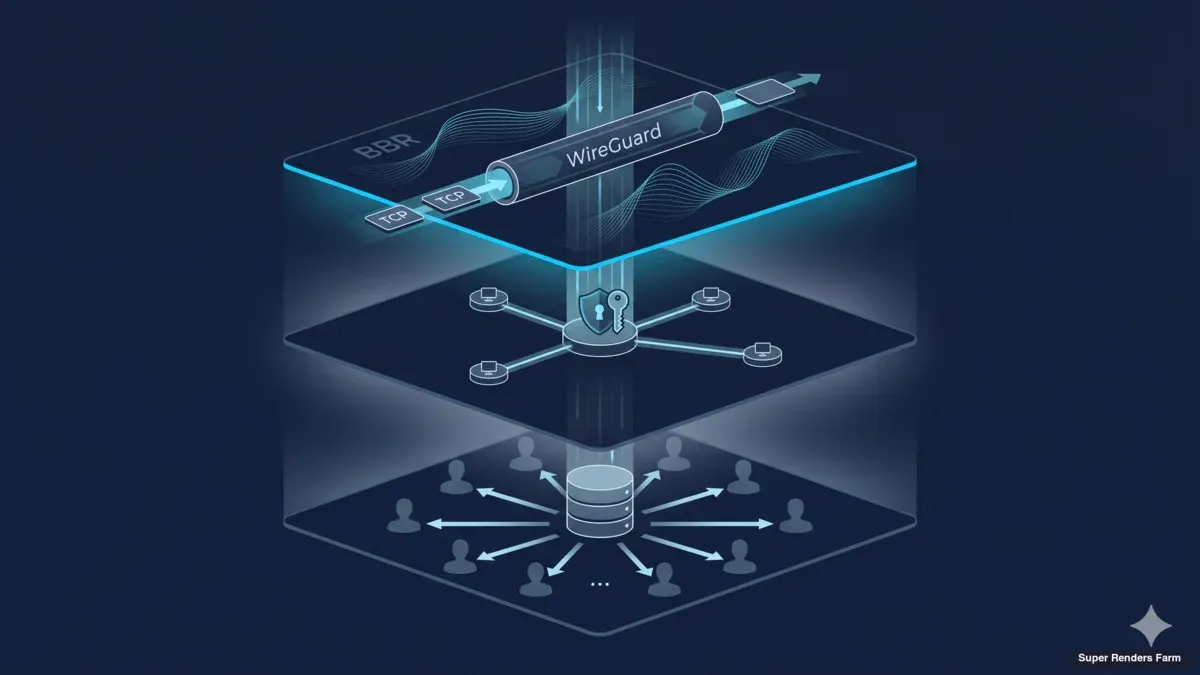
Cross-country render farm mimarisi: WireGuard, BBR ve paylaşımlı SMB cache
Genel bakış
Giriş
Tek bir rack içinde, tek bir odada, tek bir switch üzerinde yaşayan bir render farm kurmak çözülmüş bir problemdir. Kablo mesafeleri kısa, gidiş-dönüş süreleri mikrosaniye cinsinden ölçülür ve asset kütüphanesi her worker'ın switch port hızında okuduğu bir NAS üzerinde durur. Çoğu render farm rehberi bu topolojiyi sessizce varsayar, çünkü her şeyin sorunsuz çalıştığı topoloji odur.
Mimari, render farm birden fazla siteye yayılması gerektiğinde değişir. Aynı metropoliten alanda iki yere bölünmüş 20 node'luk bir cluster zaten farklı bir ağ problemidir; ülkeler arası uzanan bir cluster ise yine başka bir problemdir. Gidiş-dönüş süreleri milisaniyenin altından onlarca veya yüzlerce milisaniyeye uzar, kamu ISP rotalarındaki jitter sabit bir arka plan gürültüsüne dönüşür, herhangi iki endpoint arasındaki MTU bir varsayım yerine bir soru hâline gelir ve daha önce tek bir NAS'ta yaşayan asset kütüphanesi artık her siteye replike edilmek ya da talep üzerine cache'lenmek zorundadır. Naif yaklaşım — aynı NAS, aynı submission kuyruğu, aynı SMB share, sadece daha uzun kablolar — sessiz başarısızlık modları olarak ortaya çıkar: bağlantı kalan ama bir frame bile transfer etmeyen oturumlar, uzak bir node'a son asset push'u zaman aşımına uğradığı için yüzde 99'da takılıp kalan render submission'ları, lokal başarılı olup uzaktan belirgin bir sebep olmadan başarısız olan license check-out'ları.
Bu makale cross-country render farm deployment'ları için işlettiğimiz mimariyi anlatır — WireGuard hub-and-spoke topolojisi, TCP BBR congestion control, MSS clamping disiplini, paylaşımlı SMB3 cache katmanı ve sertleştirilmiş bir firewall yüzeyi. Bileşenler yaygın, konfigürasyon seçimleri her zaman aşikâr değil ve öğrenilen dersler bize çoğunlukla kimseye para kaybettirmeden önce debugging zamanı kaybettirdi. Hedef kitle, benzer bir build'i boyutlandıran altyapı mimarları ve DevOps mühendisleri, artı ekiplerinin neye girdiğini bilmek isteyen IT karar vericileridir. Aynı stack için adım adım operasyonel rehber için operational deployment guide sayfamız gün gün rollout sırasını kapsar. Daha üst düzey bir genel bakış için, cross-country render farm overview sayfası business case'i kapsar.
WireGuard hub-and-spoke topolojisi

İki uzak siteyi birbirine bağlayan şifreli tünel
Cluster'ın transport katmanı WireGuard'dır. Hem client bağlantıları için (sanatçıların workstation'larından farm'a) hem de ana datacenter ile ikincil site arasındaki site-to-site bağlantı için kullanırız. Topoloji hub-and-spoke'tur: bir WireGuard sunucusu ana datacenter gateway'inde çalışır, her client peer bu hub'a bağlanır ve ikincil site arkasında route'lanan bir subnet ile başka bir peer olarak bağlanır.
WireGuard'ın bu tür build için cazibesi çoğunlukla mekaniktir. Protokol sabit modern kriptografi kullanır (anahtar değişimi için Curve25519, data plane için ChaCha20-Poly1305, hashing için BLAKE2s), userspace yerine Linux kernel'inde çalışır ve tek bir ekrana sığan bir key-and-allowedips dosyası ile yapılandırılır. OpenVPN'e göre konfigürasyon yüzeyi yaklaşık bir büyüklük mertebesinde daha küçük, tipik bir Xeon node'unda throughput aynı CPU maliyetinde birkaç kat daha yüksek ve codebase audit'i pratik kılacak kadar küçük. IPsec'e göre ilginç biçimlerde başarısız olabilecek bir IKE müzakere fazı yok, rekey'de peer kimlik dansı yok ve crash edebilecek bir userspace daemon yok. Hepsini geçmiş deployment'larda işlettik; müdahale olmadan ayakta kalan konfigürasyonlar WireGuard olanlar.
Hub-and-spoke düzeni her site-to-site akışın ana datacenter gateway'inden geçtiği anlamına gelir. İki siteli cross-country bir deployment için bu doğru trade-off'tur: kamuya açık IP saldırı yüzeyini tek bir box'ta toplar, tek bir routing ve firewall kuralı setini tek bir darboğaz noktasına uygular ve her handshake ve her flow sayacı hub'da görünür olduğu için monitoring'i doğrudan kılar. Full mesh, site-to-site trafikte bir hop kazandırır ama konfigürasyon işini ve kamuya açık saldırı yüzeyini site sayısının karesi kadar çarpar. İki veya üç site için hub-and-spoke operasyonel basitlikte kazanır.
Hub UDP port 51820'de (varsayılan) dinler ve kamuya açık arayüzün kabul ettiği tek port budur. TCP fallback yoktur. Sadece-UDP kasıtlıdır — WireGuard'ın congestion davranışı UDP datagram'ları etrafında kurulmuştur ve TCP-üstüne-TCP tüneli uzun mesafe throughput'unu güvenilir şekilde bozar. UDP'yi tamamen bloklayan ağlarda bunu client tarafı kısıtlaması olarak ele alırız ve başka bir katmanda etrafından dolaşırız.
Her client peer, cluster'ın iç subnet'ini kapsayan tek bir AllowedIPs girişi ile yapılandırılır. Site-to-site peer, kernel'in hangi paketleri encapsule edeceğini bilmesi için uzak LAN subnet'ini kapsayan AllowedIPs taşır. PersistentKeepalive, NAT arkasındaki her peer'da 25 saniyeye ayarlanır; bu, handshake'ler arası UDP conntrack girişini canlı tutar. Bunu tam olarak bir kez atladık ve sonraki iki günü "ikincil sitede her 90 saniyede bir bağlantı düşüyor" diye debug ederek geçirdik; üçüncü sitede PersistentKeepalive config dosyasının ilk satırıydı.
TCP BBR congestion control
WireGuard tüneli ayağa kalktıktan sonra bir sonraki katman TCP davranışıdır. Linux varsayılan congestion control algoritması olarak CUBIC ile gelir. CUBIC, son loss olayından bu yana geçen zamanın bir fonksiyonu olarak congestion window'unu kübik bir eğride ölçeklendirir; bu, paket kaybının congestion için güvenilir bir sinyal olduğu link'lerde işe yarar. Tuzak "güvenilir" kelimesindedir. Uzun mesafe ISP rotalarında paket kaybı çoğu zaman hiç congestion değildir — ara bir router'daki queue overflow, TCP'ye görünmez şekilde retransmit yapan bir wireless link, yanlış yapılandırılmış bir rate-limiter veya bir routing transient'idir. CUBIC bunların hepsini congestion olarak ele alır ve darboğazda hâlâ kapasite olsa bile window'u çökertir.
BBR (Bottleneck Bandwidth and Round-trip propagation time), cross-country link'lerde kullandığımız alternatiftir. BBR paket kaybını birincil congestion sinyali olarak görmezden gelir ve bunun yerine yolun darboğaz bandwidth'ini ve minimum gidiş-dönüş süresini doğrudan ölçer. Sonra göndereniyi darboğaz oranında pace eder, window ise tam olarak bir bandwidth-delay product veriyi uçuşta tutacak boyutta. Long fat network'te — yüksek bandwidth, yüksek RTT, mütevazı rastgele loss — BBR pipe'ı dolu tutarken CUBIC congestion olmayan loss'lar için window'unu defalarca yarıya indirir.
Render farm üzerindeki pratik etki ölçülebilir. Aynı donanım üzerinde cross-country tünelinde asset transfer'leri CUBIC altında sık stall'larla dalgalı throughput'tan BBR altında yolun gerçek kapasitesine daha yakın daha düzgün bir throughput eğrisine geçer. Başlık rakamları ISP rotasına ve günün saatine göre değişir ama cluster gönderici tarafını BBR'ye geçirmek işlettiğimiz rotalarda tutarlı şekilde daha yüksek kalıcı durum throughput'u ve büyük transfer'lerde daha kısa tail latency üretmiştir.
Linux kernel mainline'da 4.9'dan beri olan BBR implementasyonunu kullanıyoruz, tek satır sysctl ile etkinleştirilir: net.core.default_qdisc=fq artı net.ipv4.tcp_congestion_control=bbr. Her iki satır da /etc/sysctl.d/99-bbr.conf içine girer ve reboot'tan sonra ayakta kalır. Mainline kernel BBR yıllardır production'da işlettiğimiz versiyondur. Algoritmanın daha yeni araştırma dalları mevcut ama spesifik ISP yollarımızda valide etmeye vaktimiz olmayan davranış değişiklikleri getiriyor; upgrade yolu ayrı bir roadmap maddesi.
BBR herhangi bir büyük akışın gönderici tarafında ayarlanır — asset transfer'leri için cache box ve render manager, license callback'leri ve log shipping gibi ters yönlü akışlar için alıcı tarafı. Bir uçta BBR faydanın çoğunu görmeye yeter; iki uçta BBR çift yönlü akışlarda biraz daha fazla yardımcı olur.
TCP MSS clamping
WireGuard tüneli ayağa kalktıktan sonra ortaya çıkan tüm ağ problemleri arasında bize en çok debugging zamanı kaybettirdiği: MTU. Semptom tutarlı ve kafa karıştırıcı: küçük paketler temiz geçer (varsayılan boyutta ping çalışır, SSH karakterleri eko eder, WireGuard handshake tamamlanır), ama büyük paketler tünelde kaybolur ve dışarı çıkmaz. TLS handshake'leri ortada askıda kalır. SMB oturumları bağlanır, ilk büyük read'de başarısız olur. RDP oturumları kurulur, login ekranı gösterir, kullanıcı bir şey yazınca donar. License sunucuları küçük token'ları check-out eder, büyük olanlarda timeout'a düşer.
Sebep, WireGuard tünelinin encapsulation overhead'i'nin endpoint'lerin LAN arayüzlerine göre müzakere ettiği path MTU'nun altına etkin MTU'yu indirmesidir. WireGuard her pakete 60 byte overhead ekler (20 IPv4 + 8 UDP + 32 WireGuard). LAN tarafında 1500 byte'lık bir payload kamuya açık tarafta 1560 byte'lık bir paket olur, yola bağlı olarak fragmente edilir veya düşürülür. Path MTU Discovery'nin (PMTUD) bunu göndereniye ICMP "Fragmentation Needed" döndürerek düzeltmesi beklenir, ama PMTUD modern internette rutin olarak kırılır — ICMP genellikle göndericinin upstream'inde filtrelenir, "daha küçük paketler kullan" sinyali asla ulaşmaz ve tünel büyük paketleri sessizce düşürür.
Çözüm TCP MSS (Maximum Segment Size) clamping'dir. Router tarafındaki WireGuard arayüzünü, tüneli geçen her TCP SYN içindeki MSS opsiyonunu yeniden yazıp tünelin etkin MTU'sundan TCP/IP overhead'ini düşen değere sınırlayacak şekilde yapılandırırız. 1420 byte tünel MTU'su ile (çoğu upstream MTU varyasyonunda hayatta kalan güvenli bir seçim), MSS clamp 1380'dir. Kural devreye girdikten sonra başlayan herhangi bir TCP bağlantısı 1380 byte MSS müzakere eder, gönderici tünelden temiz geçen 1420 byte'lık paketler emite eder ve sessiz drop'lar durur.
Clamp router-mode WireGuard host'unun FORWARD zincirine, wg0 arayüzü üzerinde, TCP handshake paketlerine uygulanır. iptables idiomu iptables -t mangle -A FORWARD -o wg0 -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu (veya sabit değer için --set-mss 1380) şeklindedir. nftables'in karşılığı var. Kural her iki tarafta da TCP bağlantısı başlatılıyorsa iki yönde de uygulanmalı; render farm'da bu yaygın durum.
Bir şey büyük bir başarısızlığa uğramadan MSS clamp eksikliğini hissetmek mümkün değildir — küçük workload'lar temiz test eder. Clamp, doğru uygulandığında hiçbir maliyeti olmayan ve atlandığında saatlerce karışık debugging üreten yapılandırmalardan biri. "SMB transfer'leri rastgele boyutlarda askıda kalıyor" şeklindeki sabah 6'lık destek bileti sabah 8'de bir satırlık iptables kuralıyla çözüldükten sonra standart deployment checklist'imize koyduk.
Paylaşımlı SMB3 cache tasarımı

Render worker'larına asset'leri yerel olarak sunan paylaşımlı cache
Render workload'ları asset-ağır ve read-baskındır. Tipik bir sahne birkaç yüz megabyte'tan birkaç onlarca gigabyte'a kadar uzanır — geometri, doku, simulation cache'leri ve rendering DCC'nin proje dosyaları. 20 node cluster genelinde aynı sahne, frame alan her worker tarafından okunabilir olmak zorundadır. Naif yaklaşım, sahneyi render başlamadan önce her node'a kopyalamaktır. 10 GB sahne ve 20 node ile bu, 10 GB working set için ağ üzerinden 200 GB taşır. Stüdyo başına günde onlarca sahneyle çarpın ve duplication maliyeti build'i domine eder.
Bunun yerine kullandığımız mimari, render worker'larına SMB3 üzerinden expose edilen, site başına tek bir paylaşımlı cache katmanıdır. Cache, ext4 formatlı tek bir SSD (NVMe sınıfı) ile bir Ubuntu 22.04 LTS box'tır; cache dizini Samba aracılığıyla SMB3 üzerinden expose edilir. Her render worker boot'ta cifs-utils üzerinden SMB share'i mount eder ve asset dosyalarını cache'ten yerelmiş gibi okur. Belirli bir asset'e ihtiyaç duyan ilk worker, upstream cloud asset store'undan cache'e bir pull tetikler; sonraki worker'lar ve sonraki frame'ler LAN cache'inden switch port hızında okur. Site başına cache box her worker'dan bir switch hop uzaktadır; asset cluster'a bir kez ulaşır ve yirmi worker'a hizmet eder.
Birkaç tasarım seçimi açılmayı hak ediyor. Cache RAID array değil tek bir SSD'dir çünkü cache tanım gereği upstream cloud asset store'undan yeniden inşa edilebilirdir. SSD arızalanırsa en kötü durum bir sonraki asset isteğinin cloud'dan çekmesi sırasında bir gecikme, artı cache'lenmemiş ara dosyaya bağlı olan herhangi bir uçuş halindeki render'ın yeniden inşası olur. "Uçuş halindeki render" riskini her iş sonunda biten render output'larını cache'ten bir NAS'a rsync ederek hafifletiyoruz, böylece SSD arızası teslim edilmiş herhangi bir deliverable'ı kaybetmez. RAID'i atlamak donanım maliyetini, controller karmaşıklığını ve bazı RAID seviyelerinin SSD'lere dayattığı write amplification overhead'ini kazandırır.
Dosya sistemi ZFS veya btrfs yerine ext4'tür. Geçmiş build'lerde hem ZFS hem btrfs kullandık ve getirdikleri feature set'ler (snapshot'lar, checksumming, sıkıştırma) bazı workflow'larda gerçek faydalardır. Bir render cache için okuma deseni çoğunlukla sıralı ve bandwidth-bound, transactional değil ve cache içeriği tasarım gereği atılabilir. Ext4 storage stack'ı basit tutar ve bir failure mode sınıfını incident postmortem setinden kaldırır. Zaten ölçekte ZFS işleten operatörler burada kesinlikle kullanabilir, ama cache katmanı basitliğinin bireysel feature kazanımlarından daha ağır bastığı bir deployment için ext4 tercih.
Pre-warm stratejisi önemlidir. Deadline-odaklı bir iş başlamadan önce sanatçı veya pipeline TD bir pre-staging aracı üzerinden sahnenin asset'lerini cache'e iter. Bir worker'a düşen ilk frame o zaman cold pull beklemek yerine sıcak cache'ten okur. Pre-warm adımı gece çalışan işler için opsiyoneldir (cold pull tamam) ve dar bir pencere içinde bitmesi gereken işler için önemlidir.
Cross-site cache paylaşımı WireGuard site-to-site tüneli üzerinden çalışır. İkincil sitenin kendi cache box'ı ve worker'ları vardır ama cache'i orada sıcak olan ve yerel olarak henüz sıcak olmayan herhangi bir asset için tünel üzerinden birincil sitenin cache'ine de ulaşabilir. Pratikte ikincil cache'i miss'lerde upstream cloud'a gitmeden önce birincil cache'e fallback yapacak şekilde yapılandırırız — bu inter-site trafiği şifreli tünelde tutar ve zaten farm içinde yaşayan asset'ler için cloud egress ücretlerinden kaçınır. Bu, doğru bir MSS clamp'in pratik faydalarından biridir: site'lar arasındaki büyük asset transfer'leri küçük paket tavanında stall etmek yerine tünel doyuran throughput'ta hareket eder.
Dahili servisler: DNS ve NTP
Bir cluster kendi hostname'lerini bilmelidir. Naif seçim her node'da /etc/hosts'a her host'u koymaktır; iki node ile çalışır, yirmide başarısız olmaya başlar. Doğru seçim dahili DNS'tir ve dnsmasq'ı WireGuard çalıştıran aynı gateway box'ta işletiriz. Cluster bir .lan zone'unda yaşar — cache.lan, rn-a01.lan ile rn-a20.lan arası, mgr.lan, nas.lan. Her ad cluster subnet'indeki ilgili dahili IP'ye çözümlenir ve her worker'ın /etc/resolv.conf dosyası dnsmasq sunucusunu işaret eder.
Faydası, herhangi bir IP yeniden ataması, host swap'ı veya topoloji değişikliğinin her node'a dokunmak yerine tek bir konfigürasyon dosyasını (dnsmasq hosts dosyası) düzenlemeyi gerektirmesidir. Fayda site-to-site tünel üzerine de uzanır: ikincil sitedeki bir worker cache.lan'ı yerel dnsmasq'ı üzerinden ikincil cache'e çözümleyebilir ve mgr.lan'ı tünel üzerinden DNS forwarding ile birincil sitenin render manager'ına çözümleyebilir. Geçmişte render manager yapılandırmalarında IP literal'leri kullandık ve bir node her hareket ettiğinde pişman olduk.
Bizi ısıran — ve kendi paragrafını hak edecek kadar yeterli operatörü ısıran — dnsmasq tuzağı interface= satırıdır. dnsmasq varsayılan olarak her arayüzde dinler; bu, gateway box'ın en az üçü olduğunu fark edene kadar iyi görünür: kamuya açık WAN, dahili LAN ve WireGuard tüneli wg0. interface=eth1'i dnsmasq'ı LAN ile sınırladığını düşünerek koyarsanız, WireGuard ile bağlı ikincil siteyi wg0 listelenmediği için herhangi bir .lan adını çözümleyemez hâle getirdiniz. Doğru satır interface=eth1,wg0 (veya arayüz adlarınız için karşılığı) veya yalnızca WAN'ı adlandıran bir except-interface= satırıdır. Bu yanlış yapılandırmanın "uzak site cache'i IP ile pingleyebiliyor ama hostname ile SMB-mount edemiyor" semptomunu birden fazla kez ürettiğini gördük.
NTP diğer dahili servistir. chrony'i gateway'de NTP sunucusu olarak işletiriz; gateway'in kendisi kamuya açık NTP pool'larına ve her node gateway'e senkronize. Motivasyon render manager log korelasyonu: bir frame başarısız olursa, render manager'ın log girişi ile worker'ın log girişi milisaniye içinde bir zaman çizelgesi paylaşmalı. Özellikle node'lar haftalarca up olduğunda 20 node'luk bir cluster'da clock drift, "bu log girişi tam uymuyor" debug karışıklığının gerçek bir kaynağı olur. chrony drift'i birkaç milisaniyenin altında tutar ve bu karışıklık sınıfını kaldırır.
Firewall: default-deny inbound ile ufw
Gateway kamuya açık internettedir ve firewall duruşu "default-deny inbound, default-allow outbound, tunneled trafik için default-allow forward"dur. Ubuntu 22.04 LTS'te kullandığımız araç ufw — Uncomplicated Firewall. ufw, nftables (eski sistemlerde iptables) üzerinde küçük bir komut yüzeyi açan ve sürpriz şeyler yapmayı reddeden bir frontend'dir. Firewall config'inin "güvenli" ile "saatler içinde compromise olmuş" arasındaki fark olduğu bir gateway box için küçük komut yüzeyi bir feature'dır.
Yapılandırılmış kamuya açık yüzey tek bir kuraldır: ufw allow 51820/udp comment 'wireguard'. Inbound başka bir şey yok. Kamuya açık taraftan SSH kapalı; gateway'i bilinen bir operatör IP'sinden WireGuard tüneli üzerinden yönetiriz. SMB, DNS, NTP ve HTTPS (render manager UI için) yalnızca dahili arayüzlerdedir. ufw default deny incoming ve ufw default allow outgoing ayarları yüzeyin geri kalanını kapsar.
Forward zinciri özen gerektirir. Gateway, wg0 ile dahili LAN arasında cluster trafiği için router olarak hareket eder ve ufw varsayılan duruşu forward'ı reddetmektir. /etc/default/ufw içinde DEFAULT_FORWARD_POLICY="ACCEPT" koyarız ve sonra forward kurallarını FORWARD zincirinde belirli source/destination çiftlerine daraltırız. Kombinasyon — default-deny incoming, boot'ta default-deny forward, sonra bilinen cluster subnet'leri arasında explicit forward ACCEPT'leri — denetlenebilir bir duruş verir ve birbiriyle konuşmaması gereken site'lar arasında yanlışlıkla trafik route etmez.
Per-node host firewall'ları bu Tier-1 gateway katmanını Tier-2 host katmanına genişletir. Her render node yerelde sadece cluster'ın render manager'ı ve cache box'ının bağlantı başlatmasına izin veren kurallarla ufw çalıştırır. Compromise olmuş bir worker önce host firewall'ı yenmeden başka bir worker'a pivot edemez ve gateway her beklenmedik forward girişimini loglar. İki tier'lı model — gateway Tier 1, per-host Tier 2 — herhangi bir makul on-prem cluster'ın işlettiğiyle aynıdır; cross-country bir deployment'ta değişen şey, Tier 1 yüzeyinin artık kamuya açık internete karşı savunması olmasıdır. Gateway perimeter; per-host firewall'lar derinlemesine savunma.
Mimari diyagramı

Hub-and-spoke render farm topolojisi, internete tek bir güvenli tünel
Yukarıdaki metin açıklaması, deployment kick-off'larda tahtaya çizdiğimizle aynı olan aşağıdaki ASCII diyagrama eşleşir:
PUBLIC INTERNET
|
| UDP 51820 (only port open)
v
+------------------------+------------------------+
| MAIN DATACENTER |
| |
| +----------------+ +---------------+ |
| | Gateway |--LAN-->| Render Mgr | |
| | (ufw + wg0 + | | (mgr.lan) | |
| | dnsmasq + | +---------------+ |
| | chrony + BBR) | |
| +-------+--------+ +---------------+ |
| | -->| Cache | |
| | | | (cache.lan) | |
| v | | SSD ext4 SMB3| |
| +----------------+ | +-------+-------+ |
| | Worker Subnet |<----+ | |
| | rn-a01..a20 | v |
| | (Tier-2 ufw) | +---------------+ |
| +----------------+ | NAS | |
| | (archive) | |
| +---------------+ |
+------------------+------------------------------+
| WireGuard site-to-site
| (BBR + MSS clamp)
v
+------------------+------------------------------+
| SECONDARY SITE |
| |
| +----------------+ +-----------------+ |
| | Site Gateway |----->| Local Cache | |
| | (wg0 spoke) | | (falls back | |
| +-------+--------+ | to primary) | |
| | +--------+--------+ |
| v | |
| +----------------+ v |
| | Worker Subnet | (renders run |
| | rn-b01..b08 | locally; outputs |
| | (Tier-2 ufw) | ship over tunnel) |
| +----------------+ |
+-------------------------------------------------+
Diyagram kasıtlı olarak geneldir — belirli bir şehir çifti, belirli bir ISP, belirli bir subnet numaralandırması yok. Deploy ettiğimiz her site aynı şekli izler; sayılar değişir.
Performans karakteristikleri
Throughput rakamları ISP rotasına ve günün saatine bağlıdır ama performansın şekli işlettiğimiz deployment'lar arasında tutarlıdır. Aynı metropolde iki site arasındaki bir tünelde (10 ms altı RTT), büyük transfer'ler darboğaz link'inde line-rate'e yakın hareket eder ve cache'ten okuyan bir render worker yerel diskten okuyan bir worker'dan ayırt edilemez hisseder. Farklı ülkelerdeki site'lar arasındaki bir tünelde (rotaya göre 50–150 ms RTT), büyük transfer'ler MSS clamp'in segment başına boyutu tünel MTU'suyla hizalı tuttuğu, darboğaz bandwidth'ine yakın BBR-pace edilmiş kalıcı bir throughput'a yerleşir.
Yerel LAN cache okuma, mimarinin ekmeğini kazandığı yerdir. Switched gigabit LAN üzerinde SMB3 ile cache.lan'tan 4 GB doku paketi okuyan bir render worker, kabaca switch port'un byte'ları itme süresinde biter — cross-country cloud storage'tan cold pull'un alacağı dakikalar yerine onlarca saniye. İki yüz frame boyunca aynı doku paketine dokunan bir iş için cache hit ratio ilk sıcak okumadan sonra 1,0'a yaklaşır ve cross-country tüneli yalnızca orijinal pre-warm, ikincil site output'larının cross-site sync'i ve kalıcı durum telemetrisi için kullanılır.
Özellikle 4K ve 8K render frame'leri için, mimarinin değeri frame boyutuyla ölçeklenir. Birden fazla AOV içeren 8K EXR sekansı, bireysel frame output'larını yüzlerce megabyte'a itebilir ve bunlardan 200'ü sahne başına on'larca gigabyte'lık bir yazıdır. Bu yazıyı yerel-LAN'da tutmak ve yalnızca son sıkıştırılmış output'u tünel üzerinden göndermek "gece bitirir" ile "yarın bir vakit upload bittiğinde biter" arasındaki farktır.
Sıkça Sorulan Sorular
Q: Neden WireGuard, OpenVPN değil? A: WireGuard'ın konfigürasyon yüzeyi daha küçüktür, aynı donanımda data plane throughput'u tutarlı olarak daha yüksektir, kernel implementasyonu bir userspace failure mode'unu kaldırır ve sabit cipher duruşu bir negotiation bug sınıfını kaldırır. OpenVPN yirmi yıllık operasyonel geçmişi olan sağlam bir araçtır; uzun süreli cluster tüneli için operasyonel özellikler bize önemli olan metriklerde daha iyi olduğu için WireGuard kullanıyoruz. WireGuard'ın UDP'sinin tamamen bloklandığı rotalarda OpenVPN TCP 443 üzerinden meşru bir fallback'tir — ama TCP-üstüne-TCP kendi patolojilerini getirir ve bunu client tarafı kısıtlaması olarak ele alırız.
Q: BBR gürültülü ISP rotalarında nasıl yardımcı olur? A: BBR congestion sinyali olarak paket kaybı yerine darboğaz bandwidth'i ve RTT'yi kullanır. Loss'un ara router'lardaki buffer overflow, wireless retransmit veya transient routing event'leri tarafından domine edildiği rotalarda — yani çoğu kamuya açık ISP rotasında — BBR, gönderici pace'ini congestion olmayan loss'lar için window'u defalarca yarıya indirmek yerine yolun gerçek bandwidth'inde tutar. Etki daha yüksek kalıcı durum throughput'u, büyük transfer'lerde daha kısa tail latency ve uzun akışlarda daha az "transfer otuz saniye durdu sonra devam etti" olayıdır.
Q: MSS clamping nedir ve neden ihtiyacım var? A: MSS clamping, TCP SYN paketlerindeki Maximum Segment Size opsiyonunu, müzakere edilen segment boyutunun azalmış etkin MTU'lu bir tünelden temiz geçecek şekilde yeniden yazar. Olmadan, endpoint'ler LAN arayüzlerine dayalı bir segment boyutu müzakere eder (tipik olarak MTU 1500, MSS 1460), WireGuard tüneli bu paketleri tam boyutta taşıyamaz, Path MTU Discovery upstream'de bir yerde ICMP filtrelendiği için başarısız olur ve büyük paketler sessizce kaybolur. Semptom "küçük paketler çalışır, büyükleri çalışmaz" — ping geçer, TLS handshake'leri askıda kalır, SMB transfer'leri dosya ortasında stall eder. Çözüm router tarafındaki WireGuard arayüzünde bir satırlık iptables veya nftables kuralıdır.
Q: Bu mimariyi kendim deploy edebilir miyim, yoksa bir render farm sağlayıcısına mı ihtiyacım var?
A: Mimari tamamen open source bileşenlerden inşa edilmiştir — WireGuard, Linux'un BBR implementasyonu, iptables/nftables, Samba SMB3, dnsmasq, chrony, ufw, ext4. SRF-only bileşen yok. Altyapı mühendisliği becerilerine sahip bir ekip aynı stack'ı kendi başına deploy edebilir ve bu makaledeki konfigürasyon seçimleri sır değildir; işe yaradıkları için yaptığımız seçimlerdir. Bir sağlayıcının getirdiği şey operasyonel deneyimdir — dnsmasq'ın interface= satırı gibi tuzaklar, MSS clamp keşif hikayesi, cache SSD'nin doğru boyutlandırılması, pre-warm tooling'i — her build'de yeniden keşfetmeyi gerektirmeyen bir deployment playbook'unda toplanmış. Bir ekibin bu deneyim eğrisini emmesi mi yoksa atlamak için satın alması mı tercih etmesi bir bütçe ve zaman çizelgesi sorusudur.
Q: Tipik render workflow'ları için cache hit ratio nedir? A: Aynı sahnenin birçok frame boyunca render edildiği frame-parallel workload'lar için (animasyon, VFX, archviz ve ürün görselleştirmedeki baskın patern), cache hit ratio her asset'in ilk sıcak pull'undan sonra 1,0'a yaklaşır. Cold pull cezası cache başına asset başına bir kez ödenir ve aynı sitedeki sonraki her worker LAN hızında sıcak cache'ten okur. Frame başına farklı bir asset set'ine dokunan workload'lar için (nadir ama bazı procedural workflow'larda olur), hit ratio daha düşüktür ve cache uzun vadeli store'dan ziyade transit buffer gibi davranır. Deadline-odaklı işlerden önceki pre-warm adımı, planlanan workload için hit ratio'yu etkili olarak 1,0 yapar.
Q: Bu mimari 20 node'un ötesine nasıl ölçeklenir? A: Hub-and-spoke WireGuard topolojisi peer sayısıyla doğrusal ölçeklenir — hub'ın CPU maliyeti peer başına crypto ve paket başına routing'tir ve modern bir Xeon gateway darboğaz olmadan önce yüzlerce peer'ı rahatlıkla kaldırır. Cache katmanı ya tek cache box'ı büyüterek (daha fazla SSD kapasitesi, daha hızlı NIC) ya da workload-bilinçli mount stratejisiyle birden fazla box'a sharding yaparak ölçeklenir. Site başına 50 node'un üstündeki build'ler için tipik olarak ikinci bir cache box ekleyip worker'ları aralarında böleriz; site başına 100 node'un üstünde, cache katmanı tek bir box yerine dağıtılmış read-replica tasarımına dönüşür ve bu başka bir makaledir. Cross-country tünelin kendisi cluster büyüdükçe mimari değişiklik gerektirmez — alttaki ISP link'inin kapasitesi olduğu sürece BBR pacing ve MSS clamp herhangi bir toplam akış oranında işlerini yapmaya devam eder.
Bu mimariyi ayağa kaldırdığımız deployment sırası hakkında daha fazla pratik detay için operational deployment guide sayfamıza bakın. Bu ağ tasarımının üzerine konan güvenlik duruşu için network segmentation security makalemiz Tier-1 ve Tier-2 firewall modelini daha derinden kapsar. Ve ilk seferde her zaman doğru yapmadığımız saha-test edilmiş edge case'ler için deployment lessons learned yazısı bu mimariyi şekillendiren spesifik failure mode'ları kapsar.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



