
Automatiser les transferts vers une render farm avec Python : guide paramiko et rsync
Aperçu
La partie la plus lente d'un rendu cloud n'est souvent pas le rendu lui-même. Pour un studio qui pousse un plan VFX multi-caméras ou un cache Houdini de 400 Go vers une render farm chaque nuit, le goulot d'étranglement, c'est le déplacement des données : envoyer le projet de façon fiable, puis récupérer les images finales avant que l'équipe arrive le matin. Faire cela à la main, à regarder une barre de progression à minuit, n'est pas une solution à l'échelle. L'automatiser par script l'est.
Ce guide porte sur l'automatisation de cette couche de transfert en Python. Nous exploitons Super Renders Farm, une render farm entièrement gérée, et « entièrement géré » a une signification précise dans le contexte de l'automatisation : vous ne vous connectez pas à distance aux machines, n'installez pas de logiciels et ne gérez pas les licences — la partie du pipeline que vous scriptez est donc celle que vous maîtrisez vraiment : les fichiers qui montent et les rendus qui redescendent. La surface de transfert est véritablement scriptable via SFTP, et Python est un outil de premier ordre pour la piloter. Notre propre documentation de transfert cite directement la bibliothèque paramiko de Python comme client pris en charge, aux côtés de rsync via SSH et de la ligne de commande sftp standard.
Nous serons tout aussi précis sur ce que vous ne pouvez pas automatiser depuis Python aujourd'hui, car un pipeline construit sur une fonctionnalité inexistante est un pipeline qui échouera dès sa première exécution sans surveillance. Si vous cherchez une vue d'ensemble conceptuelle — ce que signifient « headless » et « sans surveillance », comment préparer vos scènes pour le rendu en ligne de commande — c'est l'objet d'un guide compagnon distinct. Celui-ci reste au niveau du code, concentré sur la couche de transfert : paramiko, rsync, les clés SSH, les reprises, et un modèle de synchronisation nocturne que vous pouvez intégrer dans l'automatisation d'un studio.
Ce que vous pouvez automatiser en Python aujourd'hui
Il est utile de tracer la frontière avant d'écrire la moindre ligne de code. Sur une render farm gérée, certaines parties du pipeline sont entièrement scriptables, d'autres sont délibérément pilotées via une interface graphique, et une partie se situe entre les deux. Être honnête sur la distinction évite que votre automatisation échoue silencieusement.
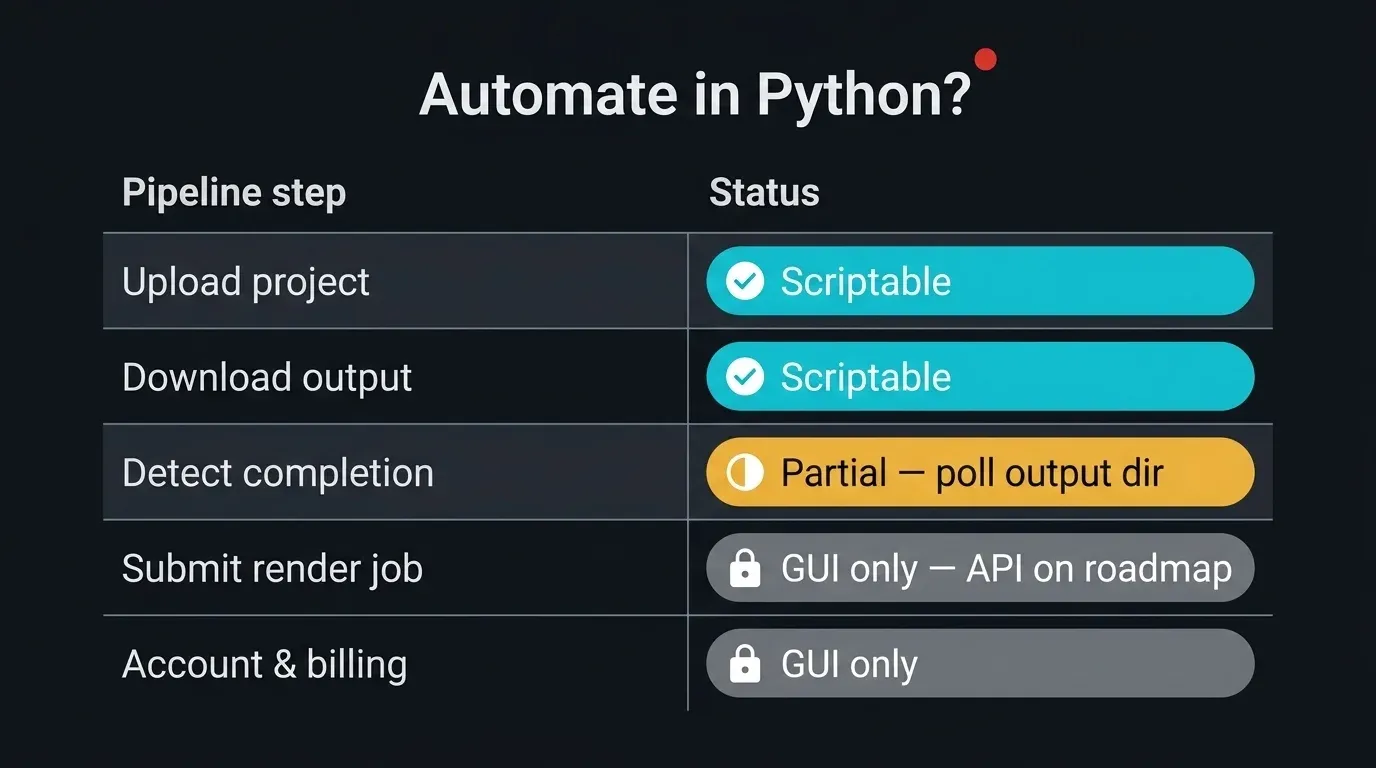
Diagramme matriciel indiquant quelles étapes du pipeline d'une render farm cloud gérée peuvent être automatisées en Python : Upload du projet (entièrement scriptable via paramiko, rsync, sftp), Téléchargement des sorties (entièrement scriptable), Détection de fin de job (partiel — interrogez le répertoire SFTP de sortie, pas d'API de statut), Soumission du job de rendu (interface graphique uniquement — formulaire web, Client App, ou plugin DCC), Gestion du compte et de la facturation (interface graphique uniquement), avec des colonnes de statut vert, orange et gris
- Envoyer un projet — entièrement scriptable. SFTP via
paramiko,rsync, ou des commandessftpscriptées fonctionnent tous contre notre serveur SFTP. C'est le cœur de ce qui suit. - Télécharger les images finales — entièrement scriptable. Les sorties arrivent dans un répertoire par job que vous pouvez récupérer avec les mêmes outils.
- Détecter la fin d'un job — partiel. Il n'existe pas d'API de statut publique à interroger. Ce que vous pouvez faire, c'est interroger le répertoire SFTP de sortie et surveiller l'apparition et la stabilisation des images. C'est une heuristique, pas un signal officiel, et nous la traitons comme telle ci-dessous.
- Soumettre un job de rendu — interface graphique aujourd'hui. La soumission s'effectue via le formulaire web, le SuperRenders Client App, ou un plugin de soumission par DCC. Une API REST publique pour la soumission de jobs, l'interrogation de statut et la récupération des sorties est sur notre feuille de route, mais aucun endpoint public n'est disponible pour une intégration directe à ce jour. Si votre pipeline est spécifiquement bloqué sur une API de soumission, contactez le support et partagez le cas d'usage — la feuille de route est façonnée par les besoins réels des pipelines.
- Gérer le compte, les crédits ou la facturation — interface graphique. Hors du périmètre de l'automatisation des transferts.
La surface automatisable se résume donc au transfert : envoyer le projet, récupérer les rendus, et combler l'écart en surveillant le répertoire de sortie. L'étape de soumission reste un transfert de contrôle délibéré, et nous le marquerons clairement dans le pipeline final plutôt que d'en faire semblant. Pour une présentation plus complète de ce qu'une render farm entièrement gérée expose ou non, notre guide sur ce qu'est une render farm entièrement gérée couvre ce modèle ; les nouveaux comptes peuvent partir de la procédure de démarrage.
Prérequis : accès SFTP, clés SSH et environnement Python
Trois éléments doivent être en place avant le premier upload scripté.
Accès SFTP, activé par compte. SFTP est activé sur demande pour chaque compte. Connectez-vous, recherchez « accès SFTP » dans les paramètres de votre compte et générez-y vos identifiants ; s'il n'est pas visible, demandez au support de l'activer. Vos identifiants comprennent un nom d'hôte de serveur (il varie selon la région et l'allocation de stockage, traitez-le donc comme une valeur lue depuis la configuration, jamais codée en dur), un nom d'utilisateur lié à votre compte, un mot de passe ou une clé SSH, et le port SFTP standard 22. Deux chemins sont importants : /uploads/<votre-dossier-projet>/ est votre zone d'écriture, et /output/<job-id>/ est l'endroit où les rendus finis apparaissent.
Une clé SSH, pas un mot de passe. Pour tout ce qui est automatisé, l'authentification par clé SSH est le bon choix — elle maintient les secrets hors de vos scripts et survit aux exécutions sans surveillance sans invite interactive. Générez une paire de clés moderne et enregistrez la moitié publique sur votre compte :
ssh-keygen -t ed25519 -C "pipeline@yourstudio.example"
# ajoutez le contenu de ~/.ssh/id_ed25519.pub dans
# superrendersfarm.com -> Paramètres -> SFTP -> Clés SSH
Une note sur la sécurité du compte : l'authentification à deux facteurs n'est pas actuellement prise en charge sur les comptes, donc pour SFTP le renforcement le plus efficace est une phrase secrète sur le fichier de clé associée à un agent SSH qui la conserve pour la session. La clé, plus la connaissance de sa phrase secrète, joue un rôle similaire à un second facteur — possession plus secret.
Un environnement Python avec paramiko. Tout ce qui suit utilise paramiko, l'implémentation SSH/SFTP standard en Python pur, et délègue à rsync pour les transferts incrémentiels importants.
python3 -m venv .venv && source .venv/bin/activate
pip install paramiko
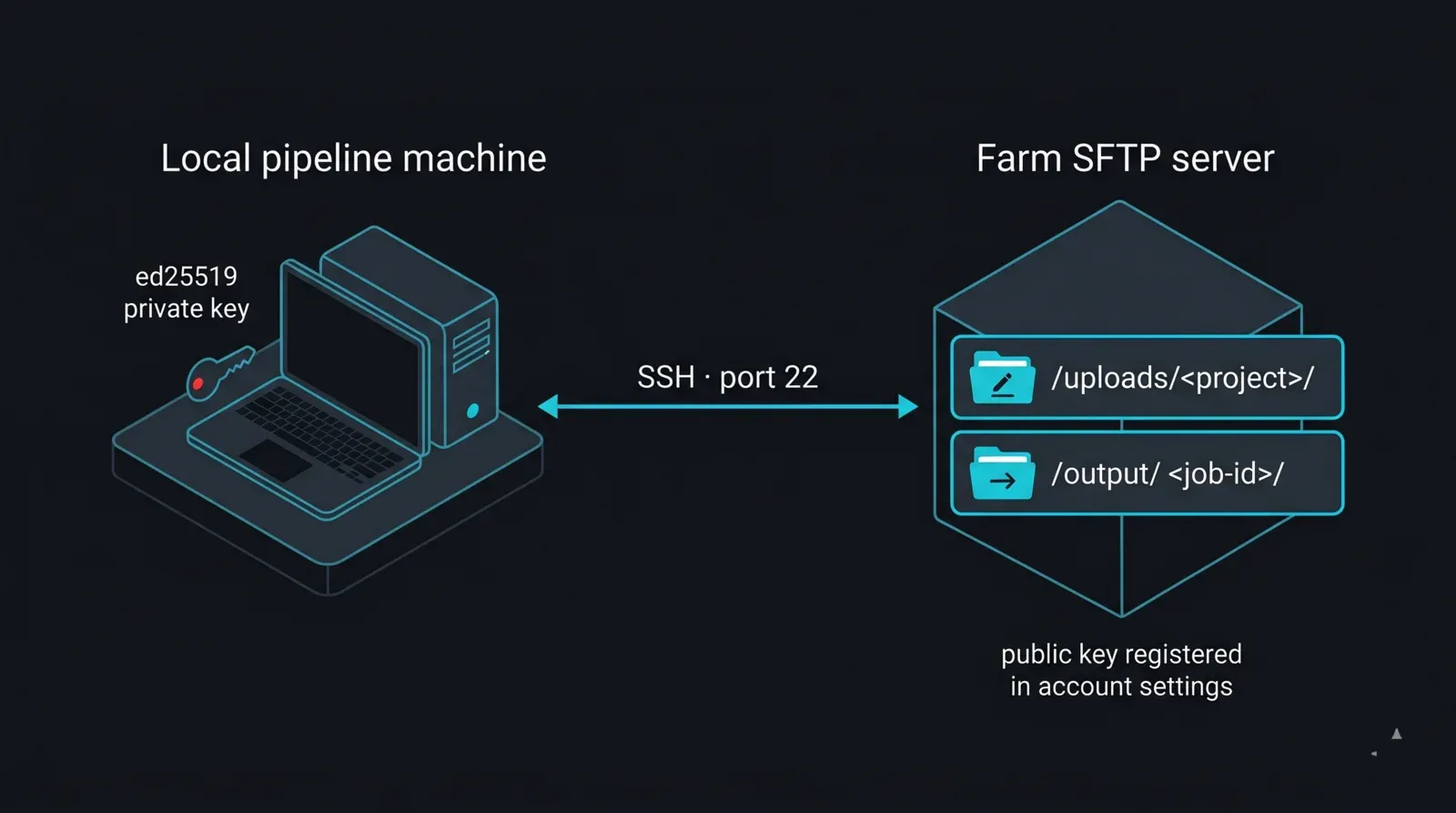
Diagramme de l'architecture du compte SFTP et de l'authentification par clé pour une render farm gérée : une machine de pipeline locale détenant une clé privée ed25519 se connecte via le port SSH 22 au serveur SFTP de la render farm, qui expose deux répertoires — /uploads/<projet>/ comme zone d'écriture pour les projets entrants et /output/<job-id>/ comme zone de lecture pour les images finies ; la clé publique correspondante est enregistrée dans les paramètres du compte
Empaqueter un projet pour qu'il survive à un upload sans surveillance
La plupart des jobs de rendu qui échouent ne sont pas des bugs de moteur — ce sont des problèmes d'empaquetage. Une scène qui se rend sur le poste de travail de l'artiste échoue sur un worker vierge parce qu'un chemin de texture pointe vers un lecteur local uniquement, ou qu'une sous-scène référencée n'a jamais été incluse dans le bundle. L'automatisation amplifie ce problème : un upload sans surveillance d'un package défectueux produit un échec sans surveillance. Deux règles maintiennent les packages propres.
Premièrement, rendez le projet autonome avec des chemins relatifs. Exécutez la commande collect-and-package de votre DCC (Archive, Collecter les fichiers, Sauvegarder le projet avec les assets) afin que chaque texture, proxy et cache se résolve relativement à la racine du projet. Deuxièmement, veillez au format d'archive si vous compressez avant l'upload : nous prenons en charge tar, tar.gz et 7z, mais pas .zip — repackagez en .tar.gz, ou évitez complètement l'archivage et laissez rsync transférer l'arborescence de dossiers, ce qui est généralement le meilleur choix pour les projets en cours. En plafond pratique, gardez un seul upload en dessous de ~300 Go ; au-delà, appuyez-vous sur rsync avec reprise plutôt que sur un transfert monolithique.
Uploader un projet avec paramiko
Le premier bloc de construction est un uploader récursif. Il se connecte avec une clé, parcourt l'arborescence de projet locale, recrée la structure de répertoires sous /uploads/, et dépose chaque fichier. Nous épingleons les clés d'hôte avec RejectPolicy et lisons les détails de connexion depuis l'environnement afin qu'aucune donnée sensible ne vive dans le script.
import os
import paramiko
def connect():
host = os.environ["SRF_SFTP_HOST"]
user = os.environ["SRF_SFTP_USER"]
key_path = os.environ["SRF_SFTP_KEY"] # chemin vers la clé privée
client = paramiko.SSHClient()
client.load_system_host_keys() # ne faire confiance qu'à ~/.ssh/known_hosts
client.set_missing_host_key_policy(paramiko.RejectPolicy())
client.connect(hostname=host, port=22, username=user, key_filename=key_path)
return client, client.open_sftp()
def _ensure_remote_dir(sftp, remote_dir):
# mkdir -p via SFTP : construire le chemin segment par segment
path = ""
for segment in remote_dir.strip("/").split("/"):
path += "/" + segment
try:
sftp.stat(path)
except IOError:
sftp.mkdir(path)
def upload_dir(sftp, local_dir, remote_dir):
for root, _dirs, files in os.walk(local_dir):
rel = os.path.relpath(root, local_dir)
remote_root = remote_dir if rel == "." else f"{remote_dir}/{rel.replace(os.sep, '/')}"
_ensure_remote_dir(sftp, remote_root)
for name in files:
local_path = os.path.join(root, name)
remote_path = f"{remote_root}/{name}"
sftp.put(local_path, remote_path)
print(f"uploaded {remote_path}")
Pour piloter cela sur un projet :
client, sftp = connect()
try:
upload_dir(sftp, "/local/projects/archviz-tower", "/uploads/archviz-tower-2026-06")
finally:
sftp.close()
client.close()
Cela suffit pour les projets petits et moyens. sftp.put accepte aussi un argument callback= qui reçoit les octets transférés et le total, que vous pouvez connecter à un indicateur de progression ou à une ligne de log par fichier. Pour les transferts volumineux et répétés qui caractérisent le travail en studio, rsync est toutefois l'outil mieux adapté.
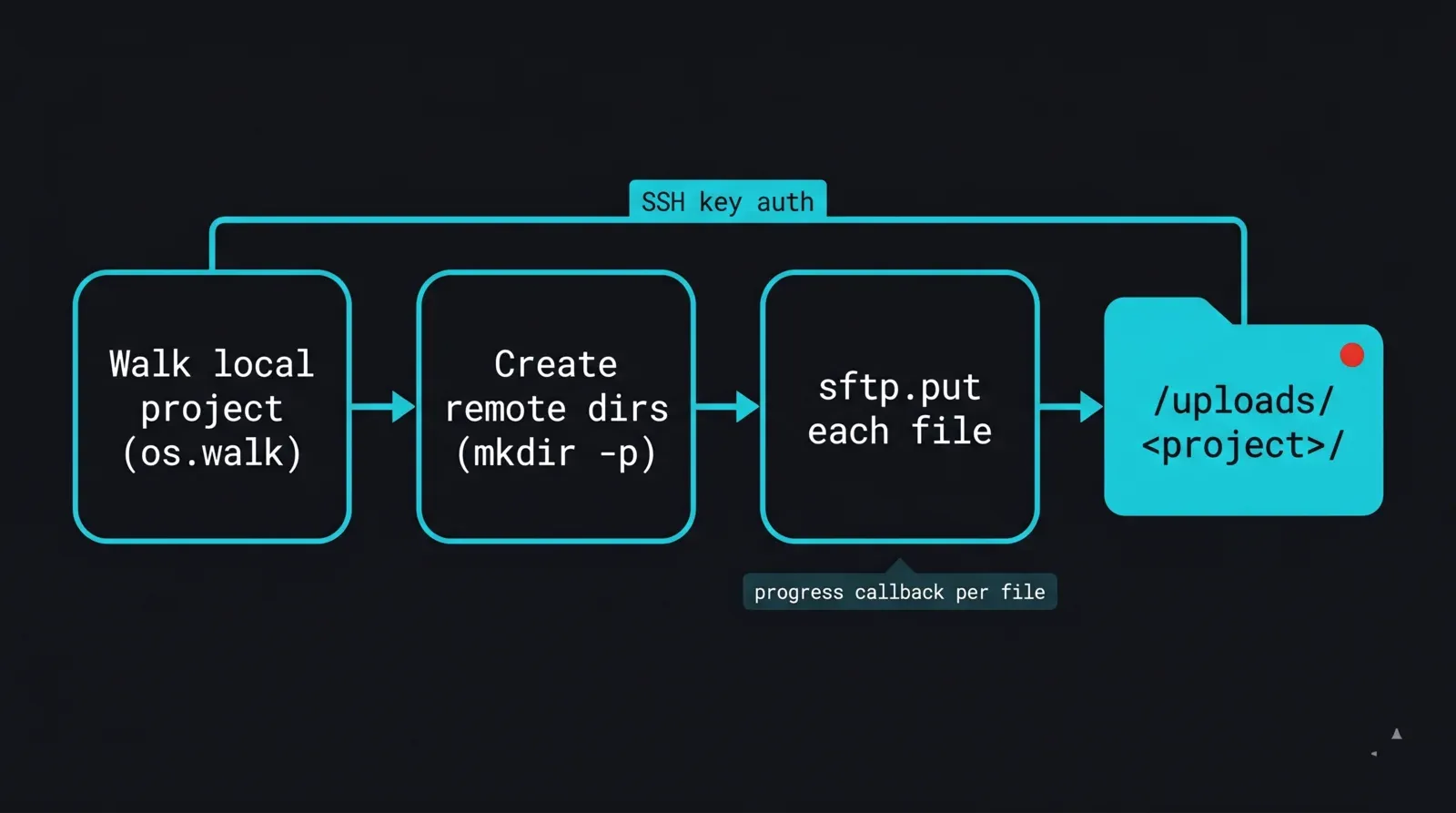
Diagramme de flux d'une routine d'upload paramiko pour une render farm : un dossier de projet local est parcouru fichier par fichier avec os.walk, l'arborescence de répertoires distants est créée sous /uploads avec une boucle mkdir-p, puis chaque fichier est envoyé avec sftp.put via une connexion authentifiée par clé SSH, avec un callback de progression enregistrant chaque fichier complété
Synchronisation incrémentielle avec rsync via SSH
Un projet de rendu est rarement uploadé une seule fois. Vous ajustez un shader, re-cachez une simulation, corrigez une lumière, puis re-uploadez. Envoyer tout le dossier à chaque fois gaspille des heures ; rsync n'envoie que ce qui a changé. Pour un studio qui uploade chaque nuit, c'est le gain de temps le plus important de la couche de transfert, car il transfère le delta plutôt que le projet entier.
L'invocation canonique :
rsync -avz --partial --progress \
/local/projects/archviz-tower/ \
"$SRF_SFTP_USER@$SRF_SFTP_HOST:/uploads/archviz-tower-2026-06/"
-a préserve la structure et les horodatages, -z compresse en transit, --partial conserve les fichiers partiellement transférés afin qu'une connexion interrompue reprenne plutôt que de redémarrer, et --progress rend compte fichier par fichier. Réexécuter la même commande après une modification ne transfère que les fichiers modifiés. L'objectif étant l'automatisation, enveloppez-le dans Python afin qu'il vive dans le même script que tout le reste et pour pouvoir réagir à son code de sortie :
import subprocess
def rsync_up(local_dir, remote_subdir):
host = os.environ["SRF_SFTP_HOST"]
user = os.environ["SRF_SFTP_USER"]
dest = f"{user}@{host}:/uploads/{remote_subdir}/"
cmd = ["rsync", "-avz", "--partial", "--progress",
f"{local_dir.rstrip('/')}/", dest]
subprocess.run(cmd, check=True) # lève CalledProcessError en cas d'échec
Pour l'exécuter sans surveillance, planifiez-le. Un studio qui miroir son répertoire de travail vers la render farm chaque nuit à 1 h du matin n'a besoin que d'une ligne cron :
0 1 * * * cd /studio/pipeline && /usr/bin/python3 nightly_sync.py >> sync.log 2>&1
Pour que rsync via SSH s'authentifie sans invite, pointez-le vers votre clé avec -e "ssh -i ~/.ssh/id_ed25519", ou laissez un agent SSH conserver la clé déverrouillée pour la session.
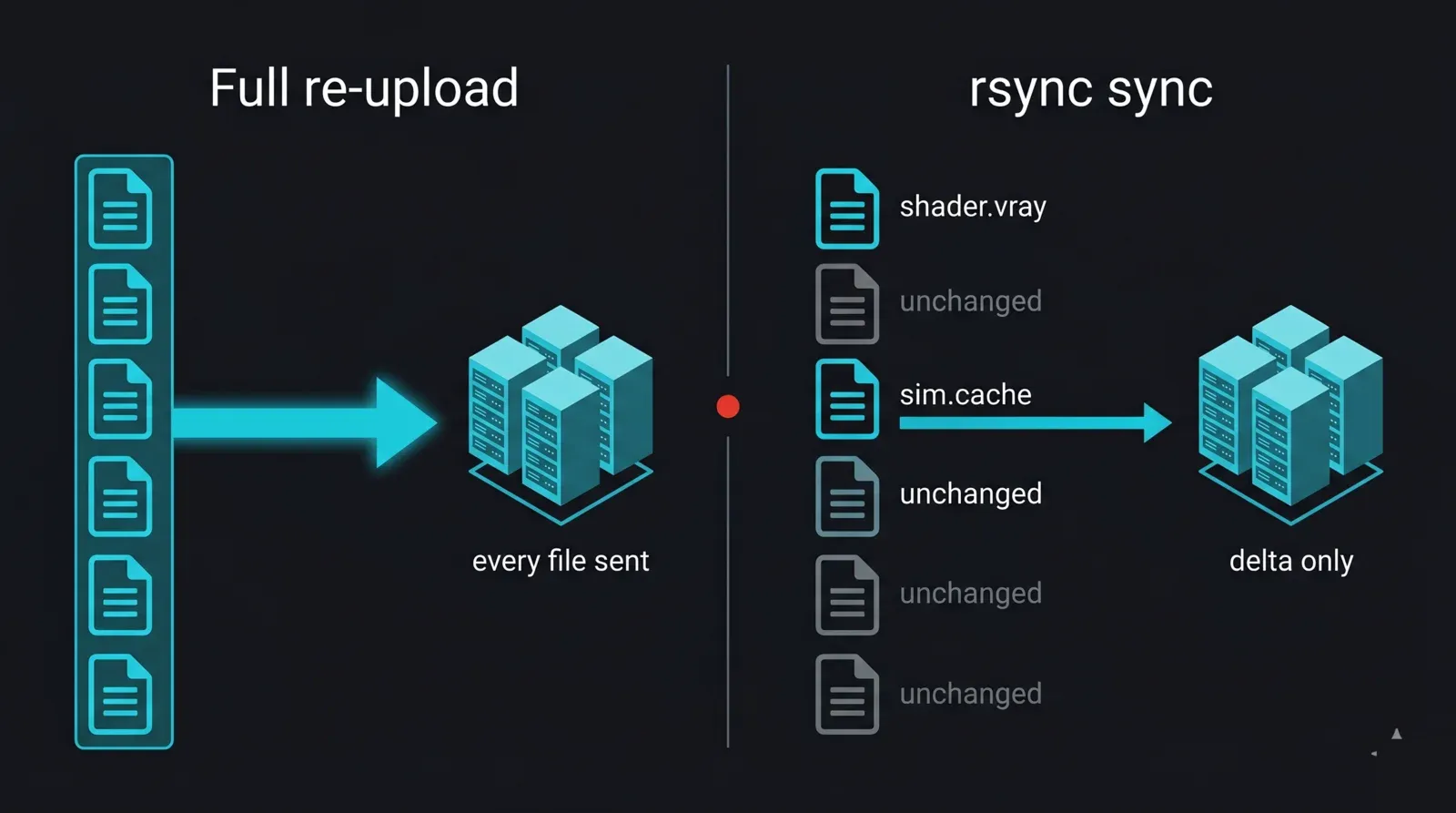
Diagramme avant/après comparant un re-upload complet à une synchronisation incrémentielle rsync vers une render farm : à gauche, chaque fichier du projet est renvoyé chaque nuit ; à droite, rsync compare local et distant et ne transfère que les fichiers modifiés (un shader modifié et un nouveau cache), avec le volume inchangé ignoré, illustrant le transfert delta qui rend les uploads nocturnes d'un studio rapides
Télécharger les images finies automatiquement
Lorsqu'un job se termine, les images de sortie sont écrites dans /output/<job-id>/ sur le serveur SFTP. Le côté téléchargement reflète le côté upload — un get récursif avec paramiko, ou un pull rsync. La version paramiko parcourt le répertoire distant et le recrée localement :
import stat
def download_dir(sftp, remote_dir, local_dir):
os.makedirs(local_dir, exist_ok=True)
for entry in sftp.listdir_attr(remote_dir):
remote_path = f"{remote_dir}/{entry.filename}"
local_path = os.path.join(local_dir, entry.filename)
if stat.S_ISDIR(entry.st_mode):
download_dir(sftp, remote_path, local_path)
else:
sftp.get(remote_path, local_path)
print(f"downloaded {local_path}")
Pour les jeux de sorties volumineux, le pull rsync est de nouveau le choix le plus efficace et le plus repris en cas d'interruption :
rsync -avz --progress \
"$SRF_SFTP_USER@$SRF_SFTP_HOST:/output/<job-id>/" \
/local/downloads/<job-id>/
Un détail opérationnel important pour les pipelines sans surveillance : les sorties rendues sont conservées pendant 45 jours après la fin du job, puis supprimées automatiquement. SFTP ne prolonge pas cette fenêtre. Le modèle sûr est une synchronisation nocturne qui miroir les sorties vers une archive locale dès qu'elles apparaissent, afin que la rétention ne soit jamais ce qui vous prive de vos images.
Détecter la fin d'un job sans API de statut
C'est là que la frontière honnête devient un choix d'ingénierie concret. Il n'existe pas d'endpoint public pour demander « le job 12345 est-il terminé ? » — mais le répertoire de sortie lui-même est observable via SFTP. Le modèle pragmatique consiste à interroger /output/<job-id>/, à compter les fichiers, et à attendre que le compteur atteigne le total d'images attendu et reste stable sur des vérifications consécutives (pour ne pas commencer à télécharger en cours d'écriture).
import time
def wait_for_output(sftp, output_dir, expected_frames, poll=120, stable_checks=2):
last_count, stable = -1, 0
while True:
try:
files = sftp.listdir(output_dir)
except IOError:
files = [] # dossier pas encore créé -> pas démarré
count = len(files)
if count >= expected_frames and count == last_count:
stable += 1
if stable >= stable_checks:
return files # compteur atteint et stable -> considéré terminé
else:
stable = 0
last_count = count
time.sleep(poll)
Soyons clairs sur ce que c'est. Les images apparaissent de façon incrémentielle, donc leur simple présence ne signifie pas que le rendu est terminé ; vérifier le compteur par rapport au total attendu et confirmer qu'il est stable entre les interrogations est ce qui le rend suffisamment fiable pour l'automatisation. C'est une heuristique de répertoire, pas un contrat. Lorsque l'API publique sera disponible, cette fonction entière se réduira à un appel de statut — en attendant, surveiller le répertoire de sortie est la façon raisonnée de combler l'écart, et elle ne dépend de rien qui n'existe pas déjà.
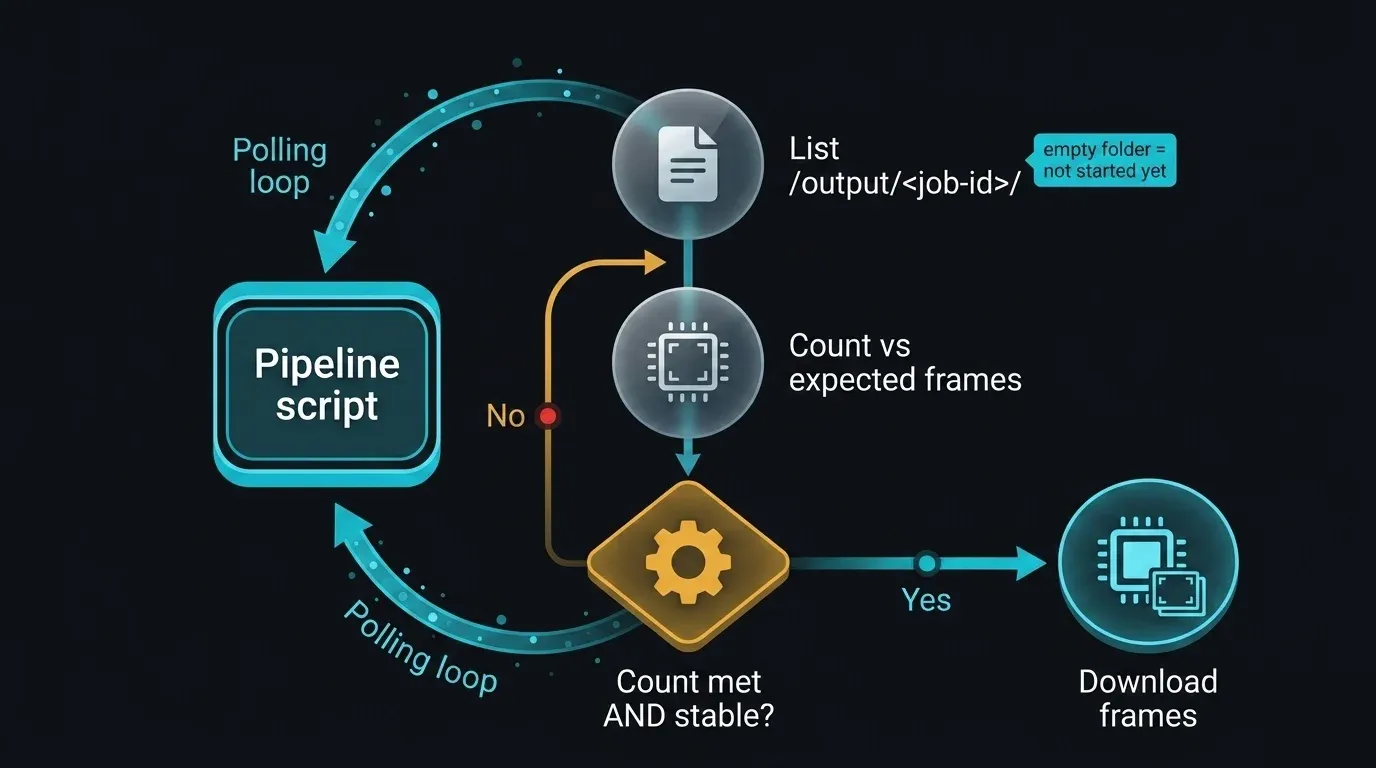
Diagramme de séquence de l'interrogation du répertoire SFTP de sortie pour détecter la fin du rendu sans API de statut : un script pipeline liste répétitivement /output/<job-id>/, compare le nombre d'images au total attendu, attend que le compteur atteigne la cible et reste stable sur deux vérifications consécutives, puis procède au téléchargement — avec un état initial de dossier vide indiquant que le job n'a pas démarré
Assembler les pièces : un pipeline de transfert sans surveillance
Les éléments se composent en un script nocturne unique. La forme est la suivante : synchroniser le projet vers le haut, céder la main pour la soumission, attendre que les sorties apparaissent et se stabilisent, les récupérer, vérifier, et archiver. L'étape de soumission est le transfert de contrôle délibéré vers l'interface graphique — sur une render farm gérée, vous soumettez via le formulaire web, le Client App, ou un plugin de soumission DCC, et les plugins par DCC peuvent être pilotés depuis l'environnement de scripting de l'application hôte (MAXScript, Python dans le DCC) lorsque la soumission vit dans un outil que vous scriptez déjà. Nous marquons cette étape honnêtement plutôt que de l'envelopper dans une fonction qui prétend qu'une API existe.
def nightly_pipeline(project_dir, remote_subdir, job_id, expected_frames):
client, sftp = connect()
try:
# with_retries() (défini dans la section suivante) enveloppe les appels réseau fragiles
with_retries(lambda: rsync_up(project_dir, remote_subdir)) # 1. envoyer le delta
# 2. SOUMETTRE : interface graphique / Client App / plugin DCC -- pas d'API publique (encore)
files = wait_for_output( # 3. surveiller le répertoire de sortie
sftp, f"/output/{job_id}", expected_frames)
with_retries(lambda: # 4. récupérer les images finies
download_dir(sftp, f"/output/{job_id}", f"/local/downloads/{job_id}"))
print(f"job {job_id}: {len(files)} images récupérées")
finally:
sftp.close()
client.close()
Les étapes 1, 3 et 4 sont entièrement automatisées ; l'étape 2 est le transfert de contrôle. Lorsqu'une API de soumission publique sera disponible, les étapes 2 et 3 deviendront des appels d'API et l'interrogation du répertoire sera abandonnée. L'architecture ne change pas — seules les jambes de soumission et de statut passent de l'interface graphique et de l'heuristique à un endpoint.
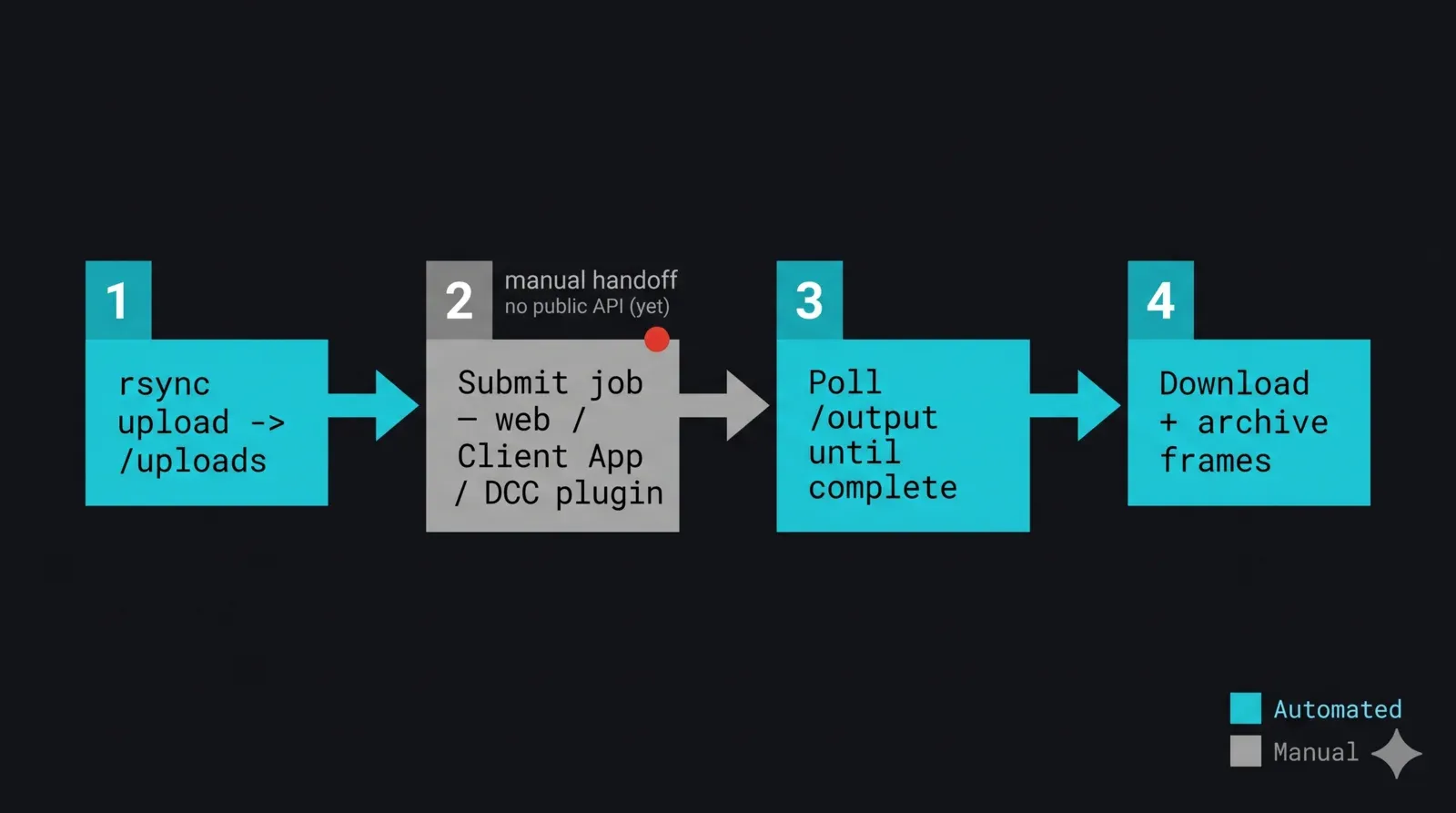
Diagramme de flux de bout en bout d'un pipeline de transfert vers une render farm sans surveillance piloté depuis Python : l'étape 1 rsync uploade le delta du projet vers /uploads, l'étape 2 est un transfert de contrôle clairement marqué vers l'interface graphique où le job est soumis via formulaire web, Client App, ou plugin DCC (pas d'API publique), l'étape 3 interroge /output/<job-id> jusqu'à ce que les images soient complètes et stables, l'étape 4 télécharge et archive les images finies localement — avec les étapes automatisées en cyan et l'étape de soumission manuelle en gris
Gestion des erreurs, reprises et transferts résistants aux interruptions
Sans surveillance signifie que personne ne regarde quand un transfert accroche, donc le script doit se reprendre seul. Trois habitudes couvrent la plupart des pannes.
Réessayez les pannes transitoires avec un délai exponentiel. Les coupures réseau et les déconnexions brèves sont normales sur de longs transferts. Enveloppez les appels fragiles — comme le fait nightly_pipeline ci-dessus — afin qu'une seule coupure ne tue pas l'exécution. Interceptez les erreurs transitoires spécifiques plutôt que tout : SSHException de paramiko, la famille OSError pour les sockets, et CalledProcessError pour un rsync qui échoue.
def with_retries(fn, attempts=3, backoff=5):
transient = (paramiko.SSHException, OSError, subprocess.CalledProcessError)
for i in range(1, attempts + 1):
try:
return fn()
except transient: # réessayer les accrocs SSH / réseau / rsync
if i == attempts:
raise
time.sleep(backoff * i) # délai exponentiel : 5s, 10s, 15s
Appuyez-vous sur la reprise. rsync --partial reprend déjà les fichiers interrompus, et relancer un rsync est idempotent — il n'envoie que ce qui manque — donc une synchronisation rejouée est peu coûteuse, pas un redémarrage. Pour les transferts paramiko, une relance avec un nouveau parcours obtient le même effet parce que les fichiers déjà présents se transfèrent quasi instantanément.
Gérez explicitement les erreurs de clé d'hôte et de connectivité. Une erreur « host key verification failed » signifie que la clé mise en cache dans ~/.ssh/known_hosts ne correspond plus à celle du serveur — le plus souvent après une rare rotation de clé d'hôte. Supprimez la ligne obsolète que l'erreur indique et reconnectez-vous pour accepter la nouvelle clé. Une connexion refusée ou un délai d'expiration signifie généralement qu'un pare-feu de studio bloque le TCP sortant sur le port 22 ; autorisez-le ou demandez au support des alternatives. Et si le débit est bien en dessous du débit de votre lien, la surcharge par paquet de SFTP en est la cause sur les liaisons longue distance — lftp avec des segments parallèles, ou plusieurs sessions SFTP concurrentes, récupèrent la majeure partie de l'écart.
Récapitulatif : ce qu'automatiser, et comment
La couche de transfert est la partie d'un pipeline de render farm gérée que vous possédez en code, et Python la couvre entièrement.
| Tâche | Automatisable en Python ? | Outil | Remarques |
|---|---|---|---|
| Uploader un projet | Oui | paramiko ou rsync | rsync pour les grands volumes/répétitions ; --partial pour reprendre |
| Re-upload incrémentiel | Oui | rsync via SSH | Ne transfère que les fichiers modifiés |
| Télécharger les images finies | Oui | paramiko get / pull rsync | Miroir nocturne — rétention 45 jours |
| Détecter la fin d'un job | Partiel | Interroger /output/<job-id>/ | Heuristique compteur + stabilité, pas d'API de statut |
| Soumettre un job de rendu | Non (aujourd'hui) | Web / Client App / plugin DCC | API publique sur la feuille de route |
| S'authentifier | Oui | Clé SSH (ed25519) | Clé + phrase secrète ; pas de secrets codés en dur |
Automatisez l'upload, automatisez le téléchargement, comblez l'écart en surveillant le répertoire de sortie, et gardez le transfert de contrôle de soumission explicite. Cela vous donne un pipeline nocturne honnête sur ses coutures et fiable grâce à elles. Pour les projets lourds en simulation où la fiabilité des transferts importe le plus — les caches Houdini multi-téraoctets et autres — ces mêmes modèles s'adaptent directement sur Super Renders Farm ; notre page render farm cloud Houdini couvre cette charge de travail.
FAQ
Q: Quelle bibliothèque Python utiliser pour uploader vers la render farm ?
A: paramiko est le choix standard et est cité directement dans notre documentation SFTP comme client pris en charge. Elle est pure Python, gère SFTP proprement, et fonctionne bien pour la logique d'upload et de téléchargement. Pour les transferts très volumineux ou fréquemment répétés, déléguez à rsync via SSH depuis Python avec subprocess — il n'envoie que les fichiers modifiés et reprend les transferts interrompus, ce que paramiko ne fait pas nativement.
Q: Existe-t-il une API publique pour soumettre des jobs de rendu depuis mon pipeline Python ? A: Pas encore. Une API REST publique pour la soumission, l'interrogation de statut et la récupération des sorties est sur notre feuille de route, mais aucun endpoint public n'est disponible aujourd'hui. Les voies de soumission programmatiques actuelles sont le SuperRenders Client App et le plugin de soumission par DCC, qui s'intègre à l'environnement de scripting de l'application hôte, comme MAXScript ou Python dans le DCC. Si votre pipeline est spécifiquement bloqué sur une API de soumission publique, contactez le support et partagez le cas d'usage — la feuille de route est alimentée par les besoins réels des pipelines.
Q: Comment détecter la fin d'un job de rendu sans API de statut ?
A: Interrogez le répertoire SFTP de sortie du job, /output/<job-id>/, et surveillez le compteur d'images. Traitez le job comme terminé uniquement lorsque le compteur atteint le total attendu et reste stable sur des vérifications consécutives, afin de ne pas commencer à télécharger pendant que les images sont encore en cours d'écriture. C'est une heuristique de répertoire plutôt qu'un signal de statut officiel, mais elle ne repose que sur des capacités qui existent aujourd'hui.
Q: Dois-je utiliser des clés SSH ou un mot de passe pour les transferts automatisés ? A: Utilisez une clé SSH. Coder un mot de passe en dur dans un script est un risque de sécurité, et l'authentification par clé s'exécute sans surveillance sans invite interactive. Générez une clé ed25519, enregistrez la moitié publique dans Settings → SFTP → SSH Keys, et protégez la clé privée avec une phrase secrète détenue par un agent SSH. Puisque l'authentification à deux facteurs n'est pas actuellement prise en charge sur les comptes, la clé plus sa phrase secrète est le renforcement pratique le plus solide pour l'accès SFTP.
Q: Puis-je uploader une archive .zip depuis mon script ?
A: Non — les archives .zip ne sont pas prises en charge. Repackagez en .tar.gz (ou .tar / .7z), ou évitez l'archivage et laissez rsync transférer l'arborescence de dossiers directement, ce qui est généralement la meilleure option pour les projets qui changent entre les uploads. Gardez un seul upload en dessous de 300 Go environ et utilisez rsync --partial pour tout ce qui est plus grand afin qu'une connexion interrompue reprenne plutôt que de redémarrer.
Q: Quelle taille de projet peut-on déplacer de cette façon ?
A: Les transferts multi-téraoctets sont pris en charge via SFTP ; la limite pratique est votre propre bande passante d'upload, pas un plafond imposé par la render farm. Un upload de 1 To à 100 Mbps prend environ une journée, donc planifiez en fonction de votre lien. Pour un débit maximal sur des connexions à grande capacité ou longue distance, utilisez lftp avec des segments parallèles ou plusieurs sessions SFTP concurrentes, car un seul flux SFTP est limité par la surcharge par paquet.
Q: Combien de temps mes images rendues sont-elles disponibles au téléchargement ?
A: Les sorties sont conservées pendant 45 jours après la fin d'un job, puis supprimées automatiquement, et SFTP ne prolonge pas cette fenêtre. Pour un pipeline sans surveillance, miroitez les sorties vers une archive locale dès qu'elles apparaissent — un pull rsync nocturne de /output/<job-id>/ évite que la rétention devienne jamais la raison de la perte d'une image.
Q: En quoi ce guide diffère-t-il de votre guide sur les workflows headless et sans surveillance ?
A: Ce guide est la carte conceptuelle — ce que signifie le rendu headless, comment préparer les scènes pour le rendu en ligne de commande, et comment la boucle sans surveillance s'articule sur une render farm gérée. Celui-ci est le guide compagnon au niveau du code axé sur la couche de transfert : le paramiko et le rsync concrets que vous écrivez pour faire monter les projets et redescendre les images. Lisez le guide workflow pour la forme ; utilisez celui-ci pour l'implémentation.
About Alice Harper
Blender and V-Ray specialist. Passionate about optimizing render workflows, sharing tips, and educating the 3D community to achieve photorealistic results faster.



