
レンダーファームの仕組み:3Dアーティストのための技術ガイド
概要
はじめに
レンダーファームが存在するのは、単一のワークステーションには明確な限界があるからです。500フレームのアニメーションを1フレームあたり20分でレンダリングすると、1台のマシンではほぼ1週間かかります。同じジョブを100台のマシンに分散すれば、2時間以内に完了します。計算は単純ですが、その裏にあるエンジニアリングは決して単純ではありません。
私たちは20,000以上のCPUコアと、NVIDIA RTX 5090を搭載した専用GPUフリートを運用するレンダーファームを運営しています。毎日、V-Ray、Corona、Arnold、Redshift、Cycles、その他のエンジンを使用した何百ものジョブを処理しています。このガイドでは、シーンファイルをアップロードしてから完成したフレームをダウンロードするまでの間に実際に何が起きているかを説明します。キューイングシステム、ファイル配信、エラー処理、そして分散レンダリングを大規模に安定稼働させるためのインフラ設計について解説します。
レンダーファームの概念自体が初めての方は、レンダーファームとは何かを解説するガイドで基本を確認できます。本記事では、技術的な仕組みをより深く掘り下げます。
レンダージョブを送信すると何が起きるか
送信プロセスには、多くのアーティストが想像する以上のステップが含まれています。ワークステーションから最初のピクセルがレンダリングされるまでの流れを見ていきましょう。
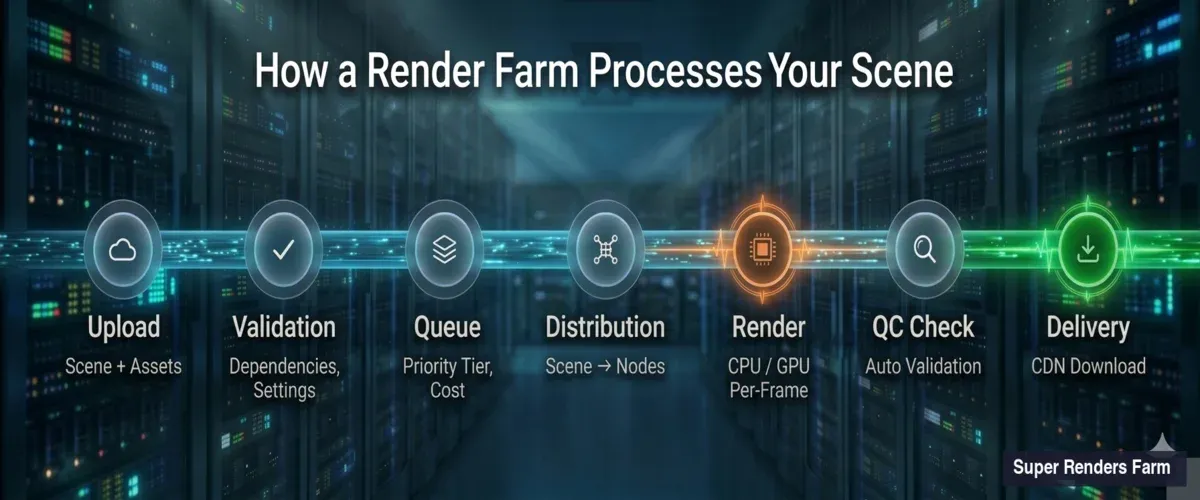
シーンアップロードから検証、キューイング、分散、レンダリング、品質チェック、最終デリバリーまでの7段階を示すレンダーファームパイプライン
シーンのアップロードと解析。 .max、.blend、.maなどのシーンファイルを送信すると、ファームの取り込みシステムがそれを展開し、すべての依存ファイル(テクスチャ、キャッシュ、プロキシメッシュ、HDRIマップ、Plugin Asset)をカタログ化します。依存ファイルの欠落は、レンダリング失敗の最も一般的な原因です。私たちのシステムでは、ジョブがキューに入る前に欠落ファイルを検出するため、レンダリング時間を無駄にする前にパスを修正できます。
レンダリング設定の検証。 ファームは埋め込まれたレンダリング設定を読み取ります。エンジンの種類、バージョン、解像度、フレーム範囲、出力形式、サンプリングパラメータなどです。これらを利用可能なノード構成と照合します。V-Ray 7を指定しているのにシーンがV-Ray 6形式で保存されている場合、レンダリング開始前にこの不一致を検出します。
コスト見積もり。 シーンの複雑さ、解像度、サンプル数、および類似ジョブの履歴データに基づいて、時間とコストの見積もりを生成します。これは推測ではありません。十分な数のジョブを処理してきた実績から、ほとんどの標準的なシーンに対して妥当な精度でレンダリング時間を予測する統計モデルを構築しています。
ジョブキューイングと優先度システム
検証が完了すると、ジョブはキューに入ります。レンダーファームがこのキューをどのように管理するかによって、フレームが2時間で届くか12時間かかるかが決まります。
優先度ティア。 ほとんどのファームは複数の優先度レベルを提供しています。優先度の高いジョブはより多くのノードに同時にアクセスでき、優先度の低い作業をプリエンプト(一時停止)できます。私たちのファームでは、標準優先度と高優先度の差は大きく、200フレームのジョブが標準優先度では20ノード、高優先度では80ノードでレンダリングされることがあります。
フェアスケジューリング。 キューマネージャーは、すべてのアクティブユーザー間でリソースを均等に配分します。高優先度であっても、単一のジョブがファーム全体を独占することはありません。ファームに400台の利用可能なCPUノードがあり、3つの高優先度ジョブが同時に実行されている場合、スケジューラーはジョブサイズ、推定完了時間、ユーザーティアに基づいてノードを比例配分します。
プリエンプションとリキューイング。 高優先度のジョブが到着し、ファームが全能力を使用中の場合、スケジューラーは優先度の低いジョブのフレームを一時停止し、それらのノードを再割り当てすることがあります。一時停止されたフレームは自動的にキューに再投入されます。作業は失われませんが、優先度の低いジョブの完了には時間がかかります。
ノード障害の検出。 レンダーノードが応答しなくなった場合(ハードウェア障害、ドライバクラッシュ、ネットワークタイムアウト)、キューマネージャーは数秒以内に検出し、処理中のフレームを正常なノードに再割り当てします。これは透過的に行われるため、出力に障害の影響が現れることはありません。
シーン配信:ファイルがレンダーノードに届くまで
ノードがアニメーションのフレーム47をレンダリングするには、シーン全体(ジオメトリ、テクスチャ、キャッシュ、設定)が必要です。このデータを効率的に移動させることは、インフラの核心的な課題です。
ネットワークファイルシステム。 ほとんどのプロダクションレンダーファームは、シーンファイルを各ノードに個別にコピーするのではなく、高速共有ストレージ(NFS、SMB、または独自の分散ファイルシステム)を使用します。シーンは中央ストレージクラスタに置かれ、レンダーノードはネットワーク経由でアクセスします。これにより、50GBのシーンを100ノードに順番にコピーするボトルネックを回避できます。
キャッシングとローカリティ。 高度なファームは、頻繁にアクセスされるAssetをレンダーノードのローカルにキャッシュします。今日の3つのジョブが同じHDRIパックや同じV-Rayマテリアルライブラリを使用する場合、それらのファイルが既にキャッシュされているノードはネットワーク転送をスキップします。これにより、繰り返し使用されるテクスチャのフレームあたりの起動時間が数分から数秒に短縮されます。
テクスチャストリーミング。 大量のテクスチャセットを持つシーン(4K以上のマテリアルライブラリを使用する建築ビジュアライゼーションで一般的)では、すべてを事前にロードするのではなく、必要に応じてテクスチャをストリーミングするファーム構成もあります。レンダリングエンジンがテクスチャタイルを要求すると、ストレージシステムがそれを配信し、ノードは後続フレーム用にローカルにキャッシュします。タイルあたりのレイテンシはわずかに増加しますが、初期ロード時間は大幅に短縮されます。
レンダリングフェーズ:CPUとGPUの処理
シーンがロードされ、フレームが割り当てられると、実際のレンダリングが始まります。ファームがCPUとGPUのリソースをどのように割り当てるかは、実際のパフォーマンスとコストのトレードオフを反映しています。

CPU レンダリングとGPUレンダリングの比較。速度、メモリ、最適な用途、対応ソフトウェア、ハードウェアスペックの違いを表示
CPUレンダリング。 CPUベースのエンジン(V-Ray CPU、Corona、Arnold CPU)は、ノード上のすべての利用可能なコアに作業を分散します。一般的なファームのCPUノードには44以上のコアと96~256GBのRAMが搭載されています。大容量のメモリプールにより、CPUノードはGPUのVRAMをオーバーフローさせるようなシーンも処理できます。ディスプレイスメントマップを使用した複雑な建築ビジュアライゼーションのインテリア、数百万の要素を含むパーティクルシミュレーション、高解像度キャッシュを使用したボリュメトリックエフェクトなどです。
私たちのファームでは、レンダリングジョブの約70%がCPUノードで実行されています。これは、プロフェッショナルレンダリングの主流である建築ビジュアライゼーションやVFXのプロダクションワークフローを反映しています。これらのシーンはメモリを大量に使用し、マルチコアCPUパフォーマンスに最適化されたV-RayやCoronaなどのエンジンを使用する傾向があります。
GPUレンダリング。 GPUベースのエンジン(Redshift、Octane、V-Ray GPU、Cycles with OptiX)は、最新グラフィックスカードの数千の並列コアを活用します。当ファームのGPUノードはNVIDIA RTX 5090(32GB VRAM)を使用しています。GPUレンダリングは、VRAMの制限内に収まるシーンではフレームあたりの処理が一般的に高速ですが、その制限は確実に存在します。テクスチャとジオメトリデータで40GBを必要とするシーンは、32GBのカードではアウトオブコアフォールバックなしにはレンダリングできず、パフォーマンスが低下します。
ハイブリッド割り当て。 一部のジョブは、CPUノードとGPUノードの両方に分割することで効果を発揮します。一般的なパターンとして、GPUノードがビューティパス(フレームあたりの処理は高速だがVRAMに制約あり)を処理し、CPUノードがVRAM容量を超えるボリュメトリックパスやパーティクルパスを処理します。ファームのジョブスケジューラーはこの分割をサポートし、異なるレンダーレイヤーを適切なハードウェアにルーティングします。
フレームの組み立てと品質チェック
フレームのレンダリングは作業の半分に過ぎません。ファームは出力品質の検証と、フレームを一貫したデリバリーパッケージに組み立てる必要もあります。
自動品質チェック。 各フレームのレンダリング後、ファームは基本的な検証を実行します。ファイルサイズが予想範囲内か(1バイトのPNGはレンダリングがサイレントに失敗したことを意味します)、解像度が仕様に一致するか、完全に黒いまたは完全に白いフレームがないか(ライトやマテリアルの欠落を示す一般的な指標)、出力形式が正しいかを確認します。これらのチェックに失敗したフレームは、別のノードで自動的に再レンダリングされます。
タイルベースレンダリングのフレームスティッチング。 一部のエンジンや構成では、単一の高解像度フレームをタイルに分割します。左上の4分の1をあるノードで、右上を別のノードでレンダリングするといった具合です。すべてのタイルが完了した後、ファームはそれらを最終的なフル解像度画像にスティッチングします。このアプローチは、1ノードあたり数時間かかるような超高解像度スチル(8K以上)に適しています。
出力デリバリー。 完成したフレームはファームの出力ストレージに書き込まれ、ダウンロード可能になります。CDNアクセラレーション付きのクラウドストレージを使用して、ダウンロード速度がファームのアップロード帯域幅にボトルネックされないようにしています。大規模なアニメーションシーケンス(数千のEXRファイル)には、一括ダウンロードオプションと、より高速な転送のためのシーケンス圧縮を提供しています。
レンダーファームのネットワークアーキテクチャ
レンダーノード、ストレージ、管理システムを接続するインフラは、ハードウェアそのものと同様に重要です。
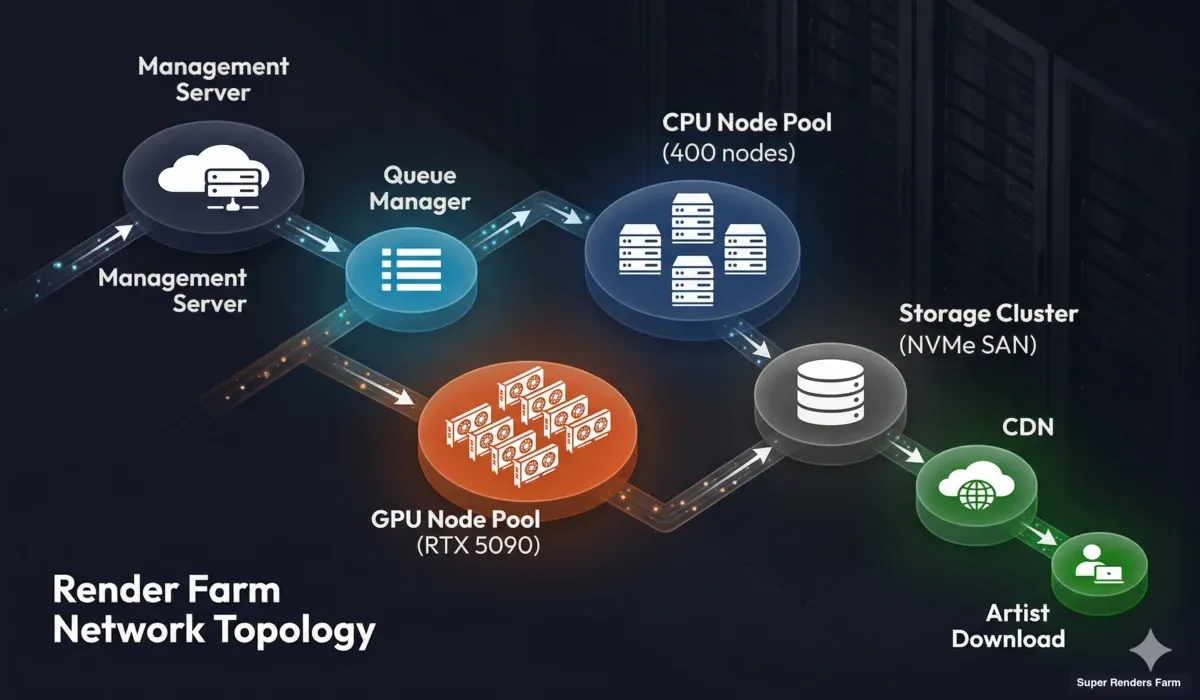
レンダーファームのネットワークトポロジ。管理サーバー、キューマネージャー、CPUおよびGPUレンダーノードプール、ストレージクラスタ、ユーザーへのCDNデリバリーを表示
管理レイヤー。 中央管理サーバーがすべてを統括します。ジョブの取り込み、キュー管理、ノードヘルスモニタリング、ユーザーとのコミュニケーションです。このサーバーは冗長化されています(フェイルオーバー対応)。これがダウンすると、ファーム全体がジョブの受付と処理を停止するためです。
レンダーノードネットワーク。 ノードは高帯域幅の内部ネットワークを通じて管理サーバーおよびストレージと通信します。最新のファームでは、通常10Gbpsイーサネット以上が使用されます。帯域幅が最も重要になるのは、シーン配信時(テクスチャのロード)とフレーム出力時(高解像度EXRファイルのストレージへの書き込み)です。
ストレージクラスタ。 中央ストレージは、すべてのレンダーノードが読み書きする共有リソースです。テクスチャタイルを要求する数百のノードからの同時読み取りと、レンダリングされたフレームを出力するノードからの同時書き込みを処理する必要があります。高性能ストレージアレイ(NVMeベースのSANまたは分散ファイルシステム)が不可欠です。ストレージシステムが遅いと、どれだけCPUやGPUのパワーがあっても克服できないボトルネックが発生します。
インターネット接続。 ファームの外部ネットワーク接続は、ユーザーがシーンをアップロードし、結果をダウンロードする速度を決定します。プロダクションファームでは、冗長化されたマルチギガビット接続が標準です。主要なユーザーベースへの地理的な近接性も重要です。米国のファームがヨーロッパのクライアントにサービスを提供する場合、ヨーロッパにポイントオブプレゼンスがある場合よりもレイテンシが高くなります。
モニタリングとエラー復旧
大規模運用では常に障害が発生します。数百台のノードを持つファームでは、毎日のハードウェアインシデントが想定されます。信頼性の高いファームとそうでないファームの違いは、障害の検出と対処の方法にあります。
ノードヘルスモニタリング。 すべてのレンダーノードは、定期的に管理システムにステータスを報告します(CPU温度、メモリ使用量、GPU使用率、ディスク容量、ネットワークスループット)。チェックインが途切れたノードは即座にフラグが立てられます。異常なパターン(温度上昇、スループット低下)を示すノードは、レンダリング中に障害が発生する前にプールから先行的に除外されます。
フレームレベルの復旧。 ノードがレンダリング中にクラッシュすると、処理中だったフレームは失敗としてマークされ、正常なノードに再割り当てされます。ファームは、どのフレームが正常に完了し、どのフレームが処理中または失敗したかを追跡します。この状態追跡により、連鎖的なノード障害が発生しても、フレームが失われたり重複したりすることはありません。
レンダリングエンジンのクラッシュ処理。 ハードウェア障害に加えて、レンダリングエンジン自体がクラッシュすることもあります。メモリ不足、シーンの要素の破損、エンジンのバグなどが原因です。ファームは、復旧可能なクラッシュ(より多くのRAMを持つ別のノードで再試行)と復旧不可能なクラッシュ(シーンファイル自体にすべてのノードをクラッシュさせるエラーがある)を区別します。設定された回数のリトライの後、ファームは無限にリトライするのではなく、診断情報とともにユーザーに障害を報告します。
データ整合性。 レンダリングされたフレームは書き込み時にチェックサムされます。ネットワークの不具合によりストレージへの転送中にフレームが破損した場合、チェックサムの不一致が自動再レンダリングをトリガーします。これはEXRファイルにとって特に重要で、1バイトの破損でもCompositing時に視覚的なアーティファクトが発生する可能性があります。
レンダーファームのソフトウェアスタック
これらすべてを調整するソフトウェアは、ハードウェアと同様に重要です。
レンダーマネージャー。 専用のレンダー管理ソフトウェアが、ジョブスケジューリング、ノード割り当て、ファーム管理を処理します。これらのシステムは、分散レンダリング特有の要求に合わせて設計されています。フレームレベルの依存関係追跡、ノードごとのエンジンバージョン管理、マルチユーザーリソース割り当てなどです。
シーン解析ツール。 ジョブがレンダーキューに入る前に、解析ツールがシーンファイルを解析して依存関係を特定し、リソース要件を見積もり、一般的なエラーをチェックします。これらのツールはエンジン固有です。V-Rayのシーンアナライザーは、Blender Cyclesのアナライザーとは異なる問題をチェックします。
バージョン管理。 プロダクションファームは、各レンダリングエンジンの複数のバージョンを同時に維持します。あるユーザーは古いプロジェクトにV-Ray 6を必要とし、別のユーザーはV-Ray 7を必要とすることがあります。ファームのソフトウェアインフラは、各ノードが割り当てられたジョブに対して正しいエンジンバージョンをロードし、異なるジョブがサイクルする際にバージョンを切り替えることを保証します。
モニタリングダッシュボード。 ファームのオペレーターは、ノードステータス、キューの深さ、アクティブジョブ、完了率、エラー頻度をリアルタイムで表示する「Render Dashboard (レンダーダッシュボード)」を使用します。これらのダッシュボードにより、問題への迅速な対応が可能になります。特定のノードグループでエラー率が急上昇した場合、オペレーターは数時間後に問題を発見するのではなく、即座に調査を開始できます。
フルマネージドファームとセルフサービスプラットフォームの違い
すべてのレンダーファームが同じ仕組みで動作するわけではありません。主な2つのカテゴリー、フルマネージドとセルフサービスでは、パイプラインの処理方法が異なります。
フルマネージドファーム(Super Renders Farmなど)は、技術スタック全体を管理します。シーンをアップロードし、設定を選択すれば、ファームがすべてを管理します。ソフトウェアのインストール、バージョン管理、Pluginの互換性、エラー復旧、出力デリバリーです。どのマシンにもリモート接続する必要はなく、インフラを管理する必要もありません。これは重要なポイントです。レンダリングエンジンの設定は複雑で、V-Rayだけでもファームの互換性に影響する数十のバージョン固有の設定があるためです。
セルフサービスまたはIaaSプラットフォームは、レンダリングソフトウェアがプリインストールされた仮想マシンを貸し出します。リモート接続して、自分でソフトウェアを設定し、レンダーキューを管理し、トラブルシューティングを行います。より多くのコントロールが得られますが、技術的な専門知識と時間の投資が大幅に必要になります。
詳細な比較については、マネージド vs DIYクラウドレンダリングガイドでトレードオフを解説しています。
レンダーファーム料金の裏にあるコスト構造
レンダーファームの仕組みを理解することは、何に対して料金を支払っているかを理解することでもあります。
リソースベースの料金。 ほとんどのファームは、消費したコンピュートリソースに基づいて課金します。CPUレンダリングではGHz時間、GPUではOBs(コンピュートユニット)です。料金シミュレーターなどのツールを使用して、事前にコストを見積もることができます。コストは、ジョブが使用するリソースに比例してスケールします。1ノードでの10分のフレームは、ファームに他のジョブが10件あっても1,000件あっても同じコストです。消費した分だけ支払います。
インフラのオーバーヘッド。 GHz時間あたりのレンダーファーム料金には、CPUを動かす電気代だけでなく、償却されるハードウェアコスト、ストレージインフラ、ネットワーク帯域幅、ソフトウェアライセンス(レンダリングエンジンのファームライセンスは高額です)、冷却、冗長化、そしてすべてを稼働させ続けるエンジニアリングチームの費用が含まれています。コストの相当部分は、このインフラを自分で管理する手間を省く、信頼性と利便性のレイヤーに充てられています。
優先度の倍率。 優先度が高いほどコストも高くなります。これは、より多くのノードに同時にアクセスでき、他のジョブがリソースを譲るためです。これは意図的なトレードオフであり、緊急の締め切りはプレミアムを正当化します。
包括的な料金の内訳については、レンダーファーム料金ガイドをご覧ください。
まとめ:レンダーファームパイプライン
送信からデリバリーまでの完全なパイプラインは以下の通りです。
- アップロード -- シーンファイルと依存ファイルをファームストレージに転送
- 検証 -- 依存関係の確認、レンダリング設定の検証、コスト見積もり
- キュー -- ジョブが優先度ベースのキューに入り、ノード割り当てを待機
- 分散 -- ネットワークストレージ経由で、割り当てられたレンダーノードにシーンデータを提供
- レンダリング -- CPUまたはGPUノードが割り当てられたフレームを並列処理
- 品質チェック -- 各フレームを検証(ファイルサイズ、解像度、コンテンツ)
- 組み立て -- フレームの整理、該当する場合はタイルのスティッチング
- デリバリー -- CDNアクセラレーション付きストレージ経由で完成フレームをダウンロード可能に
各ステップには障害モードがあり、各障害モードには自動復旧が備わっています。その結果、シーンファイルを、どんな単一ワークステーションでも達成できない速度でレンダリングされたフレームに確実に変換するシステムが実現しています。
FAQ
Q: レンダーファームが一般的なアニメーションジョブを処理するのにどれくらい時間がかかりますか?
A: フレームの複雑さと優先度レベルによります。V-Rayを使用した1080pの500フレーム建築ビジュアライゼーションアニメーションは、ファームでは通常2~6時間で完了しますが、ローカルでは3~7日かかります。GPUアクセラレーションジョブ(Redshift、Cycles)はフレームあたりの処理が高速な場合が多いですが、複雑なシーンではVRAMの制約を受けます。
Q: レンダリング中にレンダーノードがクラッシュした場合はどうなりますか?
A: ファームのキューマネージャーが数秒以内に障害を検出し、処理中のフレームを正常なノードに再割り当てします。フレームが失われることはありません。クラッシュの原因がシーンエラー(ハードウェアではなく)の場合、ユーザー側の問題としてフラグを立てる前に、別のノード構成で再試行します。
Q: ファームにレンダリングソフトウェアを自分でインストールする必要がありますか?
A: Super Renders Farmのようなフルマネージドファームでは、その必要はありません。互換性のために複数のバージョンを含む、サポートされているすべてのレンダリングエンジン(V-Ray、Corona、Arnold、Redshift、Cycles、その他)をノードフリート全体で維持しています。セルフサービスプラットフォームでは、ソフトウェアのインストールを自分で管理する必要がある場合があります。
Q: レンダーファームはローカルGPUのVRAMを超えるシーンを処理できますか?
A: はい。当ファームのCPUレンダーノードには96~256GBのRAMが搭載されており、ワークステーションのGPUでは処理しきれないシーンも扱えます。GPUに特化したエンジンの場合、当ファームのRTX 5090ノードは32GB VRAMを提供します。これはほとんどのデスクトップGPUよりも大容量です。それでも超過するシーンは、自動的にCPUノードにルーティングされます。
Q: ファームは異なるレンダリングエンジンのバージョンをどのように処理しますか?
A: プロダクションファームは、各エンジンの複数のバージョンを同時に維持しています。ジョブを送信すると、システムはシーンのエンジンバージョンを互換性のあるノードに一致させます。シーンをV-Ray 6で保存した場合、V-Ray 6のノードでレンダリングされます。設定を異なる解釈をする可能性のあるV-Ray 7ではありません。
Q: レンダーファームでシーンデータは安全ですか?
A: 信頼性の高いファームは、暗号化された転送(アップロードとダウンロードにTLS/SSL)、アクセス制御されたストレージ(ファイルは他のユーザーから隔離)、保持期間後のシーンデータの自動削除を使用しています。当ファームでは、シーンファイルはジョブ完了後、設定可能な保持期間を経て自動的にパージされます。
Q: レンダーファームに送信する際、どのファイル形式を使用すべきですか?
A: DCCのネイティブ形式(3ds Maxの場合は.max、Blenderの場合は.blend、Mayaの場合は.ma/.mb)を使用してください。出力形式は、Compositingワークフローの場合はEXR、デリバリーの場合はPNGを指定してください。常に画像シーケンスでレンダリングし、動画ファイルにはしないでください。フレームが失敗した場合、そのフレームだけを再レンダリングすれば済みます。
Q: レンダーファームはForest PackやScatterなどのPlugin依存をどのように処理しますか?
A: マネージドファームは、ノードフリート全体で一般的なPluginを維持しています。Forest Packを使用するシーンを送信すると、ファームはジョブに割り当てられたノードに正しいForest Packバージョンがインストールされていることを確認します。あまり一般的でないPluginの場合は、ジョブの実行前にファームが配備できるよう、事前の通知が必要な場合があります。
関連記事
- レンダーファームとは? -- レンダーファームの概念に関する基礎ガイド
- レンダーファーム料金ガイド -- 業界全体の料金モデルの仕組み
- クラウドレンダリング vs ローカルレンダリング -- ファームレンダリングとローカルレンダリングの比較
- Autodesk Knowledge Network — Distributed Rendering -- 3ds Max分散レンダリングの公式ドキュメント
- Blender Manual — Render Output -- Blenderレンダー出力の設定
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



