにおいては、RTXグレードのGPUがモデルを問わず通常コストパフォーマンスの最適点となります。
Q: クラウドレンダーファームでインタラクティブまたはライブプレビューのレンダリングは実行できますか? A: マネージドクラウドレンダーファームはバッチワークロード向けに最適化されています。プロジェクトを送信し、フレームをレンダリングし、結果を受け取るというものです。ライブのIPRフィードバックを伴うインタラクティブなレンダリングはワークステーションの領域であり、ファームの領域ではありません。クラウドで長時間のインタラクティブセッションが必要な場合、リモートデスクトップアクセスのあるIaaS GPUインスタンスが適切な形です。ただし、それはクラウドコンピューティングレンダリングであり、クラウドベースレンダリングではありません。2つのモデルは本質的に異なる問題を解決します。
About Alice Harper
Blender and V-Ray specialist. Passionate about optimizing render workflows, sharing tips, and educating the 3D community to achieve photorealistic results faster.



