Déployer une render farm GPU dédiée 20 nœuds transfrontalière (2026)
Aperçu
Introduction
Quand une équipe créative demande une render farm dédiée s'étendant sur plusieurs pays, elle contourne presque toujours une contrainte qu'une render farm SaaS ne peut résoudre. Il peut s'agir d'un studio qui ne peut contractuellement laisser un tiers détenir ses identifiants, d'une équipe distribuée dont les artistes dans un pays pilotent des nœuds dans un autre, ou d'une maison de production dont l'engagement de plusieurs mois rend la facturation par image économiquement inadaptée.
Selon notre expérience, la partie difficile est rarement « louer plus de GPU ». Il s'agit de connecter les bons éléments : stockage cloud appartenant au client, flotte GPU privée dimensionnée à la charge, transport transfrontalier chiffré qui résiste à la gigue, et une couche bureau à distance qui ne s'effondre pas dès l'ouverture d'une visualisation 3D lourde. Quand un élément est mauvais, le cluster fonctionne, mais les artistes le remarquent — et l'engagement se dégrade silencieusement.
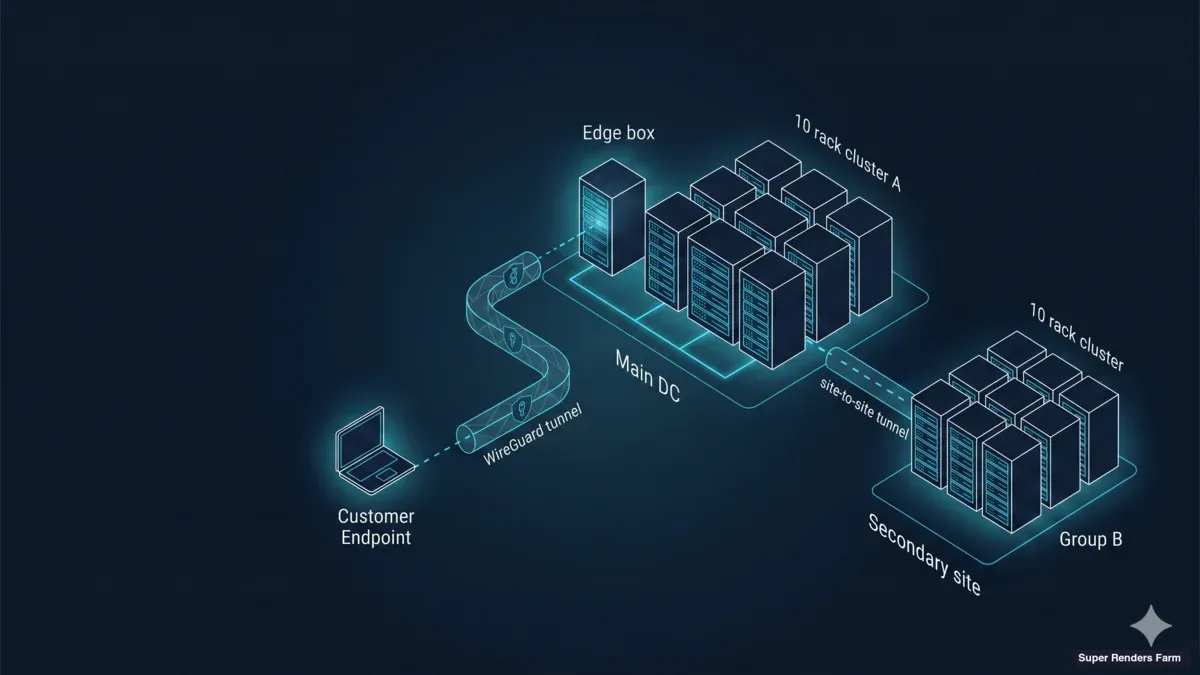
Nous opérons Super Renders Farm, une render farm cloud avec une flotte CPU et GPU substantielle, et nous montons également des clusters GPU dédiés pour les équipes dont les workflows ne s'inscrivent pas dans notre service géré. Cet article est un guide de terrain tiré de ces déploiements — comment nous architecturons une render farm GPU dédiée de 20 nœuds servant une équipe créative distribuée d'artistes au-delà des frontières depuis un seul site dédié, avec des notes honnêtes sur les choix que nous avons faits, ceux que nous avons révisés, et les leçons que nous appliquons désormais par défaut. Si vous évaluez l'infrastructure dédiée face à notre location de render farm gérée, ce guide vous aidera à décider si la voie dédiée vaut la surface architecturale supplémentaire.
Critères de décision : dédié contre SaaS
La plupart des charges de rendu n'ont pas besoin d'un cluster dédié. Une render farm cloud gérée prend une scène, planifie les images et facture à la minute. Il n'y a aucune infrastructure à posséder, aucun pare-feu à maintenir, aucune équipe d'exploitation à assigner côté client. Pour un travail axé projet — un court métrage unique, une publicité de 30 secondes, un lot d'images fixes — ce modèle gagne sur tous les axes pertinents.
Un cluster dédié ne justifie sa complexité que lorsqu'au moins un des critères suivants est vrai :
- Le contrôle de la propriété intellectuelle est contractuel, non préférentiel. Le contrat-cadre du client ou son contrat d'agence interdit à un tiers de détenir des fichiers de scène ou des identifiants de rendu. Les pipelines SaaS qui médient le téléversement de scène violent cette contrainte, même si la puissance de calcul sous-jacente est identique.
- L'engagement dure plusieurs mois, pas plusieurs jours. Un travail de forme fixe — une série animée de longue durée, un pipeline archviz pluri-trimestriel, un plateau de production virtuelle en cours — amortit le coût d'architecture initial. La facturation par image, à l'inverse, se multiplie linéairement avec la durée et cesse d'être compétitive au-delà d'un certain horizon.
- Le workflow est suffisamment personnalisé pour qu'un pipeline géré ne puisse l'héberger. Des stacks de plugins DCC personnalisés, des render managers internes, des pipelines lourds en simulation qui pré-cuisent vers un cache partagé, ou des chaînes d'outils propriétaires poussent tous vers des nœuds dédiés que le client peut configurer directement.
- Bring-your-own-cloud est une exigence dure. Quand les assets du projet du client résident dans une plateforme cloud de streaming de fichiers sous le compte du client, le cluster doit se connecter en tant que client — pas en tant que fournisseur d'infrastructure. C'est le modèle « Model B » décrit en détail ci-dessous.
- Les besoins de segmentation réseau dépassent le VLAN par tenant. Certains workflows exigent que le cluster soit invisible pour le réseau plus large du fournisseur — non seulement isolé logiquement, mais aussi isolé par routage.
Si aucun de ces critères ne s'applique, une render farm gérée est presque certainement le bon choix. Si deux ou plus s'appliquent, la conversation se déplace vers le dédié. La question restante est géographique : les artistes pilotant le travail sont-ils proches du site, ou le cluster doit-il les servir à travers un backbone ISP public qui franchit des frontières nationales ?
Vue d'ensemble de l'architecture
L'architecture que nous déployons pour les clusters dédiés transfrontaliers comporte trois plans : un plan de transport, un plan de calcul et un plan d'accélération de stockage. Chacun a un mode de défaillance unique qui, dans notre expérience, représente l'essentiel de la douleur opérationnelle quand il casse.
[ Artistes distants — répartis sur plusieurs pays ]
│
│ WireGuard hub-and-spoke
│ (UDP 51820, chiffré de bout en bout,
│ transport BBR + MSS-clampé)
▼
┌─────────────────────────────────────────────────────┐
│ Super Renders Farm — site de cluster dédié │
│ │
│ ┌─────────────────────────────────────────────┐ │
│ │ EDGE + CACHE BOX (hôte Ubuntu unique) │ │
│ │ • WireGuard hub (NAT/MASQUERADE) │ │
│ │ • Cache Samba SMB3 (SSD unique, ext4) │ │
│ │ • dnsmasq (zone .lan) │ │
│ │ • chrony (NTP) │ │
│ │ • ufw + BBR + clamp TCP MSS │ │
│ └────────────────────┬────────────────────────┘ │
│ │ LAN │
│ ┌────────────────────▼────────────────────────┐ │
│ │ 20 × nœuds de rendu RTX 5090 │ │
│ │ (Windows 11 Pro, Sunshine, client cloud │ │
│ │ de streaming, mount cache — image │ │
│ │ uniforme sur toute la flotte) │ │
│ └─────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
│
▼
[ Plateforme cloud de streaming du client —
le client se connecte sur chaque nœud ; Super Renders
Farm ne détient pas les identifiants (Model B) ]
Le plan de transport est WireGuard, en hub-and-spoke. Chaque station de travail d'artiste se connecte au hub du site de cluster via un tunnel UDP chiffré ; tout le trafic artiste-vers-cluster, quelle que soit la localisation de l'artiste, emprunte la même topologie de tunnel. Le plan de calcul est composé de vingt nœuds Windows 11 Pro, chacun pilotant une NVIDIA RTX 5090 avec 32 Go de VRAM, déployés comme un seul pool uniforme dans un seul site. Le plan d'accélération de stockage est une seule edge-and-cache box sur le site hébergeant un partage Samba SMB3 sur un SSD unique en ext4 — ainsi que les services réseau dont dépend le cluster (DNS, NTP, pare-feu).
Décision de conception clé : la edge box et la cache box sont la même machine. Une version antérieure de cette architecture plaçait la passerelle edge sur un appareil séparé et le cache sur un NAS, ce qui créait des conditions de course lors des cold pulls et deux surfaces à patcher. Consolider sur un seul hôte Ubuntu 22.04 LTS a éliminé les deux problèmes. La box devient une ressource critique — mais les données projet du client résident toujours dans la plateforme cloud de streaming, donc le cache se réchauffe depuis l'amont après toute panne locale.
Configuration du cluster GPU 20 nœuds
La taille par défaut pour les déploiements décrits ici est vingt nœuds RTX 5090, déployés comme un seul pool uniforme dans un seul site. C'est la taille qui correspond bien à une équipe créative dans la fourchette de dix à vingt artistes — la bande où les clusters dédiés s'amortissent pour les workflows sensibles à la propriété intellectuelle.
Chaque nœud a la même configuration matérielle : une RTX 5090 avec 32 Go de VRAM, un CPU multi-cœur moderne, 64 ou 128 Go de RAM système, et un disque NVMe local dimensionné pour l'OS et le scratch uniquement. Les données projet persistantes vivent sur le cache partagé ou dans la plateforme cloud de streaming en amont — jamais sur le nœud lui-même.
Le système d'exploitation sur chaque nœud est Windows 11 Pro, déployé depuis une image propre. Nous ne préchargeons délibérément aucun stack de plugin DCC sur l'image. Le client pilote l'installation de ses propres outils DCC — Cinema 4D, Redshift, Houdini, After Effects, Blender et autres — afin que l'image du nœud reste minimale et reproductible. À la fin de l'engagement, nous effaçons et ré-imageons depuis la même base propre.
Nous avons délibérément choisi 32 Go de VRAM par nœud. Les renderers GPU modernes — Redshift, Octane, Arnold GPU, Cycles — chargent de plus en plus des scènes texturées volumineuses qui ne tiennent tout simplement pas dans des cartes à 24 Go. La RTX 5090 à 32 Go est le sweet spot actuel pour les renderers de production ; elle gère la plupart des travaux d'archviz, de motion design et d'animation sans paginer vers la RAM système, là où les pools GPU mixtes deviennent silencieusement lents.
Les vingt nœuds sont configurés à l'identique — même image, même installation DCC, même mount cache, même route WireGuard — et se présentent comme un seul pool au render manager du client. Deadline, Royal Render, ou le propre scheduler du client traite la flotte comme une seule ressource, sans logique de routage par groupe ni rééquilibrage manuel. Les images sont distribuées au nœud libre disponible ; le render manager du client gère la répartition de charge au niveau de la file de jobs.
La flotte est routable couche 3 — le client installe son propre render manager et soumet depuis une station de travail distante plutôt que de piloter chaque nœud par bureau à distance. C'est la différence entre un cluster que les artistes combattent et un cluster que les artistes oublient.
Identifiants appartenant au client (Model B)
La décision architecturale unique qui rend le plus souvent un cluster dédié la bonne réponse pour les workflows sensibles à la propriété intellectuelle est ce que nous appelons Model B : les identifiants appartiennent au client. En Model A — le défaut pour les render farms gérées, y compris notre propre service SaaS — le fournisseur d'infrastructure détient les identifiants du pipeline de rendu. Le client téléverse des fichiers de scène ; le pipeline du fournisseur médie le rendu. Cela fonctionne pour la grande majorité des charges et est le modèle derrière presque toutes les render farms cloud commerciales.
En Model B, le fournisseur d'infrastructure fournit le matériel, le système d'exploitation, le réseau et la couche cache, mais ne détient jamais le matériel d'authentification du client pour la plateforme cloud de streaming ou pour les données source du projet. Le client se connecte à la plateforme cloud sur chaque nœud, exactement comme il le ferait sur sa propre station de travail. Les fichiers projet sont streamés depuis le cloud du client. Les rendus sont écrits vers le cloud du client. Le rôle du fournisseur est borné à la couche matériel-et-pipeline.
C'est important pour trois raisons :
- Contractuel : Quand le contrat aval du client comprend un NDA ou un accord-cadre qui restreint où les identifiants et les fichiers sources peuvent être détenus, Model B maintient le fournisseur hors du périmètre de ces restrictions. Le client n'a pas besoin de négocier l'intégration du fournisseur de rendu dans une chaîne contractuelle qui n'a pas été conçue pour cela.
- Audit : Quand le client doit démontrer à un auditeur de sécurité que son pipeline de rendu n'expose pas les identifiants à un tiers, Model B lui donne une réponse claire. Le fournisseur peut produire la documentation matérielle, réseau et opérationnelle ; le client produit la chaîne d'identifiants.
- Clôture d'engagement : Parce que le fournisseur n'a jamais détenu d'identifiants, le nettoyage de fin d'engagement est plus simple. Le client révoque ses propres sessions cloud ; le fournisseur efface le cache, ré-image les nœuds et fournit une attestation écrite de destruction. Il n'y a aucune étape de rotation d'identifiants pour le fournisseur à certifier, car aucun identifiant n'a jamais été détenu.
Model B n'est pas pour tout le monde. Il met l'équipe d'exploitation du client sur la sellette pour le cycle de vie des identifiants sur chaque nœud — vingt rotations à coordonner si les secrets sont renouvelés mensuellement. Les équipes disposant de cette pratique opérationnelle trouvent le compromis acceptable. Celles qui ne l'ont pas tendent à rester sur le rendu géré Model A.
Intégration cloud de streaming
Dans les configurations dont nous discutons, les assets projet du client vivent dans une plateforme cloud de streaming — un service qui expose son arbre projet adossé au cloud comme un système de fichiers virtuel sur chaque nœud. L'artiste monte le projet ; le nœud lit les fichiers à la demande ; la plateforme gère le stockage de fond, le versioning et la réplication entre régions.
Nous intégrons avec une plateforme cloud de streaming générique du choix du client. La plateforme voit un événement de connexion depuis chaque nœud avec le compte du client ; le client de la plateforme sur le nœud monte l'arbre projet à un chemin connu ; l'application DCC du client ouvre les fichiers depuis ce chemin exactement comme sur une station de travail locale. La plateforme cloud n'a pas besoin de savoir que le nœud fait partie d'un cluster de rendu.
Ce qui change quand cela est connecté à un cluster de 20 nœuds, c'est le modèle d'accès. Un seul artiste sur une seule station tire un fichier projet à la fois, à la demande, pendant son travail. Vingt nœuds de rendu ouvrant simultanément la même scène pour une plage d'images créent une rafale synchronisée de lectures cloud pour les mêmes assets. Sans cache, chaque nœud tire chaque texture, chaque simulation en cache, chaque fichier de dépendance en parallèle — ce qui est à la fois un gaspillage de bande passante internationale et lent sur la première image de chaque plage.
C'est pourquoi le cache partagé existe. Nous en parlons en détail dans la section suivante, mais l'intégration avec le streaming cloud est la raison pour laquelle il doit exister. Les pulls d'assets depuis le cloud sont concentrés une seule fois par la cache box, puis distribués aux vingt nœuds sur le LAN. La plateforme cloud ne voit jamais vingt téléchargements simultanés de la même texture — elle en voit un, plus des lectures SMB chaudes à l'intérieur de notre réseau.
L'autre détail pratique est le write-back. Quand une image de rendu se termine, le nœud écrit la sortie vers la plateforme cloud de streaming — à travers le compte du client. L'équipe du client dans le bureau distant voit les images apparaître dans l'arbre projet en temps réel. Il n'y a pas d'étape de téléversement manuel, pas de transfert médié par le fournisseur ; la plateforme cloud gère l'aller-retour.
Architecture du cache partagé
Le cache partagé est l'un des deux ou trois choix architecturaux qui, mal pris, érodent silencieusement la valeur du cluster. Nous l'avons mal pris dans des déploiements antérieurs. Le pattern qui a tenu sur plusieurs builds est délibérément conservateur.
Une seule edge-and-cache box exécute Ubuntu 22.04 LTS, avec un seul SSD SATA de 8 To formaté en ext4 et exposé au cluster via Samba SMB3. Le mount cache apparaît sur chaque nœud de rendu à un chemin fixe (par exemple \\cache.lan\proj). Quand un nœud ouvre un fichier projet via le client cloud de streaming, le fichier est streamé à travers le cache local ; les lectures suivantes du même fichier sur n'importe quel nœud touchent directement le SSD via le LAN.
Trois choix délibérés sont enfouis dans ce paragraphe.
Premièrement, un cache unique, pas des caches par nœud. Une version antérieure de cette architecture stockait le matériel de cache par nœud. Avec vingt nœuds 5090, cela représentait jusqu'à 200 To de stockage redondant à gérer, et vingt états de cache séparés à déboguer en cas de divergence. Consolider sur un seul cache partagé réduit l'empreinte de stockage d'un facteur vingt et fait de l'état du cache un seul artefact que l'équipe d'exploitation peut inspecter.
Deuxièmement, un SSD unique sur ext4, pas de RAID 10 avec LUKS sur XFS. Le plan antérieur prévoyait que le cache réside sur un tableau RAID 10 avec chiffrement LUKS au repos sur XFS. Ce plan était sur-ingénié pour le matériel réel déployé — un SSD, un système de fichiers, un mount. Nous avons retiré la couche RAID, retiré LUKS, et utilisé ext4 parce que le cache n'est pas la source de vérité pour les données projet. Le cloud du client est la source de vérité. Si le disque cache tombe en panne, nous le remplaçons et réchauffons depuis l'amont ; nous n'avons pas besoin de redondance au niveau du cache parce que nous avons la redondance au niveau cloud. (Le chiffrement au repos était hors du périmètre de cet engagement, mais il est disponible dans le cadre d'un engagement séparé lorsqu'un client aval l'exige.)
Troisièmement, pré-réchauffer le cache avant le premier jour de rendu. C'est la leçon apprise à la dure. À J-jour, chaque cache miss est la lecture la plus coûteuse du cluster — elle traverse le lien international, tire depuis le cloud du client, et écrit sur le SSD local avant que le renderer puisse l'utiliser. Le pré-réchauffage, qui consiste en une traversée structurée de l'arbre d'assets du projet la veille du démarrage de la production, convertit les lectures de J-jour de cold cloud pulls en lectures SMB chaudes. Nous prévoyons désormais une fenêtre de pré-réchauffage dans chaque engagement de cluster dédié.
À l'intérieur du site, chaque nœud monte le cache au même chemin fixe (\\cache.lan\proj) via SMB3 sur le LAN local. Parce que le trafic intra-site ne traverse pas le tunnel WireGuard, le clamping MSS ne s'applique pas ici et le lien fonctionne à pleine vitesse Ethernet gigabit. Le chemin de mount du cache est identique sur chaque nœud, ce qui simplifie la configuration du render manager du client — le même chemin de fichier de scène se résout de la même façon sur chaque membre du pool.
Optimisation réseau transfrontalière
La couche transport décide si un cluster transfrontalier paraît sans couture ou cassé. Les comportements par défaut de TCP/IP, de la fragmentation IP et du DNS-sur-VPN sont subtilement mauvais pour les tunnels chiffrés longue distance transportant SMB et bureau à distance. Régler le noyau et la configuration réseau n'est pas optionnel ; c'est la différence entre un cluster qui fonctionne et un cluster qui perd mystérieusement de gros paquets.
WireGuard hub-and-spoke. Chaque artiste se connecte depuis sa station de travail via un client WireGuard au hub du site de cluster. Tout le trafic entre l'artiste et le cluster est chiffré de bout en bout. Nous utilisons délibérément une seule technologie VPN plutôt que de mélanger les protocoles ; combiner IPSec pour un rôle et un VPN différent pour un autre ajoute une surface opérationnelle sans améliorer la sécurité.
TCP BBR. Le contrôle de congestion par défaut de Linux (CUBIC) a été conçu pour des liaisons à faible latence avec peu de perte de paquets. Les liaisons ISP publiques longue distance transportant du trafic chiffré sont très différentes — latence modérée, gigue occasionnelle et modèles de perte asymétriques. BBR produit constamment plus de débit utilisable sur ces liaisons que CUBIC, surtout quand la liaison est partagée avec l'autre trafic internet du client. Nous utilisons le BBR standard du noyau (BBR v1) ; la version plus récente BBRv3 n'a pas été déployée dans ce build, et la version standard s'est avérée stable pour nous.
Clamping TCP MSS. C'est la source la plus courante des plaintes « le cluster fonctionne, sauf pour les gros fichiers ». Quand le trafic traverse un tunnel qui réduit le MTU effectif, les gros paquets sont soit fragmentés (lent) soit perdus silencieusement (pire). Les petits paquets et le ping fonctionnent bien, ce qui rend le problème difficile à diagnostiquer. La correction est de clamper le TCP MSS sur le routeur WireGuard, de sorte que TCP négocie une taille de paquet qui tient dans le tunnel. Après application, les handshakes TLS, les sessions RDP et les lectures SMB de gros fichiers cessent de se bloquer.
dnsmasq avec l'interface VPN listée. Un piège subtil : dnsmasq doit lister explicitement l'interface WireGuard (par exemple wg0) dans sa configuration, même si le client interroge une adresse .lan privée. Sans cela, les requêtes DNS via le tunnel expirent — mais le ping fonctionne toujours, car le ping ne passe pas par DNS. Cela produit certaines des sessions de diagnostic les plus déroutantes que nous ayons menées, parce que tous les autres tests semblent sains.
chrony pour NTP. La synchronisation temporelle semble triviale mais elle compte pour les render managers (Deadline horodate les jobs), la corrélation des logs entre les nœuds du cluster, et tout token d'authentification avec une composante temporelle. chrony gère la dérive d'horloge sur une liaison à longue latence mieux que l'ancien ntpd ; nous l'exécutons sur la edge box et chaque nœud se synchronise avec elle.
L'effet combiné de ces choix est un tunnel qui se comporte comme un LAN pour la plupart des charges et se dégrade gracieusement quand le chemin public est inhabituellement congestionné. La section suivante couvre à quoi ressemble l'exécution de travaux 3D à travers ce tunnel en pratique.
Moonlight et Sunshine pour le bureau à distance
Le bureau à distance est la couche que les artistes expérimentent le plus directement. Si cette couche paraît lente ou saccadée, peu importe la vitesse du renderer — les mains de l'artiste sont lentes, et l'engagement se dégrade.
Nous utilisons Moonlight (client) et Sunshine (hôte sur chaque nœud) pour le bureau à distance. La combinaison utilise l'encodeur matériel NVENC de NVIDIA sur la RTX 5090 pour encoder le framebuffer en temps réel, puis le streamer vers la station de travail de l'artiste. Parce que l'encodage se passe sur le GPU déjà présent dans le nœud, il n'y a aucune contention avec le renderer, et la latence ajoutée par le bureau à distance est dominée par l'aller-retour réseau — pas par l'étape d'encodage.
Pour le travail viewport 3D, c'est important d'une façon que ce n'est pas pour le bureau à distance traditionnel. Les anciens protocoles — RDP, VNC, le bureau à distance Microsoft standard — ont été conçus pour des charges bureau. Ils gèrent bien le texte, les dialogues et les fenêtres à changement lent, mais s'effondrent sur un viewport 3D plein écran pendant un aperçu turntable. Moonlight + Sunshine traitent le framebuffer comme de la vidéo — exactement le bon modèle pour le travail 3D.
Nous avons un test de qualité que nous exécutons avant de remettre un nœud à un artiste — informellement « Test 8 » — qui enchaîne une séquence définie d'opérations viewport sous charge et confirme que l'expérience bureau à distance répond à un standard de base. Si un nœud échoue au test, nous déboguons le pipeline d'encodage ou retirons le nœud de la rotation jusqu'à résolution. Nous exécutons ce test au début de chaque engagement et après tout ré-imagerie de nœud.
Parsec est un repli viable quand Sunshine a un problème spécifique à l'hôte. Nous avons livré un petit nombre de nœuds sur Parsec quand Sunshine ne pouvait pas être configuré de façon fiable ; l'expérience artiste est similaire. Nous ne le standardisons pas, car le modèle basé sur les comptes et la coordination cloud ne s'adapte pas aussi proprement à la gestion des identifiants Model B que le Sunshine auto-hébergé.
Nous avons envisagé d'autres options de bureau à distance en début de planification et nous les avons écartées — des outils bureau à distance génériques sans encodage GPU, et une alternative open source qui ne passait pas notre test de qualité sur un viewport 3D plein écran. Le principe qui compte : pour les nœuds de cluster GPU, le streaming à encodage matériel est le seul modèle qui tient à l'échelle.
Planification de capacité et tranche réservée
La configuration 20 nœuds de ce guide est une tranche dédiée réservée de la flotte plus large de Super Renders Farm, découpée pour la durée de l'engagement. Réservée signifie que les nœuds ne sont pas partagés avec le pool de service géré, ne sont pas co-schedulés avec d'autres locataires, et ne sont pas soumis à la facturation par image — le client paie la tranche comme une dépense opérationnelle forfaitaire et dispose d'un contrôle exclusif sur ces nœuds du lancement à la clôture.
Dimensionner la tranche à vingt nœuds est un choix délibéré. En dessous de dix nœuds, un cluster ne justifie pas sa surface architecturale face à une render farm gérée — la voie SaaS est plus simple et plus économique. Au-dessus de trente, la couche cache nécessite une re-architecture (plusieurs cache boxes, caches régionaux) et le modèle opérationnel change de forme. Vingt est la bande où une seule edge-and-cache box, un seul hub WireGuard et une image Windows uniforme tiennent proprement — et où une équipe créative de dix à vingt artistes dispose de suffisamment de nœuds pour maintenir le flux d'images pendant les pics sans temps mort pendant l'état stable.
Parce que Super Renders Farm opère une flotte substantielle au-delà de cette tranche dédiée, une marge de montée en charge existe quand l'engagement en a besoin. Ajouter des nœuds réservés supplémentaires dans le même site est un changement de configuration, pas un cycle d'approvisionnement. Les clients qui exécutent des engagements pluri-mensuels verrouillent généralement la taille de la tranche au lancement et la re-définissent aux limites des trimestres en fonction de la demande réelle face au plan initial.
Segmentation réseau
La segmentation réseau dans un tel cluster n'est pas optionnelle. Le client opère sur l'infrastructure du fournisseur, mais le client ne doit jamais pouvoir voir le réseau plus large du fournisseur — ni le NAS du fournisseur, ni les interfaces d'administration du routeur, ni aucun autre locataire. De même, les systèmes internes du fournisseur ne doivent jamais être exposés aux charges du client.
Nous implémentons la segmentation en deux niveaux.
Niveau 1 — pare-feu edge. La edge-and-cache box exécute ufw (uncomplicated firewall) en posture default-deny entrant. Seul le port WireGuard UDP (51820) est exposé à Internet public. SSH, SMB, DNS, NTP et tout autre service exécuté sur l'edge sont liés aux interfaces internes et inaccessibles de l'extérieur du cluster. Les règles de forwarding autorisent les paquets entre l'interface WireGuard et le LAN du cluster, mais pas entre l'un ou l'autre et les autres réseaux internes du fournisseur. La posture de forwarding par défaut est de rejeter sauf autorisation explicite.
Niveau 2 — pare-feu hôte sur chaque nœud. Chaque nœud de rendu a sa propre configuration de pare-feu Windows qui reflète la posture edge — accepter l'entrant depuis les IP du cluster pour les services dont le cluster a besoin (SMB, bureau à distance, render manager) et rejeter tout le reste. Ce n'est pas redondant ; c'est de la défense en profondeur. Si un nœud est mal configuré ou compromis, le pare-feu hôte reste une barrière.
Le principe derrière les deux niveaux est le moindre privilège : le client et les nœuds ne doivent voir que le groupe de nœuds et rien d'autre. Nous ne donnons pas au client de routes générales vers le réseau interne du fournisseur. Le tunnel du client se termine à la edge box ; la edge box route uniquement vers le LAN du cluster ; le LAN du cluster route uniquement entre les membres du cluster.
En pratique, le client ne peut pas pinger ni scanner les autres systèmes du fournisseur, même s'il le voulait. Aucun plan de gestion partagé, aucun chemin de monitoring partagé qui expose d'autres locataires.
Leçons opérationnelles
Voici cinq leçons opérationnelles qui, sur chaque cluster dédié que nous avons monté, nous ont soit fait gagner des heures de débogage — soit, quand nous avons oublié de les appliquer, coûté des heures.
1. Piège de routage de passerelle dual-home. Quand la edge box a deux interfaces réseau (une publique, une LAN), l'ordre des opérations compte. La route LAN doit être configurée avant de changer la route par défaut. Si vous changez d'abord la route par défaut puis essayez d'ajouter la route LAN, la session SSH que vous utilisiez pour vous connecter peut tomber au moment du changement de route par défaut, et vous pouvez vous verrouiller hors de la box. La correction est procédurale, pas technique : toujours configurer d'abord les routes internes, les valider, et seulement ensuite toucher la route par défaut.
2. WireGuard et DNS. dnsmasq doit lister explicitement chaque interface qu'il doit écouter, y compris l'interface WireGuard. Si vous ne listez que l'interface LAN, les requêtes DNS depuis les clients VPN expirent — mais les réponses ping fonctionnent toujours, parce que ping ne passe pas par DNS. C'est l'un des modes de défaillance les plus trompeuses sur le plan diagnostique que nous ayons rencontrés. La correction est une ligne dans la configuration dnsmasq, mais il faut savoir où chercher.
3. Le clamping TCP MSS n'est pas optionnel à travers un tunnel. Les handshakes TLS, les sessions RDP, les lectures SMB de gros fichiers — tout ce qui veut envoyer de gros paquets — tombera silencieusement si MSS n'est pas clampé. Le premier symptôme est généralement « Moonlight fonctionne dix secondes, puis se fige » ou « SMB liste les répertoires mais ne peut pas lire les fichiers de plus de 1 Mo ». La correction est une règle iptables sur l'hôte WireGuard. Appliquez-la avant de remettre le cluster.
4. Dimensionner correctement le stockage, ne pas sur-ingénier. La version antérieure de cette architecture spécifiait RAID 10 avec chiffrement LUKS sur XFS. Le matériel de cache que nous déployons est un seul SSD. Nous avons retiré la couche RAID, retiré la couche LUKS, et utilisé ext4 — parce que le cache n'est pas la source de vérité, la plateforme cloud l'est. Échanger la redondance sur papier au niveau du cache contre une redondance réelle au niveau cloud était le bon choix. La leçon est de concevoir le stockage autour de ce que les données exigent réellement, pas autour de ce qui semble sûr dans un document de plan.
5. Pré-réchauffer le cache. À J-jour, chaque cache miss coûte un aller-retour sur le lien international et la plateforme cloud. La première heure de production sur un cache froid se sent lente même quand tout le reste est configuré correctement. Nous prévoyons désormais une fenêtre de pré-réchauffage dans chaque engagement — généralement un à deux jours avant le démarrage de la production. L'artiste ne voit pas le pré-réchauffage ; il voit un cluster qui est déjà rapide sur la première image.
Ces leçons sont opérationnelles, pas architecturales. Elles vivent dans la checklist de déploiement, pas dans le document d'architecture. Mais elles séparent un cluster qui fonctionne en théorie d'un cluster qui tient sous une charge de production réelle. Les patterns plus petits sont appliqués au cas par cas — les cinq ci-dessus sont ceux qui apparaissent sur chaque déploiement.
Conclusion
Une render farm GPU dédiée 20 nœuds transfrontalière est la bonne architecture quand le contrôle de la propriété intellectuelle est contractuel, l'engagement est pluri-mensuel, le workflow exige une configuration personnalisée, et l'authentification bring-your-own-cloud est non négociable. Hors de ces conditions, une render farm gérée est presque toujours la meilleure réponse — la complexité architecturale ici ne se justifie pas pour un travail axé projet ou pour des équipes sans fonction d'exploitation dédiée.
Quand les conditions s'appliquent, les patterns couverts ici — identifiants Model B, cache partagé sur ext4, transport WireGuard hub-and-spoke, BBR avec clamping MSS, Moonlight + Sunshine pour le bureau à distance, pare-feux à deux niveaux — sont ce que nous déployons par défaut. Ce ne sont pas les seuls patterns valides, mais ce sont ceux qui ont tenu à travers les déploiements.
L'équipe derrière Super Renders Farm opère à la fois la location de render farm gérée et les déploiements de cluster dédiés — y compris les configurations de cluster GPU dédié et les topologies transfrontalières décrites tout au long de ce guide.
FAQ
Q: Combien de temps prend un déploiement typique de cluster dédié 20 nœuds ? A: Selon la portée, la disponibilité matérielle sur le site et la configuration cloud de streaming du client, un engagement typique va de quelques semaines de délai pour le provisionnement matériel et réseau à une fenêtre de pré-réchauffage d'un à deux jours avant le démarrage de la production. Nous dimensionnons le calendrier sur le calendrier de production du client plutôt que sur un modèle fixe.
Q: Que se passe-t-il si mon équipe est répartie sur trois continents ? A: La topologie WireGuard hub-and-spoke s'adapte à des emplacements clients supplémentaires sans changer l'architecture du cluster. Chaque artiste distant exécute un client WireGuard et se connecte au même hub du site de cluster. La latence depuis chaque région est déterminée par le chemin internet public entre cette région et le hub ; dans notre expérience, BBR et le clamping MSS font la différence entre utilisable et inutilisable sur ces chemins.
Q: Puis-je voir le cluster depuis chez moi avant de m'engager sur plusieurs mois ? A: Nous arrangeons typiquement une fenêtre de preuve de concept pendant la conversation de cadrage. La forme exacte dépend du projet du client — parfois c'est une session bureau à distance sur un seul nœud pour tester l'expérience artiste, parfois c'est un petit test de rendu pour valider l'intégration cache et cloud de streaming. Les termes spécifiques sont une discussion commerciale ; contactez notre équipe commerciale pour discuter de ce qui conviendrait à votre calendrier.
Q: Comment la sécurité des données est-elle gérée à la fin de l'engagement ? A: Parce que Model B garde les identifiants client hors de nos mains, la clôture se concentre sur le nettoyage matériel et cache. Nous effaçons le cache SMB, ré-imageons chaque nœud depuis la base propre et fournissons une attestation écrite de destruction du cache et des images de nœuds. Le client révoque ses propres sessions cloud de streaming, ce qui est en dehors de notre système. Le libellé contractuel spécifique (NDA, SLA, formulation de la lettre d'attestation) est géré par notre équipe commerciale.
Q: Que faire si j'ai besoin de plus de 20 nœuds ? A: La configuration 20 nœuds est la forme la plus courante que nous déployons, mais l'architecture évolue au-delà. Des flottes plus grandes sont ajoutées dans le même site — des nœuds réservés supplémentaires se connectent au même hub WireGuard, au même cache SMB3 et à la même image Windows uniforme. La limite pratique est généralement la bande passante du cache : une seule edge-and-cache box a un plafond de lecture SMB fini, et pour de très grandes flottes l'architecture du cache elle-même doit être repensée (plusieurs cache boxes, caches régionaux). Nous discutons de ces choix de conception au cas par cas.
Q: Puis-je apporter ma propre licence pour Cinema 4D, Redshift ou d'autres outils DCC ? A: Le modèle de licence — bring-your-own-license ou fourni par le fournisseur — est une décision business qui dépend du DCC spécifique et de l'inventaire de licences existant du client. Certaines configurations fonctionnent proprement avec les licences du client ; d'autres sont plus simples avec celles du fournisseur. Nous réglons cela lors de la conversation de cadrage. Contactez notre équipe commerciale pour les détails.
Q: Comment gérez-vous le stockage cloud des fournisseurs UE versus US ? A: La plateforme cloud de streaming est le choix du client. Notre cluster intègre avec toute plateforme qui peut exécuter un client de connexion sur Windows et exposer l'arbre projet du client comme un système de fichiers monté. La localisation géographique du cloud en amont affecte la latence internationale du chemin client-vers-cluster — c'est pourquoi nous recommandons le transport WireGuard hub-and-spoke et la configuration BBR-tuned pour les configurations transfrontalières. Nous n'hébergeons pas la plateforme cloud elle-même ; elle reste sous le compte du client.
Q: Que se passe-t-il si le tunnel WireGuard tombe ? A: WireGuard rétablit automatiquement la session quand le réseau sous-jacent se rétablit ; la session bureau à distance du client peut faire une pause brève pendant le nouveau handshake. Si le tunnel tombe pendant qu'un rendu est en cours, le rendu lui-même continue de s'exécuter sur le nœud (il ne dépend pas du tunnel pour le travail en cours), mais le write-back vers le cloud sera mis en file d'attente jusqu'au rétablissement du tunnel. Nous surveillons la santé du tunnel depuis la edge box et alertons en cas de coupure prolongée.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



