
RTX 5090 Üretimde: 7 Haftalık Render Farm Saha Notları (38 Sahne Çalışması)
Genel bakış
RTX 5090 için yapılan tanıtım testleri bir yılı aşkın süredir gündemdedir ve hepsi aynı şeyi anlatır: tek kart, tek hazırlanmış sahne, ideal koşullar. Neredeyse hiç kimsenin yayımlamadığı şey ise devamıdır: kart, kontrol etmediği bir programda başkalarının sahnelerini render eden canlı bir kuyruğa girdiğinde neler yaşanır? Biz logları inceledik. Aşağıdakiler kuyruk düzeyindeki saha notlarıdır: kapasiteyi planlarken kullandığımız üretim verilerinin aynısı, kontrol edebileceğiniz rakamlarla sunulmuştur.
Bu, yedi haftalık bir süreçtir. 1 Nisan – 22 Mayıs 2026 tarihleri arasında — 51 gün boyunca — canlı render farm altyapımızın içinde tek bir çift RTX 5090 node çalıştırdık ve kuyruğun ne getirirse onu render etmesine izin verdik. Hazırlanmış test yok, seçilmiş kareler yok. Aşağıdaki kısa video temel rakamları özetliyor; tam saha notları onu takip ediyor.
Node'un kendisi sıradan bir yapıdadır: iki RTX 5090, 128 GiB RAM, 4.3 GHz'de 32 mantıksal çekirdek, Windows 11. Buradaki her rakamı şekillendiren tek bir ayrıntı var: zamanlayıcı GPU başına tek bir render görevi çalıştırır; dolayısıyla her kart kendi işini render eder ve her rakam, kapasite planlamak için çarptığınız temiz bir kart başı sayıdır. Pencere boyunca node, görevlerinin %99.6'sını tamamladı — yaklaşık 4,900 görevin 4,890'ı tamamlandı, 18'i başarısız oldu. Zamanlayıcı başarısızlığı kayıt altına alır ama nedenini değil; bu yüzden biz de tahmin yürütmeyeceğiz.
Temel rakamlar
- Pencere: 1 Nisan – 22 Mayıs 2026 (51 gün, ~7 hafta), tek çift RTX 5090 node
- Tamamlanma: %99.6 — ~4,900 görevin 4,890'ı tamamlandı, 18'i başarısız (neden kayıt altına alınmadı)
- Hız artışı: önceki nesil RTX 3080/2080 sınıfı node'larla karşılaştırıldığında Blender Cycles'ta kare başına medyan 3.2x (kare başına medyan süre ~%69 düştü); %95 CI 3.0–3.3x
- Dağılım: IQR 2.7–3.4x, 38 eşleştirilmiş sahne boyunca tam aralık 1.6x–5.1x — tek bir çarpan asla bir kuyruğu tanımlamaz
- AI denoising: Cycles işlerinin ~%83'ü bir AI denoising geçişi çalıştırdı — eski donanımla aynı oran
- VRAM: medyan 5.6 GB, 90. yüzdelik 11.5 GB, en ağır iş ~37 GB
- Sürücü: pencere boyunca tek sürücü (581.80 / CUDA 13.0), sıfır değişim
- Güç: yük altında kart başına ~360–375 W (kontrollü test), ~400 W'a kadar çıkıyor, 68–83 °C'de — ~575 W'lık anma sınıfının çok altında
38 eşleştirilmiş sahnenin gösterdikleri
En çok güvendiğimiz karşılaştırma yapay bir test değil, normal iş akışı içinde her iki nesilde de çalışan işlerdir: aynı sahne, aynı kullanıcı, bir sahnenin sayılabilmesi için her tarafta en az üç görev. Kare başına süre, doğrudan kuyruktan alınan görev duvar saatinin kare sayısına bölümüdür. Pencereden 38 sahne bu filtreyi geçti ve 1,419 bireysel render görevinden türetildi (5090 node'unda 503, önceki nesilde 916). Otuz sekiz, verimizin büyüklüğü değil; kasıtlı olarak katı bir filtreden hayatta kalanların sayısıdır.
| Metrik | Değer |
|---|---|
| Medyan kare başına hız artışı | 3.2x (≈%69 süre düşüşü) |
| Bootstrap %95 CI (medyan) | 3.0–3.3x |
| Çeyrekler arası aralık | 2.7–3.4x |
| Tam aralık | 1.6–5.1x |
| Sahneler / görevler | 38 sahne / 1,419 görev |
| Taban | önceki nesil RTX 3080/2080 sınıfı (10–12 GB) |
Medyanların medyanını kullanıyoruz: her sahne, her iki taraftaki kendi kare başına sürelerinin medyanını katkıda bulunur ve 3.2x, bu 38 oranın medyanıdır; böylece tek bir yavaş kare sonucu çarpıtamaz. Dağılım, orta nokta kadar önemlidir — sahnelerin orta yarısı 2.7x ile 3.4x arasında yer alır ve tam aralık 1.6x'ten 5.1x'e uzanır.
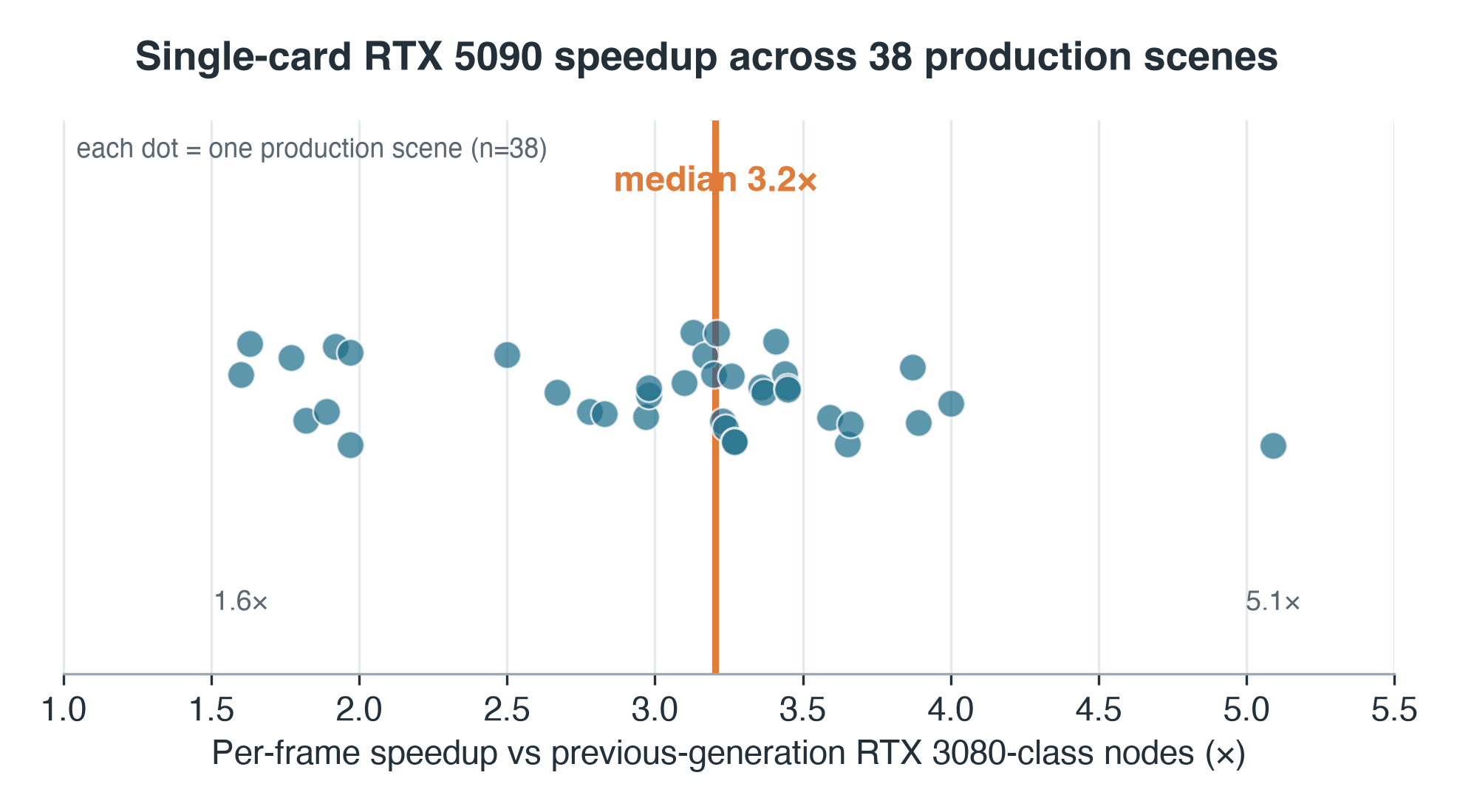
38 Blender Cycles üretim sahnesi boyunca sahne başına RTX 5090 hız artışı, medyan 3.2x, 1.6'dan 5.1x'e kadar dağılım
Sahne başına hız artışı, RTX 5090 ile bu işlerin çalıştığı önceki nesil node'lar karşılaştırması — 38 sahnelik üretim örneği. Medyan 3.2x; aralık 1.6–5.1x.
Bu rakamla birlikte dipnotta değil, ana metinde belirtilmesi gereken iki çekince var. Birincisi, önceki nesil taraf sanallaştırılmış olarak çalıştı — bir VM içinde GPU passthrough — dolayısıyla bu 3.2x'in ölçülemeyen bir payı, ham silikon değil, sanallaştırma ek yükünden kaynaklanmaktadır; temiz aynı ana makine karşılaştırması, yani RTX 5090'ın mevcut bir RTX 4090'a karşı testi, henüz yapmadığımız kontrollü bir takip çalışmasıdır. İkincisi, 38 sahne kuyruktan rastgele bir seçim değildir: bunlar, normal iş akışı içinde bir kullanıcının her iki nesilde de render ettiği işlerdir ve bu durum, örneği daha uzun, tekrarlı çalışmalara doğru kaydırır — bu nedenle dağılımı eşleştirilmiş çiftlerin dağılımı olarak okuyun, tüm kuyruğun değil.
Burada üç dürüstlük notu kritik öneme sahiptir. Bu gözlemsel verilerdir — kullanıcılar bazen render'lar arasında ayarları değiştirir ve biz sahnelerini dondurmadık. Karşılaştırma node'dan node'a yapılmaktadır: 5090 tarafı tek bare-metal karttır, önceki nesil taraf ise sanal makineler içinde GPU passthrough olarak çalışmaktadır; dolayısıyla farkın bir kısmı kurulum farklılığından kaynaklanmaktadır, silikondan değil. Taban ise bu işlerin gerçekten üzerinde çalıştığı RTX 3080/2080 sınıfı kartlardır — mevcut bir RTX 4090 değil; temiz mevcut kartla başa baş karşılaştırma, henüz yapmadığımız ayrı bir kontrollü çalışmadır. Bunlar tek node, yalnızca Cycles rakamlarıdır; kendi kuyruğumuzu tanımlamaktadır ve diğer render motorlarına veya donanımlara genellenmemelidir.
1.6x ile 5.1x arasındaki fark, kısmen veride görünürdür. Her sahnenin hız artışını eski donanımda karelerinin ne kadar sürdüğüne karşı çizin; gevşek bir pozitif trend ortaya çıkar — Spearman ρ ≈ 0.34 (iki yönlü p ≈ 0.04). Kısa, ek yük sınırlı kareler altta yer alır: bir kare beş saniyede tamamlandığında, görev başına sabit maliyet — sahne yükleme, senkronizasyon, eski sanallaştırma katmanı — saatin büyük bölümünü yer, ve daha hızlı bir kartın yapacağı az şey kalır. Daha ağır, hesaplama sınırlı kareler daha fazla kazanır. Ama gerçek bir dağılım var: bir ağır sahne yalnızca 1.6x'te kaldı çünkü darboğazı GPU değil, depolama ya da CPU sınırlı bir aşamaydı. Medyan bir şey söyler; aralık ise bunun sahneye bağlı olduğunu söyler.
AI denoising zaten varsayılandı
2026'da bir üretim rendering pipeline'ında AI'nin gerçekte nerede yer aldığını sorduğunuzda loglarımız pek parlak bir yanıt vermez: denoiser'da. Cycles işlerinin yaklaşık %83'ü 5090 node'unda bir AI denoising geçişi çalıştırdı — OptiX veya Intel Open Image Denoise — ve önceki nesil node'larımızdaki oran özünde aynıdır. Yeni kart bu alışkanlığı başlatmadı; eski donanımda zaten standart hâle gelmişti ve yeni donanımda da standart kaldı. Denoising yoğun bir pipeline için, nesil atlamak, zaten orada olan "AI" satın almak değildir — zaten rutin bir adımın etrafındaki path-tracing verimini satın almaktır. Bu rakam kasıtlı olarak Cycles kapsamlıdır; bir render motoruna bağlı olmayan çiftlik genelinde "AI yüzdesi" iddialarına şüpheyle yaklaşın.
Gerçek ortamda VRAM
Cycles, render logunun içine en yüksek cihaz belleği rakamını yazar — üretimin VRAM'den gerçekten ne talep ettiğine dair mütevazı ama kullanılabilir bir yaklaşık gösterge. Bu satırın kaydedildiği 57 Cycles işi boyunca, pik render cihazı belleği medyanda yaklaşık 5.6 GB, 90. yüzdelikte ise 11.5 GB civarındaydı. Önceki nesil kartlarımız 10–12 GB'lık parçalar; dolayısıyla medyan iş sığardı — ama 90. yüzdelik iş, tavanlarına zaten yaklaşıyordu. Kuyruk daha da uzanır: en ağır iş yaklaşık 37 GB logu, 5090'ın kendi 32 GB'ının bile ötesinde — GPU'da bunun anlamı CPU fallback'i ya da hiç render edilememesidir. Logda sahne meta verisi bulunmuyor, dolayısıyla bunun ne tür bir sahne olduğunu söyleyemeyiz — yalnızca sınıfını söyleyebiliriz: 37 GB çalışma kümesi, ağır geometrinin, yüksek çözünürlüklü doku setlerinin ya da volumetrik öğelerin imzasıdır; tek bir GPU'da basitçe durur. Operatör kuralı hâlâ geçerlidir: VRAM'i kuyruk için değil, uç değere göre boyutlandırırsınız. Bu yüzden hem aşırı büyük kart başı bellek hem de paylaşımlı GPU cloud render farm kapasitesi vardır — iş başına daha büyük bir karta ulaşabilmeniz için, bir tane satın almanıza gerek kalmadan.
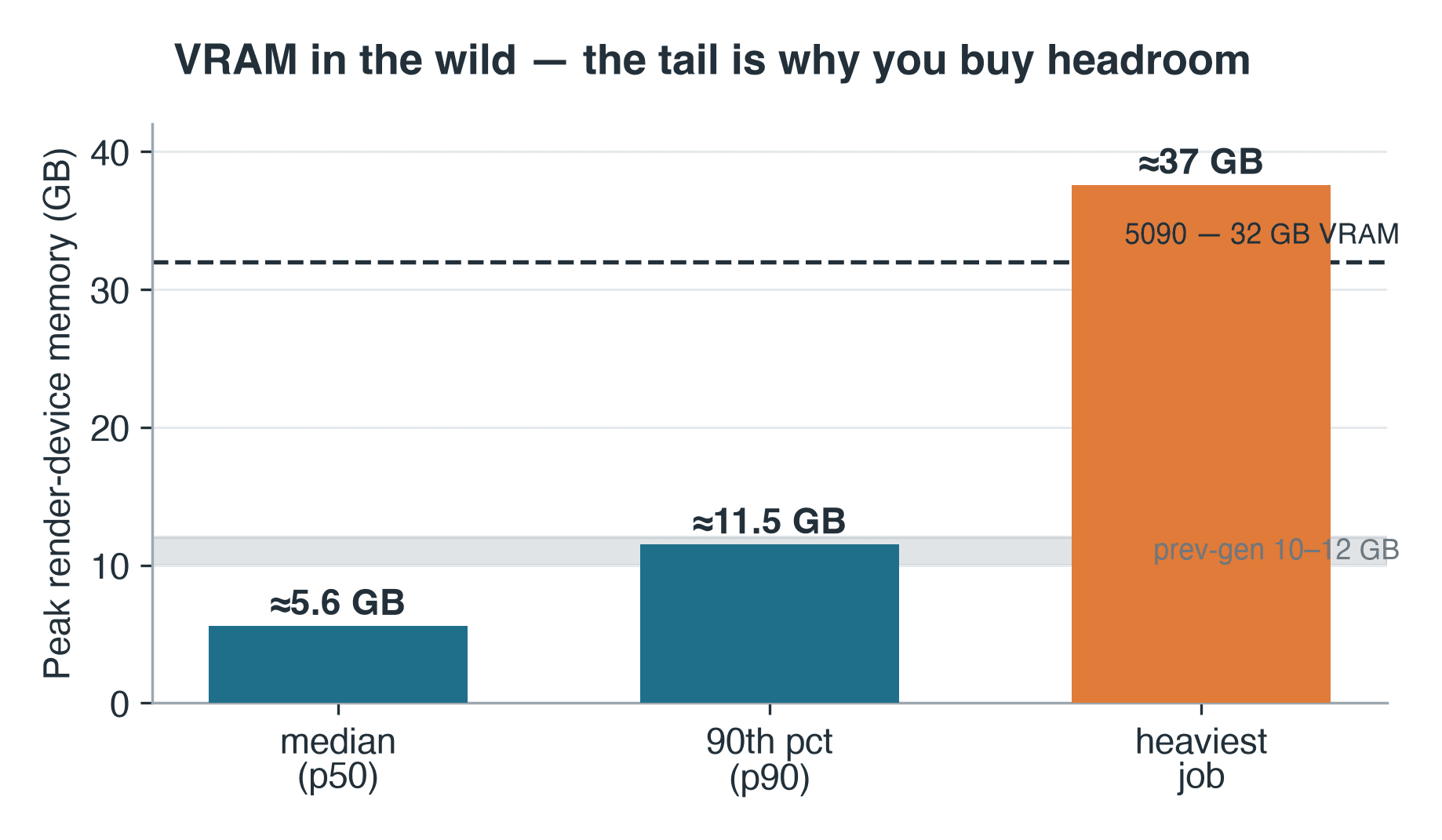
Blender Cycles işleri için RTX 5090 node'undaki pik render cihazı belleği: medyan 5.6 GB, 90. yüzdelik 11.5 GB, en ağır 37 GB
57 kayıtlı Cycles işi boyunca pik render cihazı belleği. En ağır iş, 5090'ın kendi 32 GB'ını bile aştı.
Tek sürücü ve sınırlı güç
En az çarpıcı bulgu, satın almadan önce en çok isteyeceğimiz bulgudur. Tek bir sürücü — CUDA 13.0 üzerinde 581.80 — tüm pencere boyunca sıfır değişimle çalıştı: geri alma yok, pencere ortasında takas yok. Üretim kuyruğunda erken dönem donanım için sıkıcı bir sürücü logu, bir iltifat niteliği taşır.
Güç de benzer biçimde sakin kaldı. Sürekli yük altında aynı kartların kontrollü test çalıştırmasında her biri yaklaşık 360–375 W çekti (~400'e kadar çıktı) ve 68–83 °C'de çalıştı — üst üste dizilmiş çiftte en üstteki kart en sıcak çalıştı, ama ~575 W'lık anma sınıfının çok altında. Bu sürekli çekim için bütçeleyin, anma tepesine göre değil. Tamamlanan kare başına enerji, yaklaşık 24 saniyelik medyan Cycles karesinde kabaca 2.5 Wh olarak hesaplanır — ama bunu bir çıkarım olarak değerlendirin: bu test çekimine dayanmaktadır ve yalnızca 5090 için hesaplanmıştır, eski node'lara karşı ölçülmemiştir.
Bu notların neden Blender ile başladığı
Son 90 gün içinde GPU işleri, çiftliğimizin render ettiğinin yaklaşık dörtte birini oluşturuyordu — geri kalanı CPU çalışmasıdır. GPU karışımı içinde, Cycles işlerin yaklaşık %74'ünü oluşturur ve Redshift yaklaşık %15 ile net ikinci sıradadır; bu yüzden bir render farm RTX 5090 yazısı Blender cloud rendering ile başlar. Bu kartların birden fazlasının birlikte nasıl davrandığına ilişkin kardeş notlarımız için RTX 5090 küme performansına bakın; bellek sınırına özgü olarak ise karmaşık sahnelerde VRAM sınırlarının nerede ısırdığına bakın.
Bu kuyruktan iki çıkarım öne çıkıyor. Birincisi, üretim bir test değildir — temiz bir laboratuvar sonucu veren kart, hâlâ sanallaştırma ek yükünü, karışık iş yüklerini ve hiç optimize edilmediği sahneleri absorbe etmek zorundadır; sonuç bir nokta değil, bir dağılımdır. İkincisi, medyan kuyruk değildir. 3.2x tipik hız artışı ve tek işte 37 GB bellek tepkisi aynı anda doğrudur ve her ikisi etrafında kapasite planlaması yaparsınız. Kart, iş ağır olduğunda gerçekten hızlıdır. Olmadığında ise kuyruk size nedenini söyler.
Kısaca yöntem
Buradaki her rakam, hazırlanmış bir testten değil, zamanlayıcımızın kendi görev kayıtlarından gelmektedir. Kare başına süre, görev duvar saatinin kare sayısına bölümüdür; temel hız artışı 38 eşleştirilmiş çift boyunca sahne başına medyanların medyanıdır ve güven aralığı 20,000 örnekli bir bootstrap'tır. Hangi örneğin hangi iddiayı desteklediğine dikkat edin: hız artışı için 38 eşleştirilmiş sahne, VRAM için 57 kayıtlı iş ve güç ile termal için ayrı bir kontrollü test çalıştırması — üretim kuyruğu değil. Başarısız olan 18 görev (yaklaşık 4,900 içinde) başarısızlık olarak sayılır, düşürülmez; zamanlayıcı durumu kaydeder ama nedeni kayıt altına almaz, bu yüzden tahmin yürütmek yerine olduğu gibi bırakıyoruz. Bunların hiçbirini özünde çoğaltmak zor değildir — herhangi bir operatörün kendi kuyruk loglarından çıkarabileceği şeylerdir ve bir stüdyoya yöntemi daha ayrıntılı anlatmaktan memnuniyet duyarız.
FAQ
Q: RTX 5090, Blender Cycles için önceki nesle kıyasla ne kadar daha hızlı? A: 38 eşleştirilmiş üretim sahnesi boyunca (her iki nesilde de aynı sahne ve kullanıcı), kare başına medyan süre yaklaşık %69 düştü — bootstrap %95 güven aralığı 3.0–3.3x olan medyan 3.2x hız artışı. Bireysel sahneler 1.6x ile 5.1x arasında değişti. Bu gözlemsel, node'dan node'a verilerdir, kontrollü bir test değildir.
Q: Sahneler arasındaki hız artışı neden bu kadar değişken? A: Hız artışı, kare başına iş yüküyle gevşek bir pozitif trend izler (Spearman ρ ≈ 0.34). Kısa, ek yük sınırlı kareler en az kazanır çünkü görev başına sabit maliyet — sahne yükleme, senkronizasyon, eski sanallaştırma katmanı — baskın gelir; daha ağır, hesaplama sınırlı kareler daha fazla kazanır. Bir ağır sahne 1.6x'te kaldı çünkü darboğazı GPU değil, depolama ya da CPU sınırlı bir aşamaydı.
Q: Bu, kendi donanımımla karşılaştırabileceğim kontrollü bir test mi? A: Hayır. Bunlar tek bir canlı üretim node'undan, yalnızca Blender Cycles için gözlemsel saha notlarıdır. Kullanıcılar render'lar arasında kendi sahnelerini ayarladı ve karşılaştırma node'dan node'adır — bare-metal 5090 ile sanallaştırılmış önceki nesil node'lara karşı — dolayısıyla farkın bir kısmı kurulum farklılığından kaynaklanmaktadır, silikondan değil. Taban, mevcut bir RTX 4090 değil, RTX 3080/2080 sınıfı donanımdır.
Q: Üretim sahneleri gerçekte ne kadar VRAM kullandı? A: 57 kayıtlı Cycles işi boyunca, pik render cihazı belleği medyanda yaklaşık 5.6 GB, 90. yüzdelikte ise 11.5 GB'tı. En ağır tek iş yaklaşık 37 GB logladı — 5090'ın kendi 32 GB'ının ötesinde — bu da GPU'da CPU fallback'i ya da hiç render edilememesi anlamına gelir. VRAM'i medyana değil, uç değere göre boyutlandırın.
Q: RTX 5090, AI denoising kullanım sıklığını değiştirdi mi? A: Hayır. Cycles işlerinin yaklaşık %83'ü 5090 node'unda bir AI denoising geçişi çalıştırdı (OptiX veya Intel Open Image Denoise) — ve oran önceki nesilde özünde aynıydı. AI denoising zaten standartlaşmıştı; yeni kart yalnızca etrafındaki her şeyin hızını değiştirdi.
Q: Sürücü yedi hafta boyunca ne kadar kararlı kaldı? A: Tek bir sürücü — CUDA 13.0 üzerinde 581.80 — tüm 51 günlük pencere boyunca sıfır değişimle çalıştı: geri alma yok, pencere ortasında takas yok. Üretim kuyruğunda erken dönem donanım için bu kararlılık tek başına anlamlı bir sonuçtur.
Q: Yük altında güç tüketimi ve sıcaklık nasıldı? A: Sürekli yük altındaki kontrollü test çalıştırmasında her kart yaklaşık 360–375 W çekti, ~400 W'a kadar çıktı ve 68–83 °C'de çalıştı — kartın ~575 W'lık anma sınıfının rahatlıkla altında. Kare başına enerji, bu test ölçümünden türetilen yaklaşık 2.5 Wh olarak hesaplanmaktadır ve yalnızca 5090 için geçerlidir.
Q: Bu rakamlar diğer render motorları için de geçerli mi? A: Hayır. Bu çalışma yalnızca tek bir node'da Blender Cycles GPU içindir. Diğer motorlar denoising, bellek ve zamanlama verilerini farklı biçimde loglar. Bunları Cycles'a özgü saha notları olarak değerlendirin, çiftlik geneli veya çapraz motor iddiası olarak değil.
About Richard Ta
Richard Ta is co-founder and technical lead of Super Renders Farm (superrendersfarm.com), a fully managed cloud render farm that supports Maya, 3ds Max, Cinema 4D, Blender, and Houdini across the major render engines. He has spent over a decade building and running large-scale CPU and GPU render infrastructure for studios in more than 50 countries.



