Cách triển khai render farm GPU dedicated 20 node xuyên biên giới (2026)
Tổng quan
Giới thiệu
Khi một đội creative yêu cầu một render farm (hệ thống máy tính kết xuất) dedicated trải dài qua nhiều quốc gia, họ gần như luôn đang giải quyết một ràng buộc mà render farm SaaS không thể xử lý. Đó có thể là một studio mà hợp đồng không cho phép bên thứ ba giữ credentials, một đội phân tán có artist ở một quốc gia điều khiển node ở quốc gia khác, hoặc một hãng production có engagement nhiều tháng khiến việc tính phí theo frame trở nên không còn kinh tế.
Theo kinh nghiệm của chúng tôi, phần khó hiếm khi là "thuê thêm GPU". Đó là kết nối đúng các thành phần: cloud storage thuộc sở hữu khách hàng, một GPU fleet riêng được sizing đúng theo workload, transport xuyên biên giới được mã hoá chịu được jitter, và một lớp remote desktop không sụp đổ khi mở một 3D viewport nặng. Khi một thành phần sai, cluster vẫn chạy, nhưng artist nhận ra — và engagement âm thầm suy giảm.
Chúng tôi vận hành Super Renders Farm, một cloud render farm với fleet CPU + GPU đáng kể, và cũng dựng dedicated GPU cluster cho các đội mà workflow không phù hợp với managed service của chúng tôi. Bài viết này là cẩm nang thực địa từ những triển khai đó — cách chúng tôi kiến trúc một dedicated GPU render farm 20 node phục vụ đội creative phân tán gồm các artist xuyên biên giới từ một cơ sở dedicated duy nhất, kèm ghi chú thực tế về các lựa chọn đã thực hiện, các lựa chọn đã rút lại, và bài học chúng tôi nay áp dụng mặc định. Nếu bạn đang cân nhắc hạ tầng dedicated so với dịch vụ thuê render farm managed của chúng tôi, cẩm nang này sẽ giúp bạn quyết định liệu con đường dedicated có đáng với diện tích kiến trúc bổ sung không.
Tiêu chí quyết định: Dedicated hay SaaS
Hầu hết workload rendering không cần dedicated cluster. Một managed cloud render farm nhận scene, schedule các frame, và tính phí theo phút. Không có hạ tầng để sở hữu, không có firewall để duy trì, và không có đội vận hành cần chỉ định phía khách. Với công việc theo dự án — một short film, một quảng cáo 30 giây, một batch ảnh tĩnh — mô hình đó thắng trên mọi tiêu chí quan trọng.
Dedicated cluster chỉ biện minh được sự phức tạp khi một hoặc nhiều điều sau đúng:
- Kiểm soát IP là điều khoản hợp đồng, không phải tuỳ chọn. Master service agreement hoặc hợp đồng với end-client của khách hàng cấm bên thứ ba giữ scene file hoặc render credentials. SaaS pipeline trung gian việc upload scene vi phạm ràng buộc đó dù compute bên dưới giống hệt.
- Engagement kéo dài nhiều tháng, không phải nhiều ngày. Công việc có hình dạng cố định — series animation dài hạn, archviz pipeline nhiều quý, virtual production stage đang chạy — khấu hao chi phí kiến trúc ban đầu. Tính phí theo frame ngược lại nhân tuyến tính theo thời gian và ngừng cạnh tranh sau một thời hạn nhất định.
- Workflow đủ tuỳ chỉnh đến mức managed pipeline không thể host. DCC plugin stack tuỳ chỉnh, render manager nội bộ, simulation-heavy pipeline pre-bake vào shared cache, hoặc tool chain độc quyền — tất cả đều đẩy về dedicated node mà khách có thể cấu hình trực tiếp.
- Bring-your-own-cloud là yêu cầu cứng. Khi project asset của khách sống trong một cloud file-streaming platform dưới tài khoản của khách, cluster phải sign in như khách, không phải như nhà cung cấp hạ tầng. Đây là pattern "Model B" được thảo luận chi tiết bên dưới.
- Nhu cầu network segmentation vượt VLAN per-tenant. Một số workflow yêu cầu cluster vô hình với mạng rộng hơn của nhà cung cấp — không chỉ cô lập logic, mà còn cô lập theo route.
Nếu không tiêu chí nào áp dụng, managed render farm gần như luôn là lựa chọn đúng. Nếu hai hoặc nhiều áp dụng, cuộc trò chuyện chuyển về hướng dedicated. Câu hỏi còn lại là địa lý: các artist thực hiện công việc có ở gần cơ sở không, hay cluster cần phục vụ họ qua backbone ISP công cộng vượt qua biên giới quốc gia?
Tổng quan kiến trúc
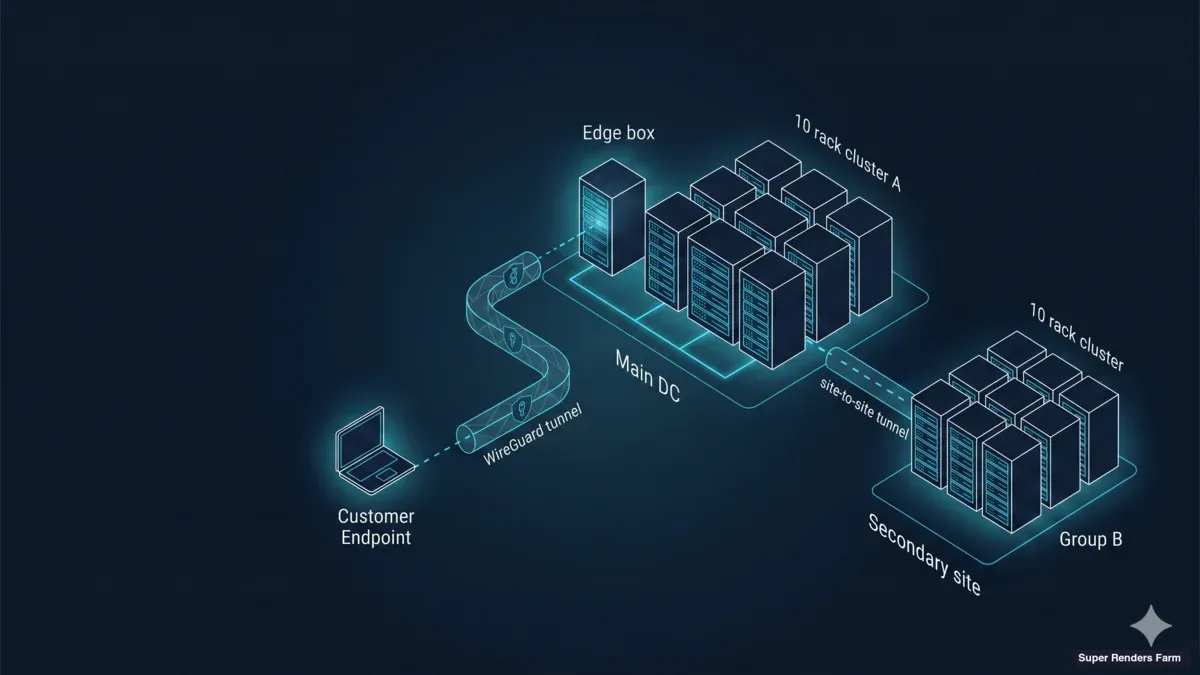
Kiến trúc chúng tôi triển khai cho dedicated cluster xuyên biên giới có ba plane: transport plane, compute plane, và storage-acceleration plane. Mỗi plane có một failure-mode duy nhất mà theo kinh nghiệm của chúng tôi là nguyên nhân phần lớn nỗi đau vận hành khi nó hỏng.
[ Artist từ xa — phân tán qua các quốc gia ]
│
│ WireGuard hub-and-spoke
│ (UDP 51820, mã hoá đầu cuối,
│ BBR + MSS-clamped transport)
▼
┌─────────────────────────────────────────────────────┐
│ Super Renders Farm — cơ sở cluster dedicated │
│ │
│ ┌─────────────────────────────────────────────┐ │
│ │ EDGE + CACHE BOX (single Ubuntu host) │ │
│ │ • WireGuard hub (NAT/MASQUERADE) │ │
│ │ • Samba SMB3 cache (single SSD, ext4) │ │
│ │ • dnsmasq (zone .lan) │ │
│ │ • chrony (NTP) │ │
│ │ • ufw + BBR + TCP MSS clamp │ │
│ └────────────────────┬────────────────────────┘ │
│ │ LAN │
│ ┌────────────────────▼────────────────────────┐ │
│ │ 20 × RTX 5090 render node │ │
│ │ (Windows 11 Pro, Sunshine, cloud file- │ │
│ │ stream client, cache mount — uniform │ │
│ │ image cho toàn fleet) │ │
│ └─────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
│
▼
[ Cloud file-streaming platform của khách —
khách sign in trên mỗi node; Super Renders Farm
không giữ credentials (Model B) ]
Transport plane là WireGuard, theo pattern hub-and-spoke. Workstation của mỗi artist kết nối tới hub tại cơ sở cluster qua tunnel UDP được mã hoá; tất cả traffic artist-to-cluster, bất kể artist ngồi ở quốc gia nào, đều đi qua cùng topology tunnel. Compute plane là hai mươi node Windows 11 Pro, mỗi node chạy một NVIDIA RTX 5090 với 32 GB VRAM, triển khai như một pool đồng nhất duy nhất tại một cơ sở. Storage-acceleration plane là một edge-and-cache box duy nhất tại cơ sở, host Samba SMB3 share backed bởi một SSD duy nhất trên ext4 — cùng với các network service mà cluster phụ thuộc (DNS, NTP, firewall).
Quyết định thiết kế then chốt: edge box và cache box là cùng một máy. Phiên bản kiến trúc trước đó đặt edge gateway trên một thiết bị riêng và cache trên một NAS, tạo ra race condition khi cold pull và hai bề mặt để vá. Gộp vào một Ubuntu 22.04 LTS host duy nhất đã loại bỏ cả hai vấn đề. Box trở thành tài nguyên quan trọng — nhưng dữ liệu project của khách vẫn sống trên cloud file-streaming platform, nên cache re-warm từ upstream sau bất kỳ lỗi local nào.
Setup cluster GPU 20 node
Sizing mặc định cho các triển khai mô tả ở đây là hai mươi node RTX 5090, triển khai như một pool đồng nhất duy nhất trong một cơ sở. Đây là size liên tục map tốt với đội creative trong dải mười đến hai mươi artist — dải mà dedicated cluster khấu hao cho workflow nhạy cảm với IP.
Mỗi node có cùng hình dạng phần cứng: một RTX 5090 với 32 GB VRAM, một CPU multi-core hiện đại, 64 GB hoặc 128 GB RAM hệ thống, và một disk NVMe local được sizing cho OS và scratch. Dữ liệu project bền vững sống trên shared cache hoặc trong cloud file-streaming platform upstream — không bao giờ trên node.
OS trên mỗi node là Windows 11 Pro, triển khai từ image sạch. Chúng tôi cố ý không pre-load DCC plugin stack vào node image. Khách điều khiển việc cài DCC tool của họ — Cinema 4D, Redshift, Houdini, After Effects, Blender và các tool khác — để node image giữ tối giản và tái lặp được. Khi engagement kết thúc, chúng tôi wipe và reimage từ cùng baseline sạch đó.
Chúng tôi chọn 32 GB VRAM mỗi node có chủ ý. Các renderer GPU hiện đại — Redshift, Octane, Arnold GPU, Cycles — ngày càng load scene có texture lớn đơn giản là không vừa trong card 24 GB. RTX 5090 ở 32 GB là điểm ngọt ngào hiện tại cho production renderer; nó xử lý hầu hết công việc archviz, motion design, và animation mà không cần paging sang RAM hệ thống — đó là nơi mixed GPU pool âm thầm trở nên chậm.
Hai mươi node được cấu hình giống hệt nhau — cùng image, cùng bộ DCC install, cùng cache mount, cùng route WireGuard — và hiện ra như một pool duy nhất với render manager của khách. Deadline, Royal Render, hoặc scheduler của khách coi fleet như một tài nguyên mà không cần bất kỳ logic routing per-group hay rebalancing thủ công. Frame chuyển đến node nào rảnh; render manager của khách xử lý phân phối tải ở lớp job-queue.
Fleet routable layer-3 — khách cài render manager của họ và submit từ workstation từ xa thay vì điều khiển từng node qua remote desktop. Điều này quan trọng hơn mọi người nghĩ: đó là sự khác biệt giữa một cluster artist phải vật lộn và một cluster artist quên mất.
Customer-Owned Credentials (Model B)
Quyết định kiến trúc đơn lẻ thường xuyên nhất khiến dedicated cluster trở thành câu trả lời đúng cho workflow nhạy cảm với IP là cái chúng tôi gọi là Model B: credentials thuộc sở hữu khách. Trong Model A — mặc định cho managed render farm, bao gồm dịch vụ SaaS của chính chúng tôi — nhà cung cấp hạ tầng giữ credentials của rendering pipeline. Khách upload scene file; pipeline của nhà cung cấp trung gian render. Điều này hoạt động cho đại đa số workload và là mô hình đứng sau hầu hết cloud render farm thương mại.
Trong Model B, nhà cung cấp hạ tầng cung cấp phần cứng, OS, mạng, và lớp cache, nhưng không bao giờ giữ vật liệu xác thực của khách cho cloud file-streaming platform hay dữ liệu nguồn của dự án. Khách sign in vào cloud platform trên mỗi node, đúng như họ đang ngồi trên workstation của mình. Project file stream từ cloud của khách. Render ghi lại về cloud của khách. Vai trò của nhà cung cấp giới hạn ở lớp phần cứng và pipeline.
Điều này quan trọng vì ba lý do:
- Hợp đồng: Khi downstream client của khách có NDA hay master service agreement hạn chế nơi credentials và source file có thể được giữ, Model B giữ nhà cung cấp ra khỏi phạm vi các hạn chế đó. Khách không cần đàm phán nhà cung cấp rendering vào chuỗi hợp đồng không được thiết kế cho nó.
- Audit: Khi khách cần chứng minh với security auditor rằng rendering pipeline của họ không lộ credentials cho bên thứ ba, Model B cho họ câu trả lời sạch. Nhà cung cấp có thể xuất trình tài liệu phần cứng, mạng, và vận hành; khách xuất trình chuỗi credentials.
- Đóng engagement: Vì nhà cung cấp chưa bao giờ giữ credentials, việc dọn dẹp cuối engagement đơn giản hơn. Khách revoke cloud session của họ; nhà cung cấp wipe cache, reimage các node, và cung cấp xác nhận bằng văn bản rằng cache và node image đã bị phá huỷ. Không có bước rotation credentials nào cho nhà cung cấp chứng nhận vì chưa bao giờ có credentials nào được giữ.
Model B không hợp với tất cả. Nó đặt đội operations của khách vào trách nhiệm về vòng đời credentials trên mỗi node — hai mươi lần rotation cần phối hợp nếu secret rotate hàng tháng. Đội đã có practice đó thấy sự đánh đổi chấp nhận được. Đội chưa có thường ở lại Model A managed rendering.
Tích hợp cloud file-streaming
Trong các cấu hình đang thảo luận, project asset của khách sống trong một cloud file-streaming platform — một dịch vụ expose project tree cloud-backed của họ như một filesystem ảo trên mỗi node. Artist mount project; node đọc file theo nhu cầu; platform xử lý backing storage, versioning, và cross-region replication.
Chúng tôi tích hợp với cloud file-streaming platform tổng quát theo lựa chọn của khách. Platform thấy sự kiện sign-in từ mỗi node sử dụng tài khoản của khách; client platform trên node mount project tree tại một path đã biết; DCC application của khách mở file từ path đó đúng như trên workstation local. Cloud platform không cần biết node là một phần của render cluster.
Điều thay đổi khi điều này được kết nối vào cluster 20 node là access pattern. Một artist trên một workstation kéo một project file mỗi lần, theo nhu cầu, khi họ làm việc. Hai mươi render node mở cùng scene cùng lúc cho một frame range tạo ra một burst đồng bộ cloud read cho cùng asset. Không có cache, mỗi node kéo mỗi texture, mỗi simulation đã cache, mỗi dependency file, song song — vừa lãng phí bandwidth quốc tế vừa chậm trên frame đầu tiên của mỗi range.
Đó là lý do shared cache tồn tại. Chúng tôi nói về nó chi tiết ở phần tiếp theo, nhưng tích hợp với cloud file-streaming là lý do nó phải tồn tại. Asset pull từ cloud được tập trung qua cache box một lần, sau đó phân phối cho tất cả hai mươi node qua LAN. Cloud platform không bao giờ thấy hai mươi fetch đồng thời cho cùng một texture — nó thấy một fetch, cộng với warm SMB read bên trong mạng của chúng tôi.
Chi tiết thực tế còn lại là write-back. Khi một frame render xong, node ghi output về cloud file-streaming platform — qua tài khoản của khách. Đội của khách tại văn phòng từ xa thấy các frame xuất hiện trong project tree theo thời gian thực. Không có bước upload thủ công, không có transfer qua trung gian nhà cung cấp; cloud platform xử lý round trip.
Kiến trúc shared cache
Shared cache là một trong hai hoặc ba lựa chọn kiến trúc mà nếu làm sai sẽ âm thầm xói mòn giá trị cluster. Chúng tôi đã làm sai trong các triển khai trước. Pattern trụ vững qua nhiều build là pattern cố ý bảo thủ.
Một edge-and-cache box duy nhất chạy Ubuntu 22.04 LTS, với một SATA SSD 8 TB duy nhất được format ext4 và expose cho cluster qua Samba SMB3. Cache mount xuất hiện trên mỗi render node tại một path cố định (ví dụ \\cache.lan\proj). Khi một node mở project file qua cloud file-streaming client, file stream qua local cache; các lần đọc sau đó của cùng file trên bất kỳ node nào đều truy cập SSD trực tiếp qua LAN.
Có ba lựa chọn cố ý trong đoạn đó.
Thứ nhất, một cache duy nhất, không phải per-node cache. Phiên bản kiến trúc trước đó lưu cache material trên từng node. Với hai mươi node 5090, điều đó có nghĩa là tới 200 TB storage dư thừa cần quản lý, và hai mươi cache state riêng biệt để debug khi có gì đó phân kỳ. Gộp về một shared cache duy nhất giảm storage footprint xuống hệ số hai mươi và biến cache state thành một artifact duy nhất mà đội operations có thể introspect.
Thứ hai, một SSD duy nhất trên ext4, không phải RAID 10 với LUKS trên XFS. Kế hoạch trước đó yêu cầu cache sống trên RAID 10 array với LUKS at-rest encryption trên XFS. Kế hoạch đó được over-engineer so với phần cứng thực tế chúng tôi triển khai — một SSD, một filesystem, một mount. Chúng tôi loại bỏ lớp RAID, loại bỏ LUKS, và dùng ext4 vì cache không phải nguồn sự thật cho dữ liệu project. Cloud của khách mới là nguồn sự thật. Nếu cache drive hỏng, chúng tôi thay và re-warm từ upstream; chúng tôi không cần redundancy ở lớp cache vì đã có redundancy ở lớp cloud. (At-rest encryption nằm ngoài phạm vi deal này nhưng có sẵn như một engagement riêng khi downstream client yêu cầu.)
Thứ ba, pre-warm cache trước ngày render đầu tiên. Đây là bài học chúng tôi học theo cách khó. Vào D-Day, mỗi cache miss là lần đọc tốn kém nhất trong cluster — nó đi qua international link, pull từ cloud của khách, và ghi vào local SSD trước khi renderer có thể consume. Pre-warming — một lần walk có cấu trúc qua asset tree của dự án vào ngày trước khi production bắt đầu — chuyển D-Day read từ cold cloud pull thành warm SMB read. Chúng tôi nay lên kế hoạch cửa sổ pre-warm vào mọi engagement dedicated cluster.
Bên trong cơ sở, mỗi node mount cache tại cùng path cố định (\\cache.lan\proj) qua SMB3 trên LAN local. Vì traffic trong cơ sở không đi qua WireGuard tunnel, MSS clamping không áp dụng ở đây và link chạy ở tốc độ gigabit Ethernet đầu cuối. Cache mount path giống hệt trên mọi node, đơn giản hoá cấu hình render manager của khách — cùng scene file path giải quyết cùng cách trên mọi thành viên của pool.
Tối ưu mạng xuyên biên giới
Transport layer là nơi cluster xuyên biên giới cảm giác liền mạch hay cảm giác hỏng. Hành vi mặc định của TCP/IP, IP-fragmentation, và DNS-over-VPN sai một cách tinh tế cho tunnel mã hoá đường dài mang SMB và remote desktop. Tuning kernel và cấu hình mạng không phải tuỳ chọn; đó là sự khác biệt giữa cluster hoạt động và một cluster bí ẩn drop large packet.
WireGuard, hub-and-spoke. Mỗi artist kết nối từ workstation qua WireGuard client tới hub tại cơ sở cluster. Tất cả traffic giữa artist và cluster được mã hoá đầu cuối. Chúng tôi cố ý dùng một công nghệ VPN thay vì trộn protocol; kết hợp IPSec cho một vai trò và VPN khác cho vai trò khác tạo thêm bề mặt vận hành mà không cải thiện bảo mật.
TCP BBR. Congestion control mặc định của Linux (CUBIC) được thiết kế cho link độ trễ thấp với mất gói nhẹ. Link ISP công cộng đường dài mang traffic mã hoá trông rất khác — độ trễ vừa phải, jitter thỉnh thoảng, và loss pattern bất đối xứng. BBR liên tục tạo throughput sử dụng được nhiều hơn CUBIC trên những link này, đặc biệt khi link được chia sẻ với traffic internet khác của khách. Chúng tôi dùng BBR stock của kernel (BBR v1); BBRv3 mới hơn không được triển khai trong build này, và phiên bản stock ổn định với chúng tôi.
TCP MSS clamping. Đây là nguồn phổ biến nhất của phàn nàn "cluster hoạt động, trừ file lớn". Khi traffic đi qua tunnel làm giảm MTU hiệu dụng, gói lớn bị fragment (chậm) hoặc bị drop âm thầm (tệ hơn). Gói nhỏ và ping vẫn chạy tốt, khiến vấn đề khó chẩn đoán. Fix là clamp TCP MSS trên WireGuard router để TCP negotiate kích thước packet vừa vặn trong tunnel. Sau khi áp dụng, TLS handshake, RDP session, và SMB large-file read ngừng treo.
dnsmasq với interface VPN được liệt kê. Một bẫy tinh tế: dnsmasq phải liệt kê tường minh WireGuard interface (ví dụ wg0) trong cấu hình, ngay cả khi client query địa chỉ .lan riêng. Không có nó, DNS lookup qua tunnel timeout — nhưng ping vẫn chạy vì ping không đi qua DNS. Điều này tạo ra một số session chẩn đoán gây nhầm lẫn nhất chúng tôi đã chạy, vì mọi bài test khác đều trông ổn.
chrony cho NTP. Đồng bộ thời gian nghe có vẻ nhỏ nhặt nhưng quan trọng với render manager (Deadline đánh timestamp job), tương quan log trên cluster, và mọi auth token có thành phần thời gian. chrony xử lý clock drift qua link độ trễ cao tốt hơn ntpd cũ; chúng tôi chạy nó trên edge box và để mỗi node sync với nó.
Hiệu ứng kết hợp của những lựa chọn này là một tunnel cảm giác như LAN cho hầu hết workload và suy giảm duyên dáng khi đường công cộng bị tắc nghẽn bất thường. Phần tiếp theo nói về việc chạy công việc 3D qua tunnel đó trông như thế nào trong thực tế.
Moonlight và Sunshine cho remote desktop
Remote desktop là lớp artist trải nghiệm trực tiếp nhất. Nếu lớp đó cảm giác chậm hay giật, thì không quan trọng renderer nhanh đến đâu — bàn tay của artist chậm, và engagement suy giảm.
Chúng tôi dùng Moonlight (client) và Sunshine (host trên mỗi node) cho remote desktop. Sự kết hợp dùng NVENC hardware encoder của NVIDIA trên RTX 5090 để encode frame buffer theo thời gian thực, sau đó stream tới workstation của artist. Vì encoding xảy ra trên GPU đã ở trong node, không có tranh chấp với renderer, và độ trễ thêm vào bởi remote desktop bị chi phối bởi network round trip — không phải bởi giai đoạn encoding.
Với công việc viewport 3D, điều này quan trọng theo cách mà remote desktop truyền thống không có. Protocol cũ hơn — RDP, VNC, Microsoft remote desktop tiêu chuẩn — được thiết kế cho workload văn phòng. Chúng xử lý text, dialog, và cửa sổ thay đổi chậm tốt, nhưng sụp đổ trên full-screen 3D viewport khi turntable preview. Moonlight + Sunshine xử lý frame buffer như video — đúng model cho công việc 3D.
Chúng tôi có test quality gate chạy trước khi bàn giao node cho artist — gọi không chính thức là "Test 8" — thực hiện một chuỗi thao tác viewport xác định dưới tải và xác nhận trải nghiệm remote desktop đáp ứng baseline. Nếu node fail test, chúng tôi hoặc debug encode pipeline hoặc kéo node ra khỏi rotation cho đến khi giải quyết. Chúng tôi chạy test này khi bắt đầu mỗi engagement và sau bất kỳ lần reimage node nào.
Parsec là fallback khả thi khi Sunshine có vấn đề host-specific. Chúng tôi đã ship một số lượng nhỏ node trên Parsec khi Sunshine không thể cấu hình đáng tin cậy; trải nghiệm artist tương tự. Chúng tôi không chuẩn hoá trên nó vì mô hình account-based, cloud-coordinated không phù hợp với xử lý credentials Model B sạch như Sunshine self-hosted.
Chúng tôi đã xem xét các tuỳ chọn remote desktop khác trong lúc lên kế hoạch ban đầu và đã rút lui — các tool remote desktop tổng quát không có GPU encode, và một thay thế open-source không đáp ứng quality gate của chúng tôi trên full-screen 3D viewport. Nguyên tắc quan trọng: với GPU cluster node, hardware-encoded streaming là mô hình duy nhất trụ vững ở quy mô.
Kế hoạch capacity và reserved floor
Cấu hình 20 node trong cẩm nang này là reserved dedicated slice của fleet rộng hơn của Super Renders Farm, được tách ra trong suốt thời gian engagement. Reserved có nghĩa là các node không được chia sẻ với managed-service pool, không được co-schedule với tenant khác, và không bị tính phí theo frame — khách trả cho slice như một chi phí vận hành cố định và có quyền kiểm soát độc quyền các node đó từ kickoff đến teardown.
Sizing slice ở hai mươi node là lựa chọn có chủ ý. Dưới mười node, cluster không tự biện minh diện tích kiến trúc so với managed render farm — con đường SaaS đơn giản và kinh tế hơn. Trên ba mươi, lớp cache cần re-architect (nhiều cache box, regional cache) và mô hình vận hành thay đổi hình dạng. Hai mươi là dải mà một edge-and-cache box duy nhất, một WireGuard hub duy nhất, và một Windows image đồng nhất trụ vững sạch — và nơi đội creative mười đến hai mươi artist có đủ node để frame tiếp tục chạy trong crunch mà không có thời gian idle trong steady-state.
Vì Super Renders Farm vận hành fleet đáng kể ngoài dedicated slice này, headroom để scale up tồn tại khi engagement cần nó. Thêm reserved node bổ sung trong cùng cơ sở là thay đổi cấu hình, không phải chu kỳ procurement. Khách chạy engagement nhiều tháng thường khoá size slice khi kickoff và re-scope tại ranh giới quý dựa trên nhu cầu thực tế so với kế hoạch ban đầu.
Network segmentation
Network segmentation trong cluster như này không phải tuỳ chọn. Khách vận hành trên hạ tầng của nhà cung cấp, nhưng khách không bao giờ được phép thấy mạng rộng hơn của nhà cung cấp — không NAS của nhà cung cấp, không interface admin router, không tenant nào khác. Tương tự, hệ thống nội bộ của nhà cung cấp không bao giờ được lộ với workload của khách.
Chúng tôi triển khai segmentation theo hai tier.
Tier 1 — edge firewall. Edge-and-cache box chạy ufw (uncomplicated firewall) ở default-deny inbound. Chỉ WireGuard UDP port (51820) được expose ra internet công cộng. SSH, SMB, DNS, NTP, và bất kỳ service nào khác chạy trên edge đều bound vào internal interface và không thể truy cập từ bên ngoài cluster. Forwarding rule cho phép packet giữa WireGuard interface và cluster LAN nhưng không giữa một trong hai với các mạng nội bộ khác của nhà cung cấp. Forward stance mặc định là drop trừ khi được permit tường minh.
Tier 2 — host firewall trên mỗi node. Mỗi render node có cấu hình Windows firewall riêng phản ánh edge stance — chấp nhận inbound từ cluster IP cho các service cluster cần (SMB, remote desktop, render manager) và drop mọi thứ khác. Đây không phải dư thừa; đây là defense in depth. Nếu một node bị misconfigure hoặc compromised, host firewall vẫn là hàng rào.
Nguyên tắc đằng sau cả hai tier là least privilege: khách và các node chỉ nên thấy nhóm node và không gì khác. Chúng tôi không cấp route tổng quát cho khách vào mạng nội bộ của nhà cung cấp. Tunnel của khách kết thúc tại edge box; edge box route chỉ vào cluster LAN; cluster LAN route chỉ giữa các thành viên cluster.
Trong thực tế, khách không thể ping hay scan hệ thống khác của nhà cung cấp dù muốn. Không có shared management plane, không có shared monitoring path lộ tenant khác.
Bài học rút ra
Đây là năm bài học vận hành mà trên mỗi dedicated cluster đã dựng, hoặc đã tiết kiệm cho chúng tôi nhiều giờ debug hoặc — khi quên áp dụng — đã tốn nhiều giờ debug.
1. Bẫy routing gateway dual-home. Khi edge box có hai network interface (một public, một LAN), thứ tự operations quan trọng. Route LAN phải được cấu hình trước khi default route được thay đổi. Nếu bạn đổi default route trước rồi mới thêm route LAN, SSH session bạn dùng để đăng nhập có thể drop ngay khi default route thay đổi, và bạn có thể bị khóa ra khỏi box. Fix là thủ tục, không phải kỹ thuật: luôn cấu hình internal route trước, validate chúng, và chỉ sau đó mới chạm vào default route.
2. WireGuard và DNS. dnsmasq phải liệt kê tường minh mọi interface nó nên lắng nghe, bao gồm WireGuard interface. Nếu bạn chỉ liệt kê LAN interface, DNS lookup từ VPN client timeout — nhưng ping response vẫn chạy vì ping không đi qua DNS. Đây là một trong những failure mode chẩn đoán gây nhầm lẫn nhất chúng tôi gặp. Fix là một dòng trong cấu hình dnsmasq, nhưng bạn phải biết để tìm nó.
3. TCP MSS clamping qua tunnel không phải tuỳ chọn. TLS handshake, RDP session, SMB large-file read — bất cứ thứ gì muốn gửi gói lớn — sẽ drop âm thầm nếu MSS không được clamp. Triệu chứng đầu tiên thường là "Moonlight chạy được mười giây rồi đơ" hay "SMB list được thư mục nhưng không đọc được file lớn hơn 1 MB". Fix là một iptables rule trên WireGuard host. Áp dụng trước khi bàn giao cluster.
4. Sizing storage đúng, đừng over-engineer. Phiên bản trước của kiến trúc này quy định RAID 10 với LUKS encryption trên XFS. Phần cứng cache chúng tôi triển khai là một SSD duy nhất. Chúng tôi loại bỏ lớp RAID, loại bỏ lớp LUKS, và dùng ext4 — vì cache không phải nguồn sự thật, cloud platform mới là. Đánh đổi redundancy trên giấy ở lớp cache lấy redundancy thực tế ở lớp cloud là quyết định đúng. Bài học là thiết kế storage xung quanh những gì dữ liệu thực sự cần, không phải xung quanh những gì cảm giác an toàn trong tài liệu kế hoạch.
5. Pre-warm cache. Vào D-Day, mỗi cache miss tốn international link và cloud platform một round trip. Giờ sản xuất đầu tiên trên cold cache cảm giác chậm dù mọi thứ khác được cấu hình đúng. Chúng tôi nay lên kế hoạch cửa sổ pre-warm vào mỗi engagement — thường một hoặc hai ngày trước khi production bắt đầu. Artist không thấy pre-warm; họ thấy một cluster đã cảm giác nhanh trên frame đầu tiên.
Đây là bài học vận hành, không phải kiến trúc. Chúng sống trong deployment checklist, không phải tài liệu kiến trúc. Nhưng chúng phân biệt một cluster hoạt động về lý thuyết với một cluster trụ vững dưới tải production thực tế. Các pattern nhỏ hơn được áp dụng theo từng engagement — năm bài trên là những bài xuất hiện trên mọi deployment.
Kết luận
Một dedicated render farm GPU 20 node xuyên biên giới là kiến trúc đúng khi kiểm soát IP là hợp đồng, engagement nhiều tháng, workflow cần cấu hình tuỳ chỉnh, và xác thực bring-your-own-cloud không thương lượng. Ngoài những điều kiện đó, managed render farm gần như luôn là câu trả lời tốt hơn — sự phức tạp kiến trúc ở đây không tự biện minh với công việc theo dự án hay với đội nhóm không có bộ phận operations chuyên biệt.
Khi điều kiện áp dụng, các pattern được trình bày ở đây — credentials Model B, shared cache trên ext4, WireGuard hub-and-spoke transport, BBR với MSS clamping, Moonlight + Sunshine cho remote desktop, two-tier firewalling — là những gì chúng tôi triển khai mặc định. Chúng không phải pattern duy nhất hợp lệ, nhưng là những pattern đã trụ vững qua các deployment.
Đội đứng sau Super Renders Farm vận hành cả thuê render farm managed lẫn triển khai dedicated cluster — bao gồm các cấu hình dedicated GPU cluster và topology xuyên biên giới được mô tả xuyên suốt cẩm nang này.
FAQ
Q: Triển khai cluster dedicated 20 node điển hình mất bao lâu? A: Tuỳ scope, sẵn có phần cứng tại cơ sở, và setup cloud file-streaming của khách, một engagement điển hình kéo dài từ vài tuần lead time cho phần cứng và cấp phát mạng, đến cửa sổ pre-warm một đến hai ngày trước khi production bắt đầu. Chúng tôi sizing timeline theo lịch production của khách chứ không theo template cố định.
Q: Nếu đội tôi trải khắp ba châu lục thì sao? A: Topology WireGuard hub-and-spoke scale tới các địa điểm khách bổ sung mà không thay đổi kiến trúc cluster. Mỗi artist từ xa chạy WireGuard client và kết nối tới cùng hub tại cơ sở cluster. Độ trễ từ mỗi vùng được xác định bởi đường internet công cộng giữa vùng đó và hub; theo kinh nghiệm của chúng tôi BBR và MSS clamping tạo ra sự khác biệt giữa có thể dùng và không thể dùng trên những đường đó.
Q: Tôi có thể xem cluster từ phía mình trước khi cam kết engagement nhiều tháng không? A: Chúng tôi thường sắp xếp cửa sổ proof-of-concept trong cuộc trò chuyện scoping. Hình thức cụ thể tuỳ project của khách — đôi khi là một node remote-desktop session để test trải nghiệm artist, đôi khi là test render nhỏ để validate cache và tích hợp cloud file-streaming. Điều khoản cụ thể là thảo luận kinh doanh; liên hệ đội sales của chúng tôi để bàn xem cái gì phù hợp với timeline của bạn.
Q: An ninh dữ liệu xử lý thế nào khi engagement kết thúc? A: Vì Model B giữ credentials khách ngoài tay chúng tôi, việc đóng engagement tập trung vào dọn dẹp phần cứng và cache. Chúng tôi wipe SMB cache, reimage mỗi node từ baseline sạch, và cung cấp xác nhận bằng văn bản rằng cache và node image đã bị phá huỷ. Khách revoke cloud file-streaming session của họ, nằm ngoài hệ thống của chúng tôi. Ngôn ngữ hợp đồng cụ thể (NDA, SLA, nội dung thư xác nhận) được đội sales của chúng tôi xử lý.
Q: Nếu tôi cần hơn 20 node thì sao? A: Cấu hình 20 node là hình thức phổ biến nhất chúng tôi triển khai, nhưng kiến trúc scale vượt nó. Fleet lớn hơn được thêm vào trong cùng cơ sở — reserved node bổ sung feed vào cùng WireGuard hub, cùng SMB3 cache, và cùng Windows image đồng nhất. Giới hạn thực tế thường là cache bandwidth: một edge-and-cache box duy nhất có giới hạn SMB read ceiling, và ở fleet size rất lớn bản thân kiến trúc cache cần được re-think (nhiều cache box, regional cache). Chúng tôi thảo luận những lựa chọn thiết kế này theo từng engagement.
Q: Tôi có thể đem license Cinema 4D, Redshift, hay DCC tool khác của tôi vào không? A: Mô hình license — bring-your-own-license hay nhà cung cấp cấp — là quyết định kinh doanh phụ thuộc vào DCC cụ thể và inventory license hiện có của khách. Một số cấu hình hoạt động tốt với license của khách; số khác đơn giản hơn với nhà cung cấp cấp. Chúng tôi giải quyết điều này trong cuộc trò chuyện scoping. Liên hệ đội sales của chúng tôi để biết chi tiết.
Q: Cloud storage từ nhà cung cấp EU so với US được xử lý thế nào? A: Cloud file-streaming platform là lựa chọn của khách. Cluster của chúng tôi tích hợp với bất kỳ platform nào có thể chạy sign-in client trên Windows và expose project tree của khách như filesystem được mount. Vị trí địa lý của cloud upstream ảnh hưởng đến độ trễ quốc tế của đường customer-to-cluster — đó là lý do chúng tôi đề xuất WireGuard hub-and-spoke transport và cấu hình được tune BBR cho setup xuyên quốc gia. Chúng tôi không host cloud platform; nó vẫn dưới tài khoản của khách.
Q: Điều gì xảy ra nếu WireGuard tunnel rớt? A: WireGuard tự động thiết lập lại session khi mạng nền hồi phục; remote-desktop session của khách có thể tạm dừng ngắn trong lúc re-handshake. Nếu tunnel rớt trong khi render đang chạy, bản thân render tiếp tục chạy trên node (nó không phụ thuộc vào tunnel cho công việc đang xử lý), nhưng write-back về cloud sẽ queue cho đến khi tunnel được khôi phục. Chúng tôi monitor tunnel health từ edge box và alert khi có downtime kéo dài.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



