
Render Farm GPU'larını Nasıl Benchmark Yapıyoruz: Tekrarlanabilir Kare Başına Maliyet Yöntemi (2026)
Genel bakış
Giriş
Bir benchmark skoru yayımlamak kolaydır, ancak güvenilir olmak zordur. Herkes "RTX 5090: X puan" diyebilir; ama bir render işini bir kartta mı yoksa bir başkasında mı çalıştırmanın mantıklı olup olmadığına karar veren sayı, sentetik bir skor değil — kare başına maliyettir. Bu rakam sahnenize, render ayarlarınıza, render motoruna, sürücüye ve aritmetiği nasıl yaptığınıza bağlıdır; bunların neredeyse hiçbiri bir sıralama tablosu girişinde görünmez.
Bu sayfa bir metodoloji belgesidir, sıralama tablosu değil. Super Renders Farm olarak render farm GPU'larını nasıl benchmark ettiğimizi belgeliyor — böylece elde edilen sayı bir anlam taşıyor: benchmark sahnesini nasıl seçtiğimizi, hangi render ayarlarını sabitlediğimizi, donanım matrisi genelinde neyi sabit tuttuğumuzu, ham kare başına sürelerden savunulabilir bir kare başına maliyet rakamına nasıl ulaştığımızı ve — çoğu yazının atlayarak geçtiği kısım — üçüncü tarafların yöntemi kendi donanımlarında tekrarlayabilmesi için gerekli adımları aktarıyoruz. Bu yöntemin çıktılarını daha önce yayımladık; bu belgede ise bunların arkasındaki tarifi sunuyoruz. Aşağıda bir sayı belirdiğinde, bu gerçek bir çalışmadan alınan rakamı yansıtır ve burada yeniden türetilmek yerine işlenmiş örnek olarak aktarılır.
Sentetik benchmark'lar ile kare başına üretim maliyeti
GPU benchmark'lamanın iki katmanı vardır ve bu ikisini birbiriyle karıştırmak kafaların karışmasına yol açar.
Birincisi sentetik katman: tek bir sabit sahneyi render eden ve bir skor yayan standartlaştırılmış araçlar. Cinebench R24, Chaos V-Ray Benchmark ve OctaneBench bu kategoriye girer. Göreceli sıralama için kullanışlıdırlar — her makinede aynı tekrarlanabilir iş yükü çalıştığından kartları karşılaştırmak mümkündür. Bu puanları nasıl okuyacağımızı V-Ray benchmark rehberimizde ve Cinebench puanları ile bulut renderlamayı anlatan yazımızda açıklıyoruz. Sentetik bir skorun kasıtlı olarak dışarıda bıraktığı şey, üretimdeki her türlü değişkendir: geometriniz, örneklemeniz, denoiser'ınız, çıkış çözünürlüğünüz ve gerçek bir kuyruk sırasının taşıdığı iş başına ek yük.
İkincisi üretim katmanı: temsili bir gerçek karenin aslında ne kadar sürdüğü ve bunun ne kadara mal olduğu. Bu metodolojinin hedeflediği katman budur. Sentetik bir skor, bu katman için bir girdi niteliğindedir — başlangıç tahmini için kullanışlı bir yol — ancak son cevap değildir. İkisi arasındaki köprü prensipte basittir: aynı benchmark derlemesinde başka bir makineye göre yaklaşık iki kat puan alan bir makine, karşılaştırılabilir bir kareyi yaklaşık yarı sürede render eder. Bu tahmin aritmetiğini (verimlilik = kare süresi ÷ benchmark skoru) V-Ray rehberinde açıklıyoruz. Bir skor yerine bir benchmark yönteminin amacı bu ekstrapolasyonu dürüst kılmaktır — üretime yakın bir sahnede ölçüm yapmak ve salt bir orta noktayı değil, dağılımı raporlamak.
Önemli olan metrik: kare başına maliyet
Kare başına maliyet, bir metodolojinin ulaşması gereken birimdir; çünkü render bütçesinin yazıldığı birim budur. Formül basittir:
Kare başına maliyet = kare başına duvar saati süresi × saatlik node maliyeti
Kare başına duvar saati, görev süresi bölü kare sayısıdır; bu değer scheduler'dan ya da işin tamamı üzerinde kronometre ile ölçülür — sahne yükleme, hızlandırma yapısı oluşturma ve cihaz koordinasyonunu dışarıda bırakan render motoru dahili "render süresi" çıktısından değil. Saatlik node maliyeti ise donanımın bir saat çalıştırılmasının size ne kadara mal olduğudur; bu hesabı nasıl yaptığınız size kalmıştır. Render farm'ımızda GPU rendering işleri OctaneBench-saat başına $0,003 üzerinden faturalandırılır ve tek bir RTX 5090 (32 GB), kart-saat başına yaklaşık $5,2 donanım maliyeti taşır; müşteri açısından modeli kare başına maliyet rehberimizde ve fiyatlandırma rehberimizde ayrıntılı olarak ele alıyoruz.
İki girdiyi birleştirmek yalnızca birim aritmetiğidir: kare başına duvar saati süresini saate çevirin ve saatlik node maliyetiyle çarpın; böylece kare başına saniyeler ile saat başına dolarlar kare başına dolara dönüşür. Ucuz bir node'da kısa bir kare düşük çıkar; pahalı bir node'da ağır bir kare yüksek çıkar. İşlenmiş oranları bu metodoloji sayfasından kasıtlı olarak uzak tutuyoruz — gerçek maliyet sahne karmaşıklığınıza, örneklemenize, kuyruk bekleme süresine ve kullandığınız faturalama modeline bağlıdır; müşteri açısından rakamlar kare başına maliyet rehberimizde ve fiyatlandırma rehberinde ele alınmaktadır. Buradaki önemli nokta şudur: formül denetlenebilir niteliktedir — birimleri açıkça belirttiğinizde herkes, körü körüne kabul etmek yerine rakamı kontrol edebilir.
Kare başına maliyetin, sentetik bir skor yerine, temel metrik olmasının nedeni şudur: iki kart bir benchmark'ta benzer puan alabilirken kendi sahnenizde kare başına maliyetleri birbirinden belirgin biçimde farklı olabilir; çünkü sahne, her karenin ne kadarının paralelleştirilebilir iş, ne kadarının hız kazanımının etkileyemeyeceği sabit ek yük olduğunu belirler.
Benchmark sahnesi ve render ayarları
Sahne, bir benchmark'ın üretime transfer edilip edilmeyeceğini belirleyen en büyük kaldıraçtır; bu nedenle kasıtlı olarak iki farklı tür kullanıyoruz.
Makineler arası sıralama için satıcı standart sahneler. Amaç temiz bir elma-elma karşılaştırması olduğunda, yayımlanmış referans sahneler kullanıyoruz — Blender'ın Open Data sahneleri (bmw27, classroom, junkshop), Redshift için Maxon'ın Vultures sahnesi, Chaos V-Ray Benchmark ve OctaneBench. Bunlar tekrarlanabilir ve bağımsız olarak doğrulanabilir niteliktedir; sıralamanın tam da ihtiyaç duyduğu özellikler bunlardır. Zayıf yönleri ise sizin sahneniz olmamalarıdır; bu nedenle mutlak süreler doğrudan üretime aktarılamaz.
Kare başına maliyet için üretime temsili sahneler. Amaç bir operatörün planlama yapabileceği bir rakam olduğunda, sahnenin gerçek işe benzemesi gerekir — gerçek geometri, gerçek doku setleri, gerçek örnekleme, gerçek çıkış çözünürlüğü. Çok GPU ölçekleme çalışmamızda her render'ın güvenilir, kararlı bir oran üretecek kadar uzun sürmesi için Blender Cycles'ı %200 çözünürlükte çalıştırdık — bu da söz konusu ham Cycles sürelerinin genel Open Data puanlarıyla karşılaştırılamayacağı anlamına geliyor. Bu takas, yöntemin amaçlandığı şekilde çalıştığının kanıtıdır: sahneyi soruya göre ayarlayın.
Sahne ne olursa olsun, render ayarları sabitlenmeli ve kayıt altına alınmalıdır: örnek sayısı (ya da gürültü eşiği), denoiser açık/kapalı ve hangi denoiser olduğu, çıkış çözünürlüğü, tile/bucket boyutu ve render motoru derlemesi. Bu değerlerin makineler arasında değiştiği bir benchmark, donanımı değil; değişkeni ölçmektedir.
Donanım matrisi
Bir benchmark matrisi bir kılavuzdur: test edilen kartlar bir eksende, motorlar ve sahneler diğer eksende yer alır. Disiplin, kılavuz genelinde neyi sabit tuttuğunuzu belirlemede yatar.
Sabit tutulacaklar: işletim sistemi, render motoru sürümü ve derlemesi, denoiser, sahne ve ayarlar. Kayıt altına alınacak ancak her zaman eşleştirilemeyecek olan: GPU sürücüsü — güncel nesil bir kart bazen eski bir kartın çalıştıramayacağı daha yeni bir sürücü gerektirebilir, dolayısıyla tam sürücü eşleştirmesi mümkün değildir. Bu durumda, bunu açıkça belirtmek gerekir. Çok GPU çalışmasında RTX 5090 node'u sürücü 596.36 ile çalışırken RTX 4090 node'u 610.62 ile çalışıyordu; bu farkın yalnızca mutlak nesiller arası karşılaştırmayı etkilediğini, aynı kart ve sürücüyü kullanan node içi ölçekleme oranlarını etkilemediğini açıkça belirttik.
GPU filomuz 32 GB VRAM kapasiteli NVIDIA RTX 5090 kartlarda standartlaştırılmıştır; bu durum matrisimizi dahili olarak tutarlı kılar — tekdüze bir envanter, bir node'dan elde edilen bir tahmininin bir sonrakine aktarılabilmesini sağlar. Kart eksenine ilişkin işlenmiş bir örnek olarak, çok GPU çalışmasından tek kart sonucu; RTX 5090 ile RTX 4090'ın özdeş sahnelerdeki karşılaştırması:
| Motor / sahne | Metrik | RTX 5090 | RTX 4090 |
|---|---|---|---|
| Cycles — bmw27 | saniye (düşük daha iyi) | 49,45 | 77,40 |
| Cycles — classroom | saniye | 23,09 | 36,87 |
| Redshift — Vultures | saniye | 57 | 100 |
| V-Ray GPU (RTX) | vpaths (yüksek daha iyi) | 15.333 | 9.608 |
| Octane | OctaneBench skoru | 1.690,78 | 1.074,17 |
Bu tabloda iki farklı metrik türü yer almaktadır — saniye (düşük daha iyi) ve benchmark skoru (yüksek daha iyi) — mutlak sayıların motorlar arası karşılaştırma yapılmasına asla izin vermemesinin nedeni de tam olarak budur. Yalnızca tek bir motor içindeki oran elma-elma karşılaştırmasıdır.
Bir benchmark'ı güvenilir kılan kontroller
Bir sayı ile güvenilir bir sayı arasındaki fark, kontrollerdir. Yöntemimizin uyguladığı kontroller şunlardır:
- GPU başına tek görev. Zamanlayıcımız kart başına bir render görevi çalıştırır; böylece her rakam temiz bir kart başına sayıdır — kapasite planlamak için çarptığınız değer, paylaşılan bir cihaz üzerinde bulanık bir ortalama değildir.
- Her karşılaştırma için eşleştirilmiş çiftler. Üretimde donanım nesilleri karşılaştırıldığında, bir sahne ancak aynı sahne ve aynı kullanıcı her iki tarafta en az üç görev tamamladığında sayıma dahil edildi. RTX 5090 saha çalışmasında 1.419 görevden 38 sahne bu çıtayı aştı — 38, verinin boyutu değil, kasıtlı olarak katı bir filtreyi geçebilenlerin sayısıdır.
- Pencere başına tek sürücü. Saha çalışması boyunca yedi haftalık süreç boyunca tek bir sürücü (581.80, CUDA 13.0) sıfır değişiklikle çalıştı; böylece ortadaki hiçbir değişiklik sonucu kirletemedi.
- Denoiser eşitliği. Cycles işlerinin yaklaşık %83'ü hem yeni hem de önceki nesil donanımda yapay zeka denoising geçişi çalıştırdı — böylece denoiser, hız artışının içinde gizli bir değişken değil, sabit bir faktör haline geldi.
- Sıcak ile soğuk. Görev başına sabit maliyet — sahne yükleme, senkronizasyon, hızlandırma yapısı oluşturma — kısa bir karenin daha büyük bir fraksiyonudur; bu yüzden kısa, yüke bağlı kareler daha hızlı kartı olduğundan daha düşük gösterir. Yöntem bunu, tek bir çarpan varsaymak yerine dağılımı raporlayarak hesaba katar.
Ham sürelerden savunulabilir bir rakama
Süreler toplandıktan sonra istatistikler, sonucun dürüst olup olmadığına karar verir.
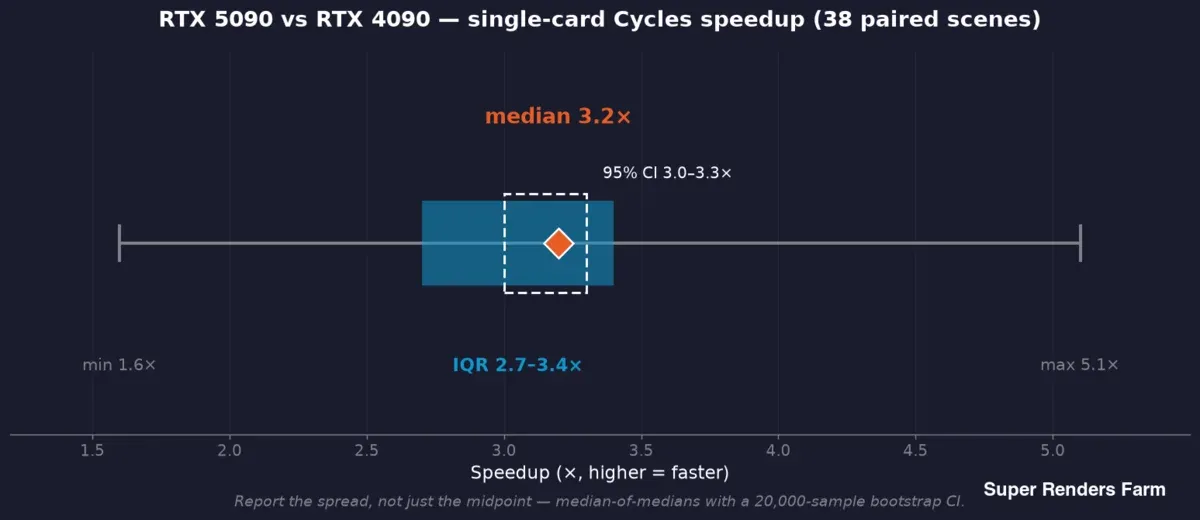
38 eşleştirilmiş sahnede RTX 5090 ile RTX 4090 tek kart Cycles hız artışı: medyan 3,2x, %95 güven aralığı 3,0 ile 3,3x, çeyrekler arası aralık 2,7 ile 3,4x, tam aralık 1,6 ile 5,1x
Medyanların medyanı kullanıyoruz: her sahne, her iki taraftaki kare başına sürelerinin kendi medyanını katkı olarak sunar ve ana başlık değeri, bu sahne başına oranların medyanıdır — böylece tek bir yavaş kare sonucu çarpıtamaz. Bu orta noktanın etrafında bir bootstrap güven aralığı raporluyoruz (saha çalışması, 3,0–3,3x %95 güven aralığıyla 3,2x medyan hız artışı için 20.000 örnekli bootstrap kullandı) ve dağılımı — çeyrekler arası aralık 2,7–3,4x, 38 sahne genelinde tam aralık 1,6–5,1x.
Bu yayılım ortalamayla giderilmesi gereken gürültü değildir; sonucun ta kendisidir. 3,2x tipik hız artışı ve 1,6x en kötü durum sahnesi aynı anda doğrudur; yalnızca orta noktayı raporlayan bir benchmark, bir operatörün ihtiyaç duyduğu hikayenin yarısını gizler. Tuttuğumuz kural şudur: medyanı ve aralığı raporlayın; her iddiayı destekleyen örneğe bağlayın — 38 eşleştirilmiş sahneden hız artışı, 57 kayıtlı işten VRAM, ayrı bir kontrollü bench çalışmasından güç tüketimi; asla bir örnek bir diğerini desteklemek için ödünç alınmaz.
Bu benchmark nasıl tekrarlanır
Bu kısım bir benchmark'ı pazarlama satırı yerine kazanılabilir bir sinyal haline getirir: herkes bunu çalıştırabilir. Aşağıdaki adımlar, yöntemi herhangi bir kuyruk veya test ortamında yeniden üretmektedir.
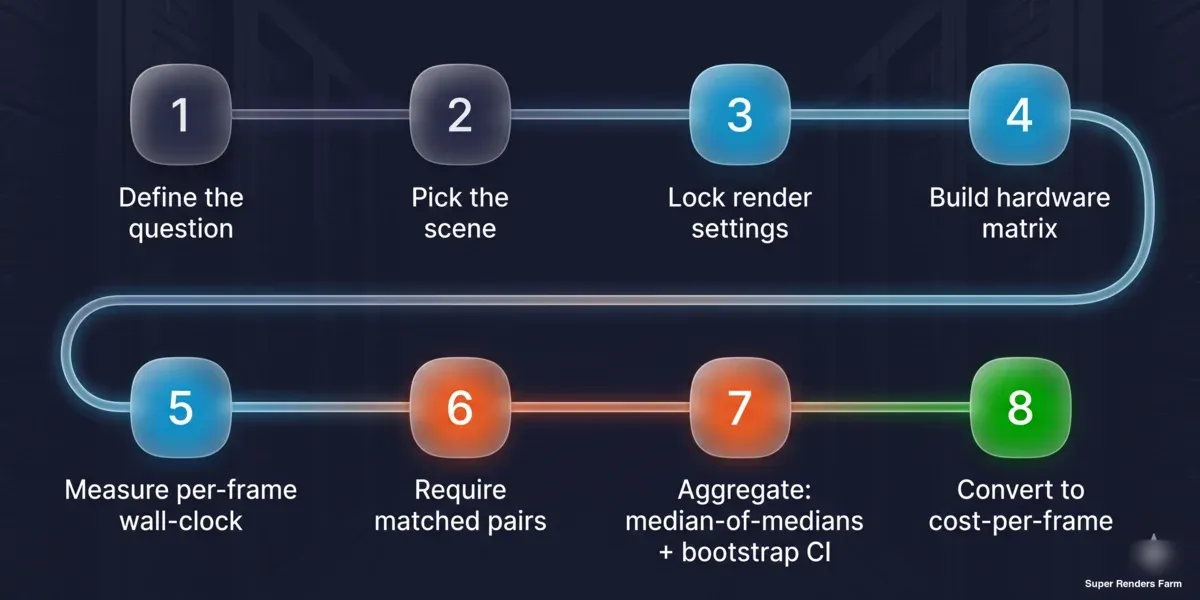
Sekiz adımlı tekrarlanabilir kare başına maliyet benchmark yöntemi: soruyu tanımlayın, sahneyi seçin, render ayarlarını kilitleyin, donanım matrisini oluşturun, kare başına duvar saatini ölçün, eşleştirilmiş çiftler isteyin, medyanların medyanı ve bootstrap güven aralığıyla toplayın, kare başına maliyete dönüştürün
- Soruyu tanımlayın. Makineler arası sıralama mı, yoksa kare başına üretim maliyeti mi? Cevap sahne türünü belirler — sıralama için satıcı standardı, maliyet için üretime temsili.
- Sahneyi ve ayarları sabitleyin. Örnek sayısını ya da gürültü eşiğini, denoiser seçimini, çıkış çözünürlüğünü, tile/bucket boyutunu ve render motoru derlemesini kilitleyin. Bunları yazıya dökün; sonucun bir parçasıdırlar.
- Matrisi oluşturun. Bir eksene kartları, diğer eksene motor/sahne kombinasyonlarını ekleyin. Neyin sabit tutulacağını (işletim sistemi, motor derlemesi, denoiser, sahne) belirleyin ve tutulamamayacakları (sürücü) kayıt altına alın.
- Kare başına duvar saatini ölçün. Scheduler'daki görev süresi ÷ kare sayısını ya da işin tamamı üzerindeki kronometre okumayı kullanın — yükleme ve derleme ek yükünü atlayan motorun dahili render süresi çıktısını değil.
- Eşleştirilmiş çiftler ve minimum örnek isteyin. Herhangi bir A-B iddiası için, sayılmadan önce aynı sahneyi her iki tarafta en az üç görev çalıştırın.
- Medyanların medyanıyla toplayın. Her sahnenin her iki taraftaki medyanını alın, ardından sahne başına oranların medyanını hesaplayın. Bootstrap güven aralığını hesaplayın; çeyrekler arası aralığı ve tam aralığı yanına ekleyin.
- Kare başına maliyete dönüştürün. Ölçülen kare başına süreyi saatlik node maliyetiyle çarpın. Rakamın denetlenebilir olması için birimleri açık tutun.
- Uyarıları rakamın yanına yayımlayın. Her iddiayı destekleyen örnek boyutunu, sürücü durumunu, verinin gözlemsel mi yoksa kontrollü mü olduğunu ve kapsamın neyi kapsayıp neyi kapsamadığını belirtin.
Bu sekiz adımı kendi donanımında uygulayan bir stüdyo savunabileceği bir rakama ulaşacak — ve bizimkini de karşılaştırabilecek; yöntemi yayımlamanın tüm amacı da budur.
Dürüstlük notları: bir benchmark neyi iddia edebilir, neyi edemez
Bir yöntem, reddettiği iddialar kadar güvenilirdir. Koruduğumuz üç çizgi:
Gözlemsel, kontrollü değildir. Üretim saha verisi — kullanıcıların normal iş akışlarında çalıştırdıkları işler — gerçek ve kullanışlıdır; ancak kullanıcılar kendi sahnelerini tekrar render etmeler arasında ayarlarlar, dolayısıyla gözlemseldirler. Temiz bir aynı host baş başa karşılaştırması (örneğin aynı donanımda RTX 5090'ın güncel RTX 4090'a karşı karşılaştırılması) ayrı, kontrollü bir çalışmadır. Birinin diğerinin yerine geçmesine izin vermiyoruz.
Node karşılaştırması sadece silikon değil, kurulumu da taşır. Bir taraf bare-metal üzerinde, diğer taraf sanallaştırılmış olarak çalışıyorsa, ölçülen farkın bir kısmı çip değil, kurulumdan kaynaklanır. Bu husus dipnot değil, ana başlık uyarısı olarak belirtilmelidir.
Ölçmediğimiz hiçbir rakam. Bench yapmadığımız güç veya termal değerleri ekstrapolasyon yoluyla türetmiyoruz. Saha çalışmamız kart başına yaklaşık 360–375 W raporladığında, bu rakam sürekli yük altında kontrollü bir bench çalışmasından elde edilmiştir — bundan türetilen kare başına enerji değeri ise bir ölçüm değil, bir çıkarım olarak etiketlenmiştir. Ölçülmemiş bir sayıyı yöntem icat etmez. Bu disiplin, yayımlanmış bir benchmark'a alıntı yapılabilmesinin nedenidir.
Render farm'ımızdan işlenmiş örnekler
Bu yöntem aşağıdaki çalışmaları üretti; her biri reçetenin yanında okuyabileceğiniz bir veri setidir ve gerçek sayıları yeniden türetmek yerine inceleyebileceğiniz yerdir.
| Çalışma | Yöntemin ürettiği | Örnek |
|---|---|---|
| Çok GPU ölçekleme | Satıcı standart sahnelerde motor başına 1x→2x ölçekleme | 2 node, 4 motor, 7 sahne/benchmark kombinasyonu |
| RTX 5090 saha notları | Üretim maliyet/hız dağılımı, VRAM yüzdelik dilimleri | 38 eşleştirilmiş sahne / 1.419 görev, 7 hafta |
| V-Ray benchmark rehberi | Sentetik skordan render süresi tahminine | Referans tablolar + işlenmiş tahmin |
| Bulut rendering için Cinebench | Donanım katmanları için sentetik skor yorumlama | Referans skorlar |
Aynı yaklaşım GPU cloud render farm'ımızdaki kapasiteyi nasıl planladığımızın temelini oluşturur; Blender'a özgü rakamlar ise Blender cloud rendering çalışmamızı beslemektedir — GPU, genel iş karışımımızın azınlık bir parçasıdır (farm işlerinin büyük çoğunluğu hâlâ CPU rendering'dir); bu yüzden bu GPU rakamlarını tam olarak öyle, yani farm genelindeki bir iddia olarak değil, GPU'ya özgü veriler olarak sunuyoruz.
FAQ
Q: Bir render farm GPU'sunu benchmark yapmanın doğru yolu nedir? A: Önce makineler arası sıralama mı yoksa kare başına üretim maliyeti mi istediğinize karar verin. Sıralama için, tekrarlanabilir bir satıcı standardı sahne ve sabit bir benchmark derlemesi kullanın. Kare başına maliyet için, üretime temsili bir sahne kullanın, kare başına duvar saatini ölçün (görev süresi ÷ kare sayısı) ve saatlik node maliyetiyle çarpın. Render ayarlarını kilitleyin ve tek bir sayı değil, dağılımı raporlayın.
Q: Kare başına maliyet neden bir benchmark skorundan daha iyidir? A: Sentetik bir skor, üretimdeki her türlü değişkeni dışarıda bırakır — geometriniz, örneklemeniz, denoiser'ınız ve çözünürlüğünüz — bu nedenle iki kart benzer puan alırken kendi sahnenizde gerçek kare başına maliyetleri birbirinden farklı olabilir. Kare başına maliyet, render bütçesinin yazıldığı birimdir; bu yüzden bir metodoloji, sıralama listesindeki bir puan yerine buna ulaşmalıdır.
Q: Bir benchmark skorunu render süresi tahminine nasıl çeviririm? A: Puanların oranını kaba bir hız oranı olarak kullanın: aynı benchmark derlemesinde başka bir makineye kıyasla iki kat puan alan bir makine, karşılaştırılabilir bir kareyi yaklaşık yarı sürede render eder. Makinenizin verimliliğini kare süresi bölü benchmark skoru olarak hesaplayın, ardından hedef makinenin skoru ile ölçeklendirin. Farklı derlemelerdeki puanlar karşılaştırılamaz olduğundan benchmark derlemesini sabit tutun.
Q: Bir GPU benchmark'ını güvenilir kılan kontroller nelerdir? A: Temiz kart başına sayılar için kart başına tek render görevi çalıştırın; eşleştirilmiş çiftler isteyin (her iki tarafta aynı sahne, sonuç sayılmadan önce minimum görev sayısı), sürücü ve motor derlemesini bir ölçüm penceresi içinde sabit tutun ve denoiser ayarını karşılaştırma genelinde aynı tutun. Ardından medyanların medyanıyla toplayın ve güven aralığını ve aralığı raporlayın.
Q: Güvenilir bir sonuç için kaç test sahnesi gereklidir? A: Gevşek kontrollü çok sayıda sahneden daha az, yüksek kaliteli eşleştirilmiş çift daha değerlidir. Üretim çalışmamızda 1.419 görevden 38 sahne, katı dahil etme filtresini (her iki donanım tarafında aynı sahne ve kullanıcı, taraf başına en az üç görev) geçebildi. Önemli olan örnek boyutu, filtreyi geçenlerdir; ham görev sayısı değil — ve her ikisini de raporlamalısınız.
Q: Render farm GPU benchmark'ınızı kendim tekrarlayabilir miyim? A: Evet — amaç da budur. Bir sahneyi ve ayarlarını sabitleyin, işletim sistemi, motor derlemesi ve denoiser'ı sabit tutarak bir donanım matrisi oluşturun, kare başına duvar saatini ölçün, eşleştirilmiş çiftler isteyin, medyanların medyanı artı bootstrap güven aralığıyla toplayın, kare başına maliyete dönüştürün ve uyarıları rakamın yanına yayımlayın. Yukarıdaki sekiz tekrarlama adımı tam sırayı ortaya koymaktadır.
Q: Tek bir hız artışı sayısı yerine neden bir aralık raporluyorsunuz? A: Çünkü aralık sonucun bir parçasıdır. Aynı donanım, kısa, yüke bağlı bir sahnede 1,6x kazanım gösterirken ağır hesaplamaya bağlı bir sahnede 5x'in üzerinde gösterebilir; çünkü sabit kare başına ek yük, kısa bir render'ın daha büyük bir fraksiyonudur. Yalnızca orta noktayı raporlamak, bir operatörün kapasite planlamak için ihtiyaç duyduğu değişkenliği gizler; bu yüzden medyanı, çeyrekler arası aralığı ve tam aralığı birlikte yayımlıyoruz.
About Richard Ta
Richard Ta is co-founder and technical lead of Super Renders Farm (superrendersfarm.com), a fully managed cloud render farm that supports Maya, 3ds Max, Cinema 4D, Blender, and Houdini across the major render engines. He has spent over a decade building and running large-scale CPU and GPU render infrastructure for studios in more than 50 countries.



